Becoming steadily more convinced that the problem is either packet loss or something language side with incoming messages. This reliably fails to make it all the way through on my machine (debug builds), using the local server:
(
s = Server.default;
s.waitForBoot({
b = Buffer.alloc(s,100,1);
c = Buffer.alloc(s,1,100);
});
)
(
fork{
var count = 5000;
var cond = Condition.new;
count.do{
FluidBufFlatten.process(s,b,c,action:{
fork{
count = count - 1;
count.postln;
if(count === 0) {cond.unhang};
}
});
};
cond.hang;
"Made it".postln;
}
)
If I use a non-stopping break point in our scsynth code to log the number of responses that are being sent back to the client, then I can see all the jobs run and send a response back. Furthermore, the above does seem to work reliably for me using the internal server.
The RT Mem leak doesn’t seem like it should have any bearing on this particular problem, but there could be more than one problem of course. There’s a fresh commit finishing the job I started with the memory leak patch, which you’d need to pull.
scsynth is crashing, or the action just isn’t firing? If the former, a crash report would be very useful. If the latter then there are two possible things I know of:
Under heavy traffic, which FluidProcessSlices can generate, packets seem to get dropped.
The obvious workaround to this (for one-off batch processing at least) is to use the internal server. However, there’s a bug (fixed locally) with clearing old variables when the internal server gets rebooted and you need to restart the interpreter as well, because (frankly) the implementation of that is a bit shonky, IMO. There’s also a SC bug where rebooting the internal server at any point in a session will cause the interpreter to crash when it restarts (which is just irritating, rather than awful).
If you or @spluta have good tips for how to sensibly throttle outgoing traffic from the language, I’d value them. There doesn’t seem to be a robust approach that I’ve found.
There’s also a problem that actions can get lost, especially with asynchronous stuff. Basically, we need a queue inside the Fluid objects, rather than the simplistic rip-off of Buffer’s action management that I did. So, if you’re sure it’s not packet loss, then it might be this.
I don’t know if it is or is not packet dropping. Would it be helpful to use OSCFunc.trace to post all the messages coming into the language (to see if said packet ever actually arrives)? I don’t know if sclang has something similar for outgoing messages.
Or perhaps registering a different app (Python script) with scsynth to receive, in a different place, all outgoing OSC from the server? (I believe that @spluta has done this with his Keras stuff?)
Yes, I’ll try again right now with the internal server… although per @spluta’s comment above (
The rate of outgoing OSC messages from the language to the server. But, actually, I think this is just a band-aid, if the packet drops are occurring from the server to the language (which is my recollection).
We definitely established that this could happen on the previous visit to this topic. trace and Server#dumpOSC are good friends of mine already, but I was also able to spy on the scsynth OSC queue and see that stuff was getting that far ok, but never making it to the language.
I suspect that this might happen if two threaded jobs complete almost simultaneously. In which case the unhappy conclusion is that we probably need our own scheduler queue on the server to manage the flow of traffic, which is no small thing.
The internal server seems to be in a shaky state at least. My impression is that the SC devs have their hands pretty full at the moment. So, I can file an issue for what I think the problem is with rebooting the internal server, but I don’t have much hope that it would be resolved quickly, because it’s threading related and therefore harder to reason about causes and fixes. (For the geeky reader: my guess is that the problem is caused by the thread running the internal server being detached after it’s been launched; detaching threads in production code is generally a Bad Idea as undefined behaviour is pretty much guaranteed further down the line because shared resources can no longer be freed up in a reliable way.)
As a general fix for this when using the local server over UDP, I’m a bit stumped, tbh. It’s built in to UDP that packet loss is a possibility, so for stuff that relies reliable OSC messaging for flow control, TCP or internal would always be more reliable. That said, maybe a (non-ideal) workaround would at least to give the option of spacing out taks with a wait (but, per above, it’s not directly addressing the issue if the tasks are being run in a separate thread on the server).
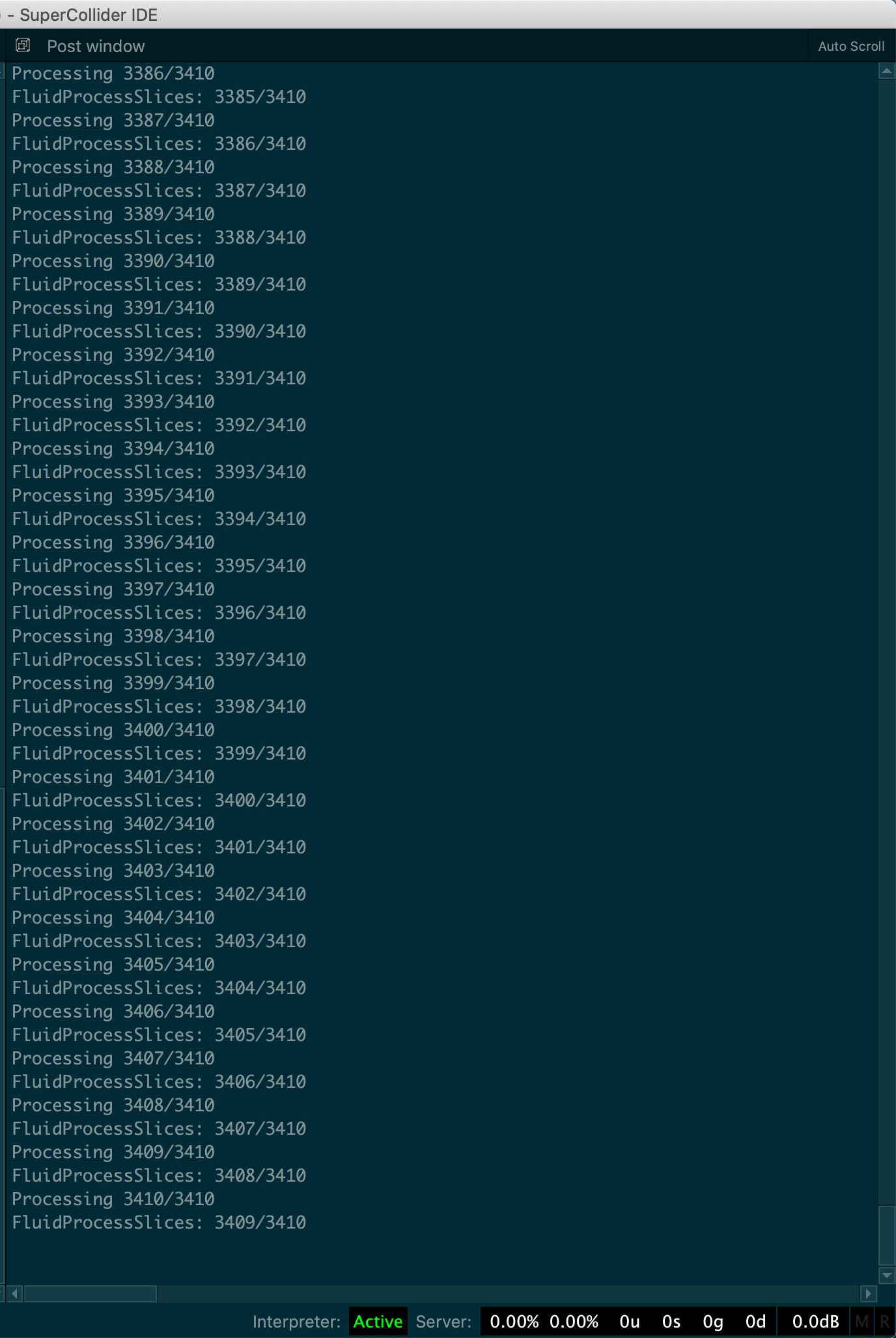
Uh oh. Internal Server just didn’t work for me now. The first time (when it worked) I had 1135 slices. This time (when it didn’t work) I had 3410.
Here’s my post window. You can see that it’s not a crash. The “server bar” is white because this was running on the internal server. It posts “Processing 3410/3410” but never posts “FluidProcessSlices: 3409/3410”
there are also examples with processblocking to get them to work all the time earlier in the thread in the meantime… I’m also on leave but just until Monday - if the massive parallel patch is not to be found I can repost here if that helps.
 Yes, we should wait for after that!
Yes, we should wait for after that!