i have some questions concerning MLPRegressor, and training,
following the tutorials and using the proposed function
(found here MLPReg doc: Making Predicitons on the Server (Predicting Frequency Modulation parameters from MFCC analyses))
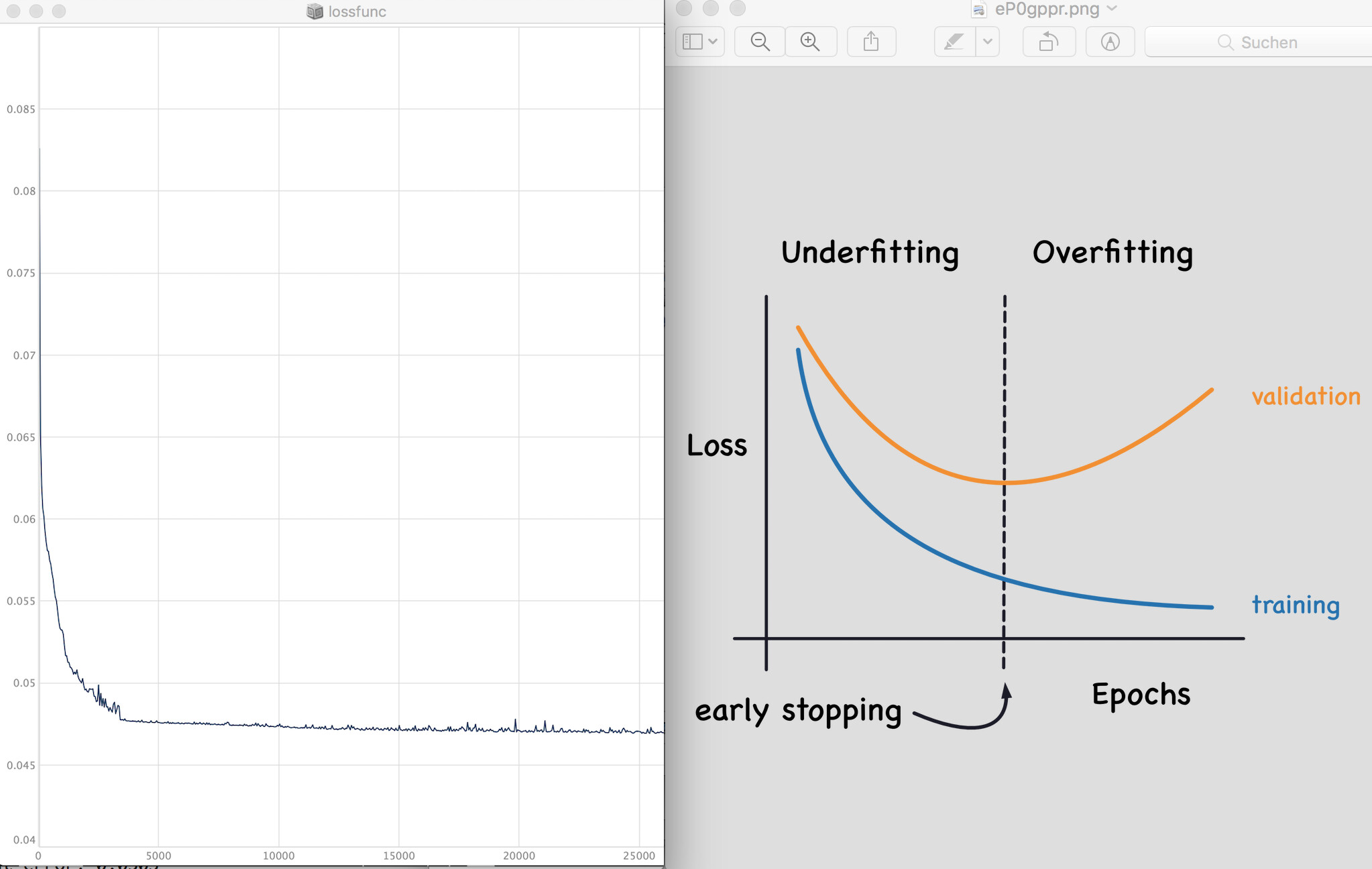
it outputs the “error” for each fit (training loss), all fine! looks like it should i think.
you see it was training many hours (and not stopping; this makes no sense but i tried to get it to stop), so it has (very likelyy) overfitted,
[1] my q now is:
is there a way to also get the validation loss? to find the point to stop?
(like eg in Tensorboard)
[2] the docs say: validation_ “If it is found to be no longer improving, training will stop, even if a fit has not reached its `maxIter number of epochs.”
does “no longer improving” refer to the training loss? (it smoothes out and stops cause of no improv.) or does it refer to the validation loss? (when val loss goes up, overfitting starts… then it stops), so “early stopping” is built in and i dont need to plot validation loss…)
It refers to the validation loss so – in principle – you shouldn’t need to track that, and the object should stop early at a useful point.
I would like to develop some better testing and validation tools so that models can be more rigorously compared and evaluated etc. but haven’t yet really figured out what would be a musician-friendly interface (see Removing outliers while creating classifiers - #11 by weefuzzy for the start of a discussion about that)
thank you very much @weefuzzy for the fast answer and the topic link,
this makes sense!
i think it would be helpful to have the possibility to also get the validation loss value for each batch (and plot it) to have an impression how things go…
if it is not stopping (like mine now) there is as far as i can see no way to (“meaningful”) stop it but by instinct (or ear while using the model, well, other problems start here),
plotting the val-loss would give a small bit more of information to find a good fit (or further tune hyperparams by hand… and compare plots)
i split my datasets (in and out) to train and test splits (in a %ratio),
then i calculate the MSE from predictions of the model and ground-truths from the out-test-set and plot it.
using .predictPoint and .getPoint in a looped routine was my first guess but its a bit messy and not very solid…
in the file attached some problems of this approach are tried to bring to your attention -
i hope there is a more reliable way, for now this works for me somehow,
the model will perform next week at a concert, so - well- it is what it is at the moment…
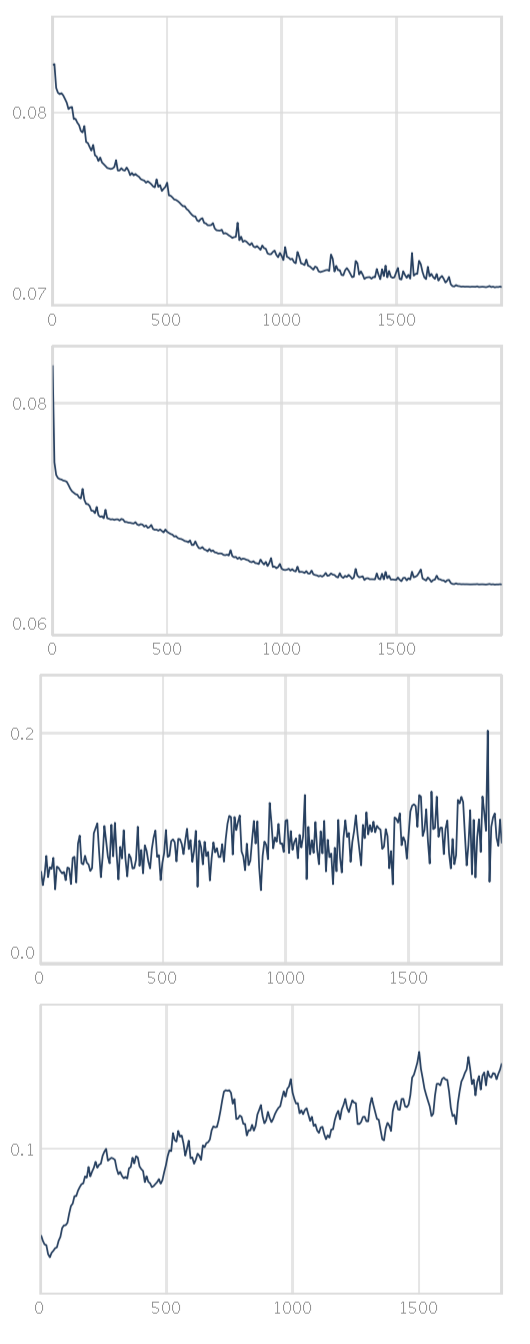
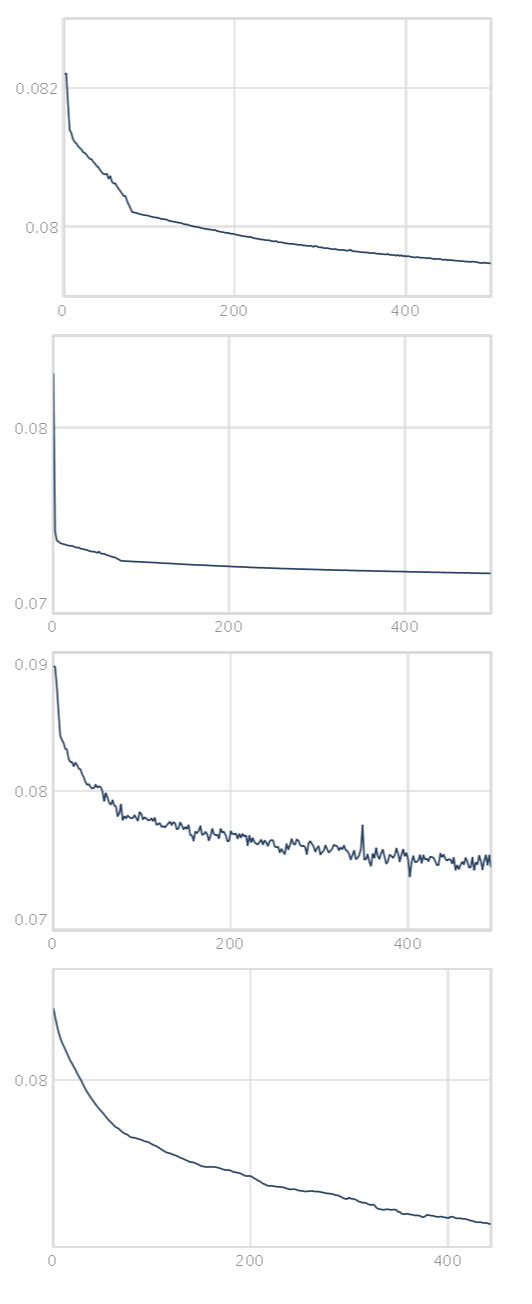
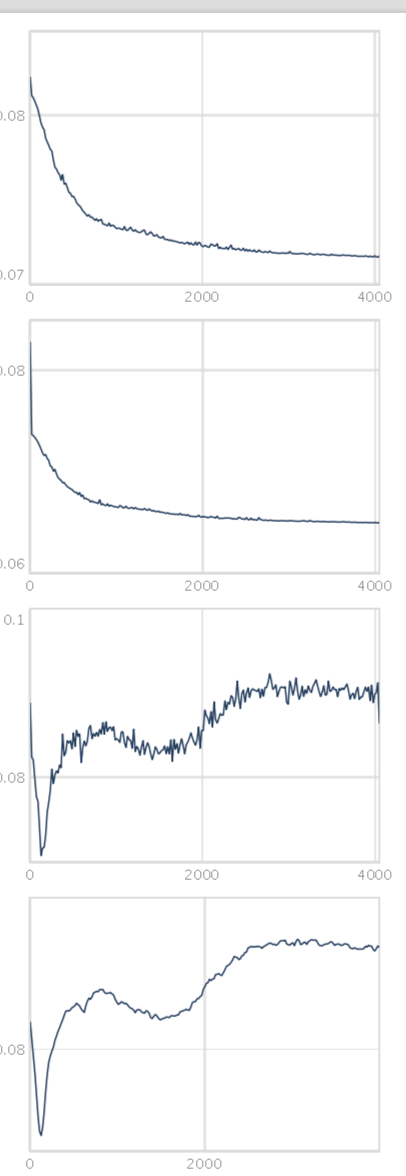
the output shows training loss / training loss (exp moving avg) / test loss / test loss (moving avg)
the model trains ok i think but cannot really deal with the dataset
(which is part of the idea somehow…) and the test loss is very noisy
thats the reason why it never stops training i guess.
i am very grateful for any comments (on clumsy things and errors…)
and maybe other directions of implementing it in flucoma world!
thank you
I like the way you’ve put this together. I’ve only poked at the code a bit. I will more this week.
Yes, it looks like your training loss keeps going down and your testing loss keeps going up! Of course this is classic overfitting. With these small datasets and our musically-oriented goals sometimes this isn’t really a problem, it all matters how it sounds!
Thanks for sharing this and for putting together a nice testing validation loop!
thanks ted,
it somehow does what i expect it to do for this one…
but digging a bit deeper and trying other things i just read that shuffling the test-dataset for each batch (what i did) is not necessary (or a mistake even… is this so? i was quite certain that it should be shuffled, cant find the read now fast…)
(in the ~validation function, changing one line:
var batchIds = ~testIds[…batchsize-1]; //same each batch (rand only once)
//var batchIds = ~testIds.scramble[…batchsize-1]; //every test-batch rand data pts
Hello @doett and thanks for this fantastic patch! I am doing a few tests now while I reply…
First a few optimisation ideas: you can run predict instead of predictPoint to run your tests in one go (although the randomisation might become tedious) then tobuffer to export… also, to get rid of your sync problems, you can use a Condition to wait instead of timers in your Routine.
I didn’t change those, I was too eager to go to the results (or lack of stopping)… I only replaced the mlp validation size to the same percentage (~split) to make sure we compare the same thing. Or maybe I don’t understand what you are trying to do…
I’ll let your patch run for one hour since at the moment I haven’t got anything else than noise in my validation - I’m reading the implementation code too to check there too.
so, the algo is waiting for 10 batches in a row of the validation error to be going up.
I think we would need to do your tests with an numIter=1 so that way we can see the internal value then. I might compile with a printout just to follow if it actually stops, which I’m 99.99999 it does… but hey, life is full of surprises
(if you are interested, the code to read is relatively English (as it uses a lot of Eigen and good variable name discipline, thanks to @groma and @weefuzzy)
hi @tremblap, thank you for the optimisation ideas, i will try this! makes sense…
to avoid the noise in the test loss graph you could set
var batchIds = ~testIds[…batchsize-1]; //same each batch (rand only once)
in the ~validation func (the noise comes from giving each batch new test data points…)
as far as i understand this makes no difference (only has impact on training)
before the mlp sees any train data, the test data is split off and it never sees it,
same for the validation data (it never sees it to train) but it can have a different % cause this split is taken from training set (not test set)
does this make sense ?
ok i have a nice printout version (dirty hack) which lets me know the patience and validation error so I can see in a few hours if it ever gets to 10
it does make a difference as you are changing the ratio of what you test vs what you train on, no?
in the code I pointed at we have (simplified)
for each iteration:
_a. permute the indices for the training set
_b. for each batch
__i. forward process on all of the batch
__ii. compute the error
__iii. backpropagate the inverse
_c. if there is a validation
__i. compute the loss of the whole test batch
__ii. if larger than previous iteration, count, if not, reset count
once all iterations are finish
_a.run the whole input (not just the training set) and spit out the error
once the ‘larger than previous iteration’ count is at 10 you stop early (it means it hasn’t improved for 10 iterations)
so at the moment I never get more than 3 iterations in a row going up (since I started running it 15 minutes ago) so I’ll let you know if I ever reach it. I’m also plotting so we’ll see if I get what you have.
yes absolutely! but the ratio of the validation (0.1 eg in mlp params) and the ratio for train-, test split i built and used (0.05) is not connected (so does not need to match) - cause these points do never meet (are used to train), that’s what i meant…
ja, i see - the code is very clear! great work
and thank you very much for running it !! waiting here…
yey - fantastic!!
so its breaking out now? or not…
anyway on my end its great to know that it would like to early stop,
i can build this also in the train loop to exit in sclang
merci!!
ok I got it to stop (although it doesn’t stop your training loop…)
so it works - but how to use it in the language is interesting.
for instance, set the momentum to 0.99 and the learnRate to 0.01, a super high number of iterations, large batch size. it’ll stop when it doesn’t improve for 10 in a row. that is the use case - then you can check if the overall error is good enough. if not, reseed (or not) and restart? It is sort of the opposite of what you do (trust is stops early and assess the fitness)
(with my special troubleshooting I can see it actually stops early when it deserves to be)
@weefuzzy one question: we publish the error of the full set (not just training nor just validation) even when we use validation. I reckon this is right.
interface-wise, I wonder what is the use case for each…