Doesn’t it expect two lists, frequencies and magnitudes? If you use it with melbands do you have to spoof a list of gains you want to keep, or just dump the same list into both?
Even if something like that would be the case, it still seems like it would be a sines-specific voice allocator, that has uses in other things. Either that, or making the inlets and future documentation a bit more generic in terms of how it works and what it receives.
edit:
To make clearer what I mean, given that there is a native mc.voiceallocator~ object, finding out that there is a fluid.voiceallocator~ object would immediately make me think that it is for using fluid. objects with mc. objects and/or that it worked and operated the same way.
Whereas a name like fluid.sinevoiceallocator~ would make it’s functionality, and more specifically, scope more clear. And again, that it isn’t related to mc. objects at all.
it is more a freq-amp-voice-tracking-and-allocator - I’ll think about confused mc users indeed (good call on that thanks)- at the moment I’m even doubting the split is right (i.e. track and voice in one object) so I’ll wait to port to Pd and SC and see how these other communities connect with it too.
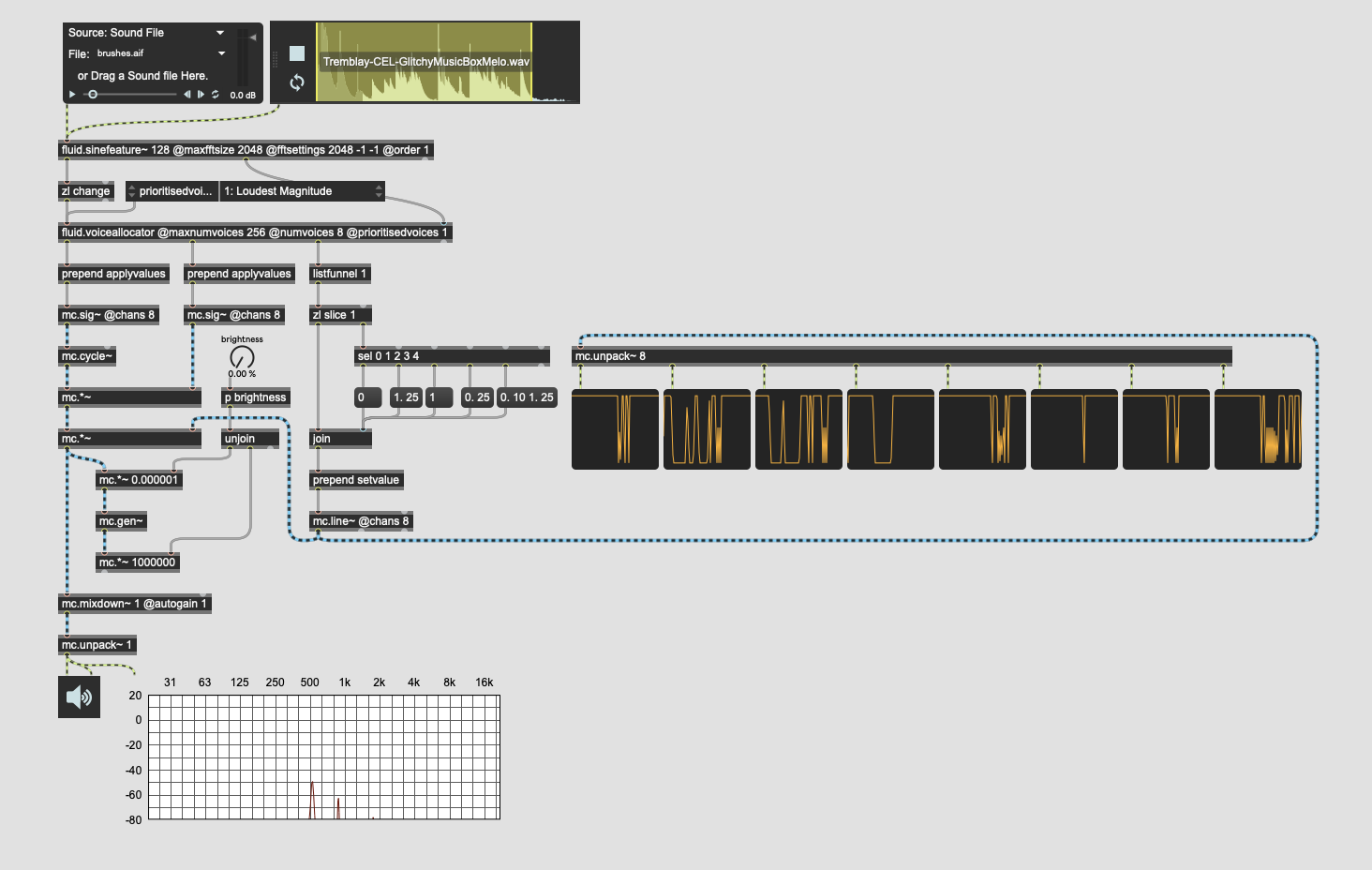
Ok, took a stab and trying to make this today and not entirely sure why it’s not working. There’s probably a more direct/elegant way to handle the voice fading in/out, but I tried copying the same structure using mc.line~ and setvalue to address each individual instance, but getting no joy from it.
Ok, improved it some. It still isn’t sounding 100% the same (lots of clicks and stuff when using low/chunky sounds), but it’s at least doing something in the ballpark of what it should.
Turns out I needed to account for every output, including 0 and 2 which are just left alone in the poly~ version. I’ve tried experimenting with voice state 0 being a 0 and a 1 and neither seems to work right.
Yeah I had no luck using the voice inputs. It also didn’t really make sense to me to have to use them if you had the amplitude anyway, but my understanding of why you would need the voice information for just making some sines match the freq and magnitude is in tatters
I guess the amplitude outputs are limited by the hop rate, so they couldn’t do the fast fade in/out/dip thing the state bit does, otherwise that would be an ideal solution since it cuts out “the middle man”.
Trying to think of a better way of doing the fades as well, like an mc.slide~ or something. This is easy enough for the ‘fade to in 25ms’ states, but not sure how to do ‘instant zero then fade to 1 in 25’ with a similarly set up mc.slide~.
The voice states are:
0 - free
1 - attack
2 - sustain
3 - release
4 - steal
With 1/3/4 being “trigger” ones:
Voice states 1, 3 & 4 are only ever sent once per event, immediately falling to 0 or 2, and can be used as a trigger.
From the looks of the poly~ that basically means states 0/2 are “ignored”, with the version I’ve built in mc. sending a 0 for state 0 and a 1 for state 2. That seems to work right, but I’m still getting some clicks happening.
The reason for adding the 0 and 1 for states 0 and 2 respectively is because otherwise join kept spamming the last received message, so I can try and restructure that part so it actually “ignores” states 0 and 2 altogether as well.
Just trying to wrap my head around what should be happening.
a track just started at 1 - that will never be longer than one frame and should be followed by one of the other greater numbered state
this means that the previous frame was on (either 1, 3 or 4)
this means that the voice is now off and should be dealt with as dying - it’ll be followed by 0 if there are spare voices, or by 1 if it is reallocated
this means that we ran out of voices so a voice went straight from 1 or 2 to a new state which is not respecting the track conditions of min jumps in mag or in freq (so a special behaviour can be done for a large jump which is flagged here)
That’s useful as a clearer version from the patch. But that’s more a description of what the states are.
As in, in state 0 what should happen? It should be at zero gain I assume?
So:
be at a gain of 0
fade up from zero (in 25ms in the example case)
be at a gain of 1
fade out to zero (25ms)
fade down to zero (10ms) and fade back up to 1 (25ms)
A follow up question for state 4. Does the fade down take into account when it sends the new freq/gain numbers?
As in on any give frame, when state4 is sent out, did the freq/gain being sent out with it correspond to new values already? (meaning that the 10ms fade out will happen after the voice has already changed)
Or does it send state4 a frame ahead of time (or something like that) so that the next freq/gain pair will be the new voice, therefore allowing you time to fade out the current voice?
it really depends, as usual. hence that interface…
that voice is dead, so the data in the same position in the other output is the last valid but not updated. that can be useful or not.
trigger an attack sound? random playback? put the lights on? you just know that this is fresh. chose what you want.
this is a continuation within the constraints of track allocations. so smooth the new data or something. pitch gliss. mag slide. the other outputs (freq/mag) follow the previous frame’s values within the constraint and you decide how you want to deal with that. slides is the conservative choice.
fade out in the length is the conservative choice again. but a trigger of a new synth and lights and fumes on the 73rd finished note is also an option. you just know that this voice might be reassigned and you must deal with it.
this is the crazy one. indeed your proposal is the conservative sampler option of a deck voice (quick dip to avoid freq jumps usually) but again that can trigger many things. you just know that, by oppostion to 2, this is a new stuff/big jump/unrelated to the material in the same track in
the previous frame.
That’s quite useful in a more general purpose sense too.
I don’t see how that would be applied if you always have to give it a list of frequencies and gains, but I guess what you’re describing is that there would always be freq/gain inputs, and you can then choose to do whatever based on how the voice allocation works.
///////////////////////////////////////////////////// thinking out loud /////////////////////////////////////////////////////
For a second I was trying to think of a more generic interface where it only takes a single list as input (laced or delaced but always an even number of two lists) then it does all the voice allocation based on the input (either on one or more lists) then spits out the data in the same format it got.
So if you send it only a list of freqs, it will do voice allocation magic on it to keep them close/similar/whatever it’s doing and spit out the freqs in the order you specify.
If you send it only a list of gains, it would do the same.
If you send it a list of normalized floats between 0. and 1. it would do the same within the range etc…
So it could be more input-agnostic, while still doing whatever secret sauce it’s doing, and if you send it the output of fluid.sines~ (laced or delaced/whatever) it would operate as it presently does.
///////////////////////////////////////////////////// thinking out loud /////////////////////////////////////////////////////
Does does this currently send the “duck” ON the frame that is to be ducked or BEFORE the frame that is to be ducked.
As in, when state 4 is received, should the current example fade out at all, or should it immediately drop to zero and then fade in. (speaking in terms of the current example in the documentation)
From what you’re describing I would think it’s the later, with the fade out in the 0. 10 1. 25 happening “too late” since the voice would already have been reallocated.
Exciting object! If I understand correctly it is for reducing the output of fluid.sinefeature~ to a lower dimensionality with the additional reporting on how the content changes over time – right?.. So the difference between a fluid.sinefeature~ 8 and a fluid.sinefeature~ 128 --> fluid.voiceallocator @numvoices 8 is that with the latter we not only get the frequencies and magnitudes streams, but also the report on how the tracking has been changing?
In that case, could it also be a good idea to include the same tracking algo + the 3rd output stream inside fluid.sinefeature~ as well? (Could be especially nice for fluid.bufsinefeature~ for offline stuff?)
As I understand a 4 is like a 1 when it is not preceeded by a 0. So, if you interpret this as the frame to “duck” on, then you duck on the first frame of the new track. If you want to duck the last frame of the previous track, you have to set up a 1-frame delay, I guess.
Do I understand correctly that a 3 is the first frame of being 0? (And not the last frame of being 2, right?)
What does @trackprob mean? Like, when it detects an event to start a new track, it will have the probability of @trackprob to actually start tracking and 1 - @trackprob to just ignore it?
I made a quick’n’dirty visualization by stacking multisliders, but I am thinking of a more elegant solution… I think a visual aid could help people form an intuition about the parameter values.
I imagine there’s some “extra stuff” going on here in the voice allocation so it fluid.sinefeature~ 8 would be different from fluid.sinefeature~ 128 --> fluid.voiceallocator @numvoices 8, otherwise why have it be a separate object at all.
This is what I think, but in the example poly there is a fade down that happens after a new voice has been assigned. Rather than instantly jumping to 0 and then fading the new voice up.
To simply I’ll use some MIDI range values for a single voice, presuming three columns of data (freq, velocity, state):
64 127 1
62 100 4
So there’s a note, then a new pitch comes in “steal”-ing that voice and becomes a new quieter pitch.
With the poly the way it is it’s doing this:
(already at 100% gain)
64 127
62 100
(start fading out NOW after the new note has started)
I would think that sonically it would be better to do something like this:
(already at 100% gain)
64 127
(start fading out NOW before the new note has started)
62 100
But that would require manually adding a (multiple) frame delay, or having the object report the changes in that order.
This is super useful, if for nothing else than trying to hunt down extra blips/boops.
yes but you can trick it - you can just give steady amps for instance so you only track by pitch.
there are many other uses one can think of. If I was not crazy busy on my workday job, and then all my other time doing intern supervision as hobby on the other many things, I would make more examples. this will be for the autumn…
so now, 2 things:
continue playing or not, but please do not expect support more than this level of terse explanations.
or
we can stop the experiment and I go back to trying objects by myself for 6 months before giving it to alpha testers - until I’ve done many patches like in the good old days.
I’m saying that because the other bundle of objects that is cooking has a lot more stuff so I am now afraid
that is a possibility. or if you ask for 10 sines, or 10 random pitches, or 10 formants, or whatever 10 combinations of freq and/or mag, you can get them to track. if you have 5 voices, it will prioritise the way you ask. if you have 50 voices, it will pile up and do voice management in an elegant manner. and everything in between!
[quote=“balintlaczko, post:33, topic:2085”]
In that case, could it also be a good idea to include the same tracking algo + the 3rd output stream inside fluid.sinefeature~ as well?[/quote]
nah. it is made to deconstruct the algo, not to bloat stuff with redundancies… but…
there will be in the next months a buf version of voice allocator which can take the buffer of bufsinefeatures or any other source. in the meantime, js can iterate lists faster than realtime those buffers for you to use the in-line one if you want to see.
yes, it is a special 1 that was not preceeded by 0.
that is a fantastic avenue indeed. maybe with 4 voices so we can follow but yes. @fearne you’ll like that I think
If comments aren’t useful I can definitely hold off.
I would, personally, prefer pointing at potential interface things to highlight things that may come up later on to avoid fully baking in an interface that will prove to be problematic later out in other (non-PA) use cases (cough managing/creating your own buffers…).
For example:
Doesn’t seem like a great interface decision. Having to spoof or fake data/inputs in order to use something.
as long as the feedback provider remembers n=1 then yes… divergent uses, attempt to own the current interface instead of imposing another one (since work has been done there so previous n is > than just me) general shared enthusiasm for the hundred of hours behind the early release… discussions, questions, pokings.
but again, if the object is useless, it might just be shelved so yes, feedback, but maybe not phrased as demands?
creating you own buffer is not just me - try teaching this, and you’ll see that they are needed. after more than 50 of those, I can tell you, and so can tell. the automagic stuff is advanced and abstract…
so voice your ideas and patches and roadblocks and we’ll see. and I will most probably park the next series of object until I have made more examples so the (as usual very carefully thought of) interface decisions are not dismissed as 'p.a.‘s taste’