The discussion in the fluid.transients~ thread was starting to veer quite off topic, and into an area that could probably benefit from its own thread and discussion, so making a new one here.
Starting from my post/prompt of:
This is a bit OT, but there’s been a bit of mention in a couple of threads now about where the generalizability of some of the algorithms break down and/or how often “real world” applications do some kind of contextually appropriate pre-seeding and/or algorithm tweaking. Is that level of specialization and/or fine-tuning in the plans/cards for future FluCoMa stuff?
Like, architecturally speaking, some of the stuff discussed in the thread around realtime NMF matching(and semi-reworking the concept from the machine learning drum trigger thing) just isn’t possible in the
fluid.verse~because there is no step that allows a pre-training/pre-seeding of an expected material to then optimize towards.It’s great that all the algorithms work on a variety of materials, but form a user point of view, if they don’t do a specific type of material well , the overall range doesn’t really help or matter.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
That’s good to hear, as I’ve kind of placed that hope in the “not gonna happen” part of my brain based on various discussions on here and in the plenaries where the “tools would be made available” and anything else “we could code ourselves”.
Pre-seeding, yes. And I did make use of that, but I guess I meant more of some of the stuff discussed in this thread, namely the “Neural network trained on pre-labeled data” step in the graph below.
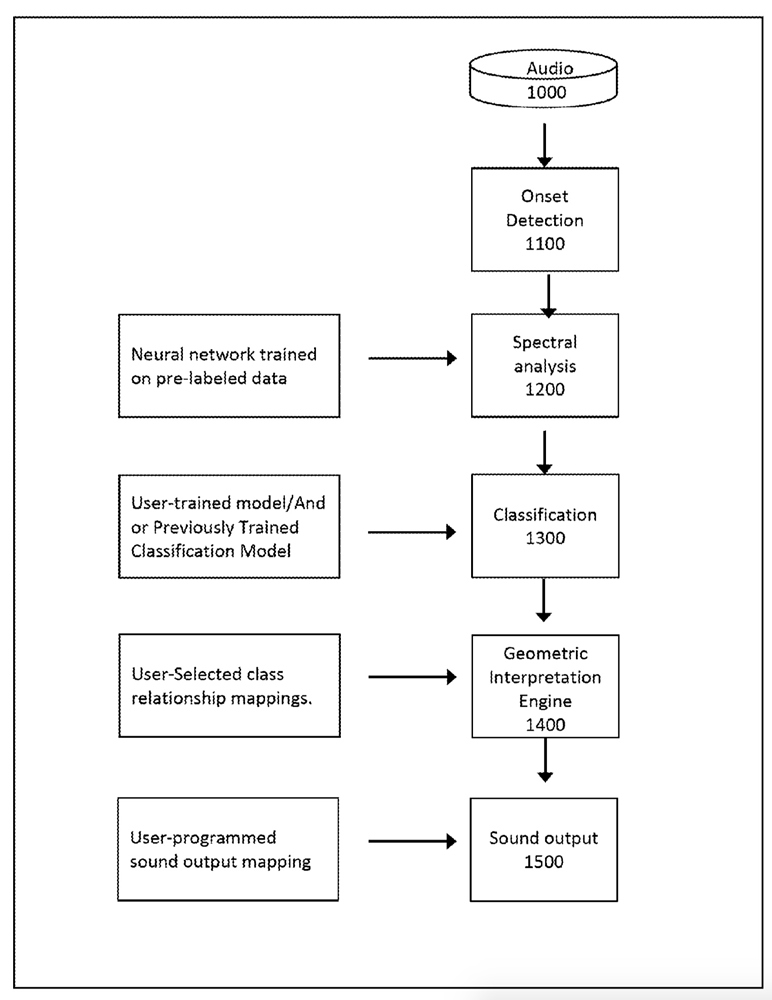
That’s just one example that I know, and I certainly know enough to know that I don’t know much. But it always seems to come down to some secret sauce variation and/or implementation that isn’t a vanilla take on an algorithm, that makes something work particularly well. (which often takes into account certain assumptions about the material it will be used on)
Maybe some of these thoughts/concerns can end up in a KE category along the lines of what @tutschku suggested in the last plenary, where there are specific settings/examples/approaches that suit certain types of materials, and are presented as such. Which “somewhat” differs from the “here are the 30 parameters that you can play with, they are all intertwined and do very subtle things…have fun!” approach that most of the objects are designed around.
So it’s not a matter of making every parameter available (which isn’t always useful in and of itself (i.e. the still enigmatic fluid.ampslice~)), but rather whole approaches which aren’t (yet) available with the “general purpose” tools/algorithms.
AND
I could just be uninformed/wrong about some of my thinking here. Which even if that is the case, given my level of engagement on here, means somethings aren’t coming across as well as it could.