ah ha! I downloaded the patch and you did not do what I suggested
I meant everything - now you do the analysis at one SR and the filter at the other.
In other words, put your recorder, buffer, everything in the downsampler. It should work.
now the explanation: all the fluid* stuff is in sample for that reason: it is as far as possible sample rate agnostic. So if you run you 512 FFT at 44100, you get 86Hz per bin. If you run your FFT at 512 in a 32x DS, so at 1,378.125 Hz, your bin are now 2.7Hz apart for the same CPU usage (almost: there is a cost to down and up sampling)
does it make sense and/or help?
so your next downsampling homework would be, before trying our stuff, do to a recorder/player of CV in a poly downsampler. Be daring and downsample as low as it gets (probably the SVS (64 I reckon), but again this is a good place to test it)
I didn’t think it mattered how it was recorded since that was being downsampled as it happened (writing only the samples that were relevant to a buffer~).
Here is one with everything inside a poly~.
The problem is the same. So something isn’t working correctly with fluid.nmffilter~ downsampled and/or poly~ bug in general. Once you create a gesture buffer and try to output stuff, it lags, then you may see a bit of activity, then it stops again.
In addition to the internal downsampled poly~ input to the fluid.nmffilter~, there is an external one to make sure the poly~ is working correctly and passing audio/data.
That more-or-less makes sense, but what I was more asking was in terms of how the nmf algorithm responds to slow changes in material over time.
So if my default FFT settings are 4096 256 4096 and I’m downsampling that 32x to get the nmf algorithm to do gesture/event segmentation, is it possible to set FFT settings that work “properly” at 44.1k (32 x 4096?!). Would that even work as intended with nmf?
As in, rather than downsampling the data, instead, “upsampling” the FFT.
From much earlier in the thread:
So the downsampling was an attempt to get gesture separation on CV, which works well for buffer-based material, but doesn’t appear to be working for real-time use.
then you will get the latency to be expected with your WAY TOO HIGH fft settings: you are downsampling so in effect it takes 32 times longer to fill your fft! the whole point of downsampling is to keep the fft low! You will not get it with less latency for the same spectral precision, you will just save a lot of CPU. Then you might want to make the hop super small…
if you want 0.5 Hz precision, you’d need to use 2048 and 32 down, which is equivalent to run the fft at 65k at 44100 - I get the expected latency (a bit more than one second) with @fftsettings 1024 64 2048 and a good separation of DC
I think we’re talking about two things now actually.
The fluid.bufnmf~ has been working perfectly with the downsampled stuff for a few versions of the patch posted in the thread. Where the problems come in is the real-time output of fluid.nmffilter~ when set with the @bases produced by fluid.bufnmf~.
So here is the main bit of the patch, operating inside the 32x downsampled poly~:
Now you can’t tell since this is a screenshot, but the output of fluid.nmffilter~ is frozen. It seems to tick over once every 30s or something like that.
You can see the “through” output is working perfectly, and is quite steppy because of the 32x DS.
if you ds by 32, it means it takes you 3seconds to fill the fft buffer of 4096. this is why you have (like I do here) 3 seconds of latency.
the whole point of ds is to run smaller fft inside, and save CPU cost.
There is no way you can do a spectral processing on 0.5 Hz without sampling large - at that speed. This is the fundamental of FFT theory and sampling theory together. You cannot identify something larger than your window…
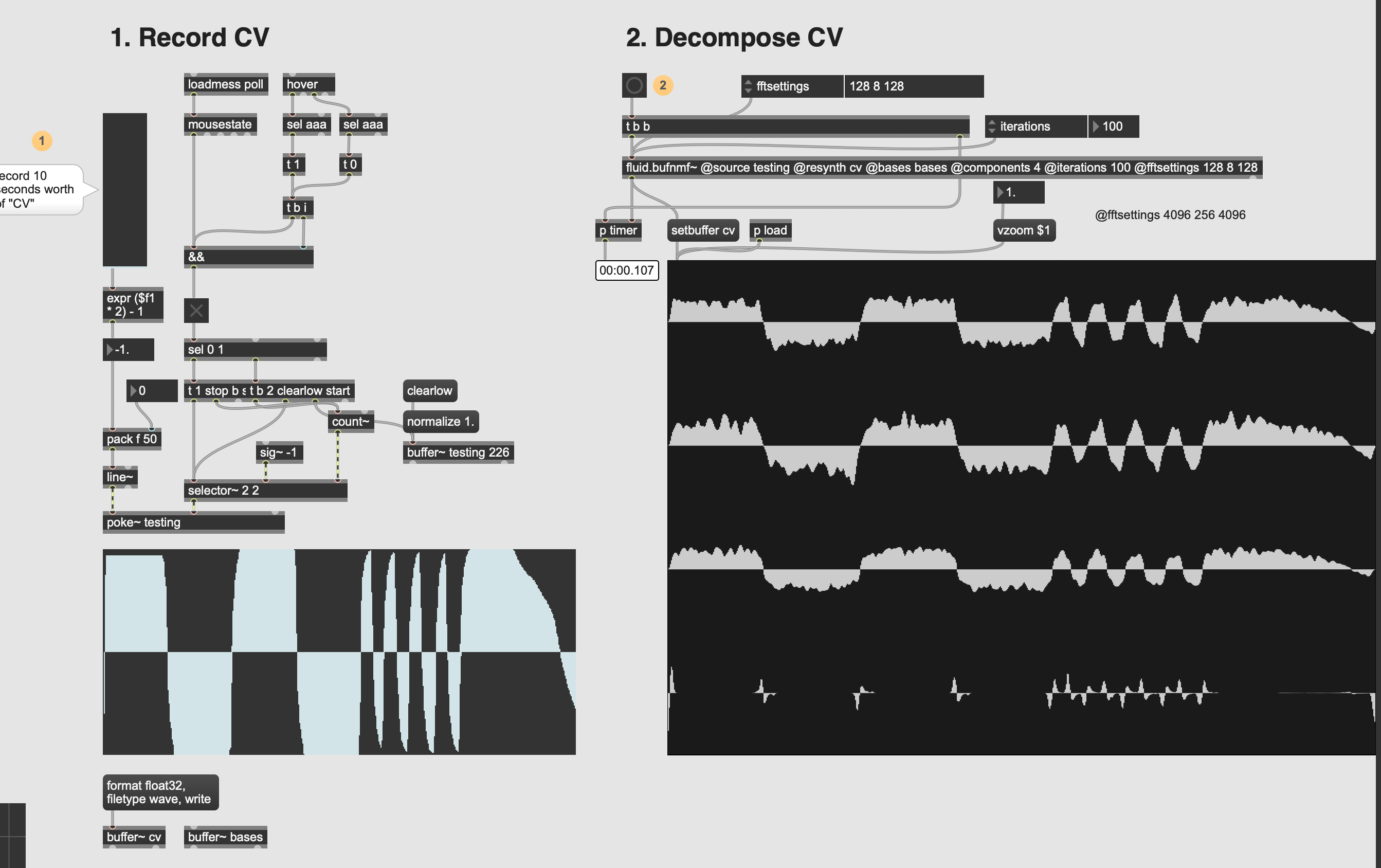
I tried with much smaller fft sizes (@fftsettings 128 8 128) and that works well in terms of latency, but we’re back to square one with regards to gesture separation:
So I understand that you can’t process something bigger than the fft size, since it doesn’t “exist”. But I get lost with the other stuff.
If @fftsettings 4096 256 4096 work well for fluid.bufnmf~ at 32x downsampling, in terms of decomposition, but is too slow (3s) for real-time use. Is it just a matter of finding the middle ground there?
Or can I do something where I decompose at one fft size, and then fluid.bufcompose~ a downsampled @bases buffer to feed into fluid.nmffilter~? Or would that not work?
you are always stuck with the same problem: if you are trying to take a picture of a mountain, you need to be at a certain distance…
yes. but if you aim only for speed, you won’t get anything. Downsampling is only helpful to reduce CPU as you need smaller FFT to get the same (low end) detail. What you lose by DS is high end… the same way and reason why you use UpSampling for your distortions you love so much: you gain (and lose) nothing in the low end but you extend the top’s limit.