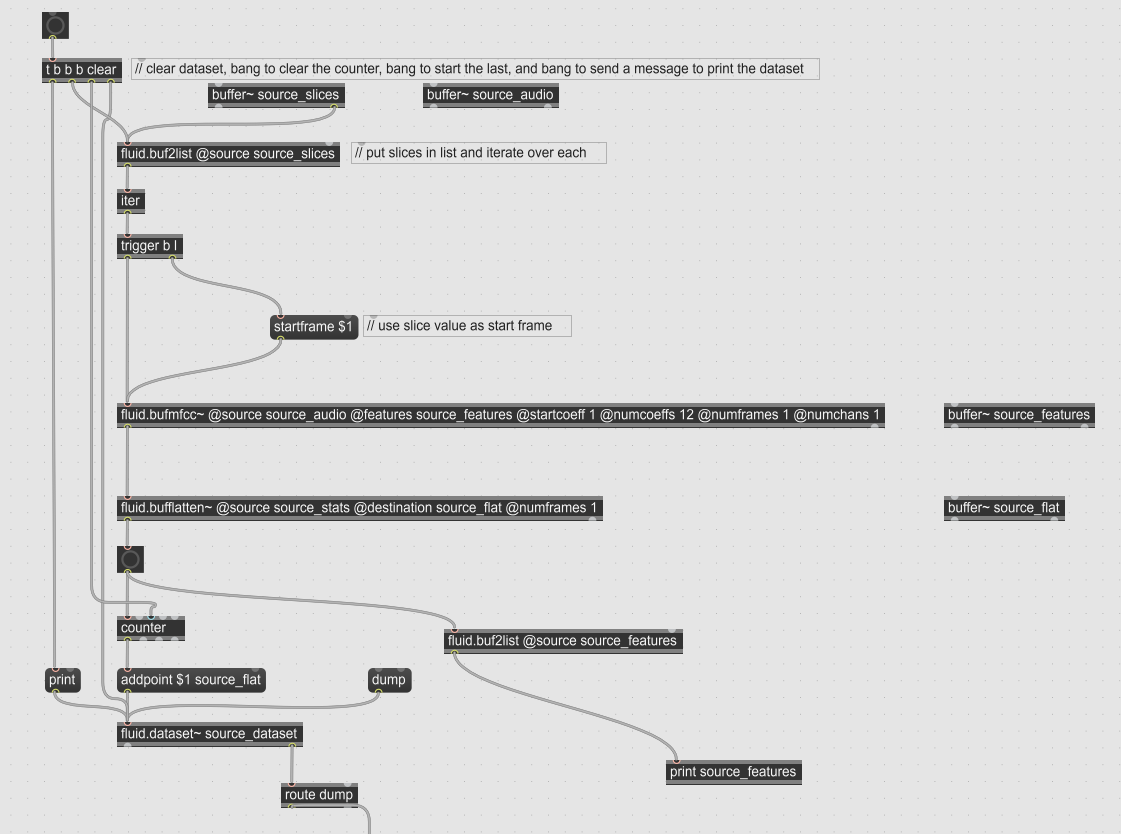
Hello everyone, first time poster and newcomer to max, flucoma and audio processing. I have a question about the usage of the @ numframes attribute of the bufmfcc object. Here is the idea of how my program is supposed to work:
Slice up my audio sample using the novelty slicer. I end up with a list of frames.
Iterate over each frame and use them as the @ startframe variable within the bufmfcc object.
Get the 13 mfcc coefficients just from the singular timepoint which has been indicated by @ startframe. I am trying to do this by setting @ numframes to 1 so that it only analyses the singular frame at the start of the slice.
Put all the slicepoints with their 13 coefficients into a dataset.
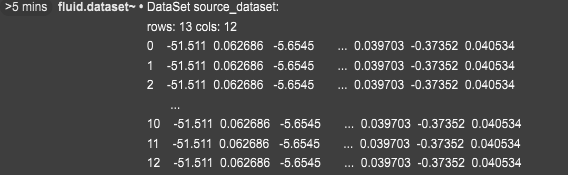
However, the issue I am coming across is that every single datapoint that gets added is the exact same. I will provide a picture of my program along with the output. My code is based on an example of @tedmoore that I found on his github (10a-concat), I hope I explained everything well, and can get some pointers if I’m incorrectly grasping this topic. Thank you in advance.
I think part of what’s tripping you up here is the term “frame” is used in a couple different ways here (in FluCoMa too).
So @numframes is actually “number of individual audio samples”, so @numframes 1 means you are analyzing, literally, 1 sample of audio. As in 1/44100th of a second.
Now as to how to correct this, it depends on what you want to analyze. So you’re slicing a larger buffer into individual slices. Are you interested in the MFCCs for the whole of each slice? Or just the very start of it? (both are valid/interest, just different).
Novelty is also a, potentially, problematic algorithm to use for slicing here since it has a lot of “slop” in it, since it will only return a slice at the point of an FFT window, meaning if you only analyze the “start” of each slice, it’s possible you may completely miss analyzing what you are after.
Here a “frame” is an audio sample, so a single “frame” would be 1 / 44100th of a second–much to short to contain any “audio” that could be analyzed and represented. If you’re looking to just analyze a single moment in time, the shortest amount of time that would make sense is the FFT size, which by default is 1,024 samples. You can find more about FFTs and how they’re used in these analyses here:
A further consideration is think about what we mean by a “singular timepoint”. The way we humans hear sound and music can change on a moment-to-moment basis and a “single point in time” can be varying lengths depending on the sonic context. So it might be worth trying different lengths of analysis and seeing which results match your sense of “single timepoint” the best.
Hanging out around the example patches and helpfiles will build some more fluency with these things and keep asking questions here!
Thank you for your swift response! Interesting information.
Are you interested in the MFCCs for the whole of each slice? Or just the very start of it? (both are valid/interest, just different).
I am currently interested in only the start of each slice as I thought it’s probably good point to start off with, but in the future I will probably experiment with how the results change when i take the MFCC of the whole slice.
Novelty is also a, potentially, problematic algorithm to use for slicing here since it has a lot of “slop” in it.
I’ve been using novelty slicer with the MFCC algorithm as a parameter. My reasoning was that just by the fact that there’s a threshold, the start of the slice must be quite similar to the other parts of the slice, because if they were not, it would break out of the threshold and create a new slice. What would be a good alternative algorithm that doesn’t have this “slop”? I am trying to slice my source file based on the MFCC values.
meaning if you only analyze the “start” of each slice, it’s possible you may completely miss analyzing what you are after.
So a good way around this would be to instead take the whole slice, calculate an average of the MFCCs, and then put that as a datapoint in the dataset?
Thank you for your response, your example patches have been a major help towards understanding flucoma! I have a kind of C programming-ish thought process towards this; I saw the slices as an index and the whole source sample as an array where each frame is a new “block”. To me it seemed logical to just use a single point as an index, lookup the data within the array, and run it through the bufmfcc to get the corresponding coefficients. But I suppose that that’'s not the way it is.
Anyway, if I were to increase the @ numframes to the smallest sensible size (1.024 samples), then should I run the result of the bufmfcc through bufstats and calculate the mean of that (small) timeperiod? I will be experimenting anyway, but I would be curious to hear your thoughts.
BufStats is usually used to summarize a time series of analyses. If you only analyze 1024 samples and the FFT size is 1024, you’ll only get one analysis frame (padding issues might apply? @rodrigo.constanzo ? @tremblap ?), not a time series, so it wouldn’t be necessary to use BufStats to get a statistical summary of the timeseries.
Because you’re using MFCCs you will get out a number of values (13 by default), but that’s not a timeseries, it’s a vector describing one moment in time (here by moment i mean FFT frame). You wouldn’t want to use any statistical summary on this vector because the values will be useful when used together as a vector.
You can also use fluid.bufonsetslice~ which also lets you use MFCCs as a metric. The reason I mention it is that novelty is more generally useful for separating types of material as opposed to slices of a material. It can also be used that way but it’s more of a “macro” segmentation approach.
Either of those approaches will only give you a temporal resolution relative to your FFT size. So with the default FFT settings, you can only know that a slice happened “somewhere within 1024 samples” (~23ms). It’s impossible to know more accurately than that.
If you’re analyzing the whole slice, then this doesn’t matter so much as it will all get averaged out, but if you only plan on analyzing a single (FFT) frame of audio, if your slice happens at the very end of that onsetslice/novelty slice window, you will have very little of the information you actually want in there.
Another alternative is using something like fluid.bufampslice~ which can only do slices via changes in amplitude but it is sample accurate. Meaning where a slice is detected is exactly where that slice happened.
And you can combine the approaches (what I do) where you use amplitude for the slicing, then use fluid.bufspectralshape~ to analyze the MFCCs of that slice/segment/whatever.
Indeed. It is somewhat unusual to take just a single FFT as you’re measurement, even if you are interested in a single slice of time. For example if you have @numframes 1024 and your FFT size is @1024 256 1024, depending on @padding settings can give you anywhere between 4 and 7 frames of analysis, all corresponding with that same chunk in time, which you can then average out into a single frame (of 13 values).