In revisiting some of the posts the thread about pre-processing for NMF, I came across the filter comparisons between pre bug-fix @filterupdate 1.
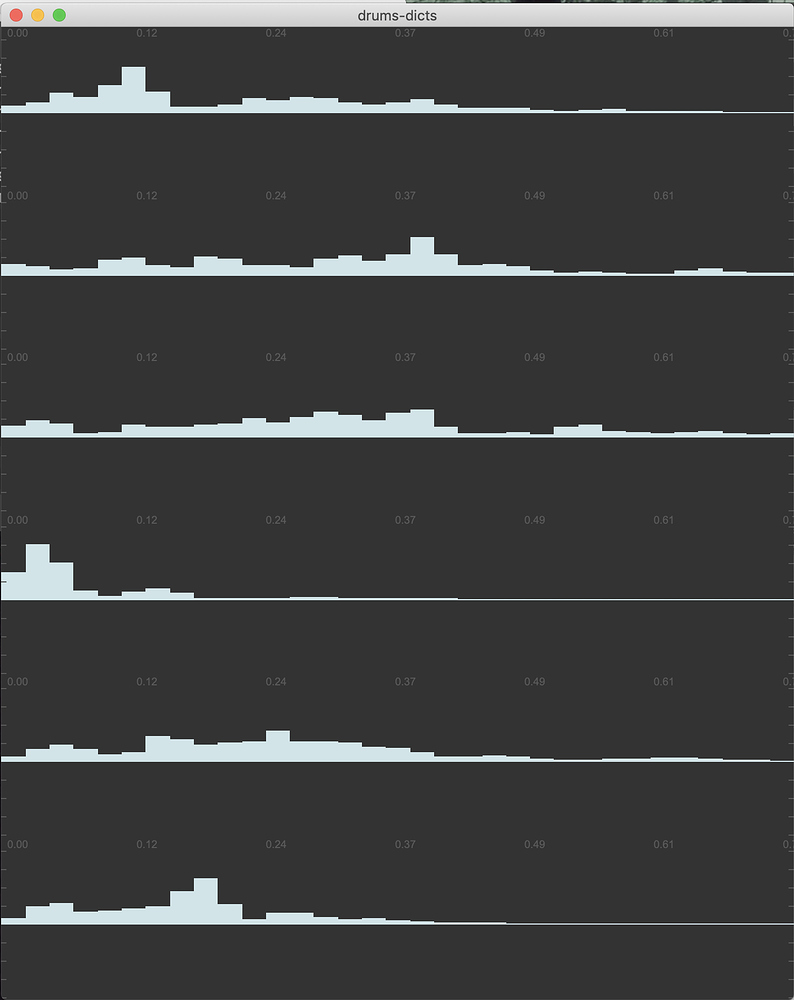
These are the raw filter dicts that were created from training multiple hits:
And then these are the ones from when I ran the process again on a pre-seed dict with @filterupdate 1:
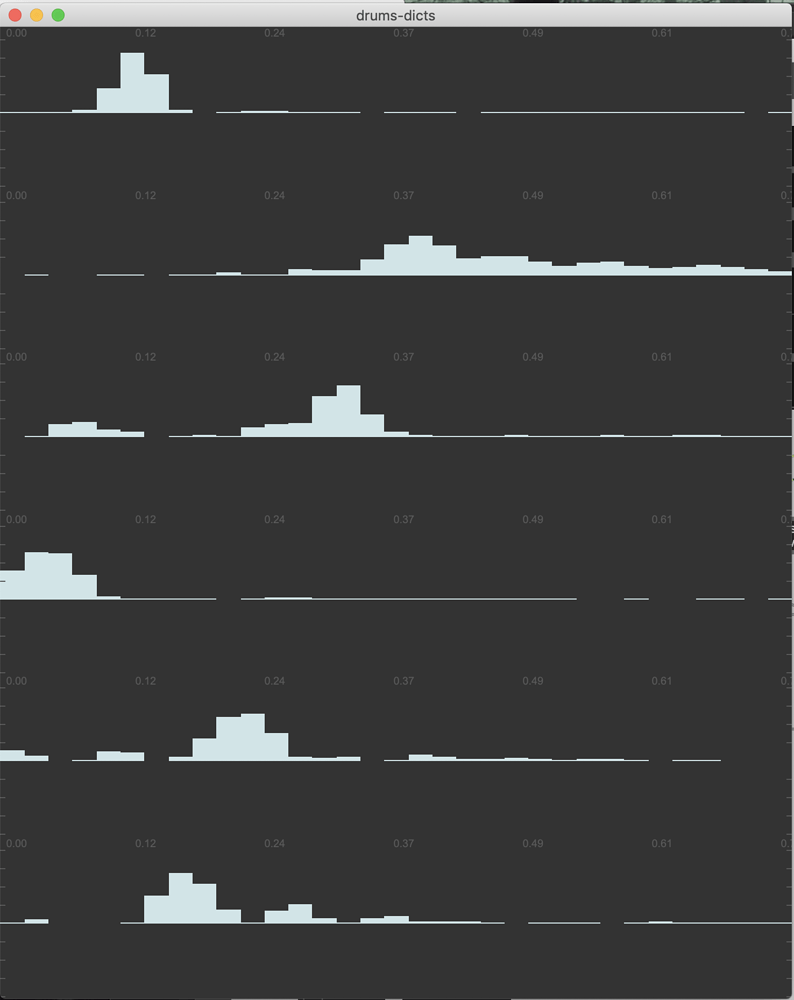
The difference is pretty huge.
I’m wondering if something like this can be incorporated into how you are creating the initial dicts. Since you updating each hit as you update it, you never run it on a pre-seed bit of performance audio. I get really confused with this side of things as the averaging/normalising/pre-seeding gets very close to voodoo for me.
Do you think that would be useful?