I’m designing an installation and I currently use mubu at the core of it.
People talk in a mic, I record in a buffer. When record is finished, I need to trigger some analysis in order to classify sounds:
• globally loud or not
• spoken words vs music vs noise
First feature is quite easy. I « just » do a rms, and a global mean, max, min, dev. It is enough. I could improve it I think (happy to have more ideas)
Of course, the second features sets are not disjoint sets… A music could contain a speech, etc etc.
But I’d like to know if flucoma could help here.
Basically, it doesn’t have to be done on the fly, but in sequence: record start, record end, analysis starts and when it ends, it saves the wav file with a labels (or store a coll or a dict with wavefiles names and a label with their features to retrieve them and play them, next.
I could change the architecture to remove mubu from the equation, and use flucoma maybe.
Any ideas or help or links could be really appreciated
Indeed. 2 things really quickly now and a few questions:
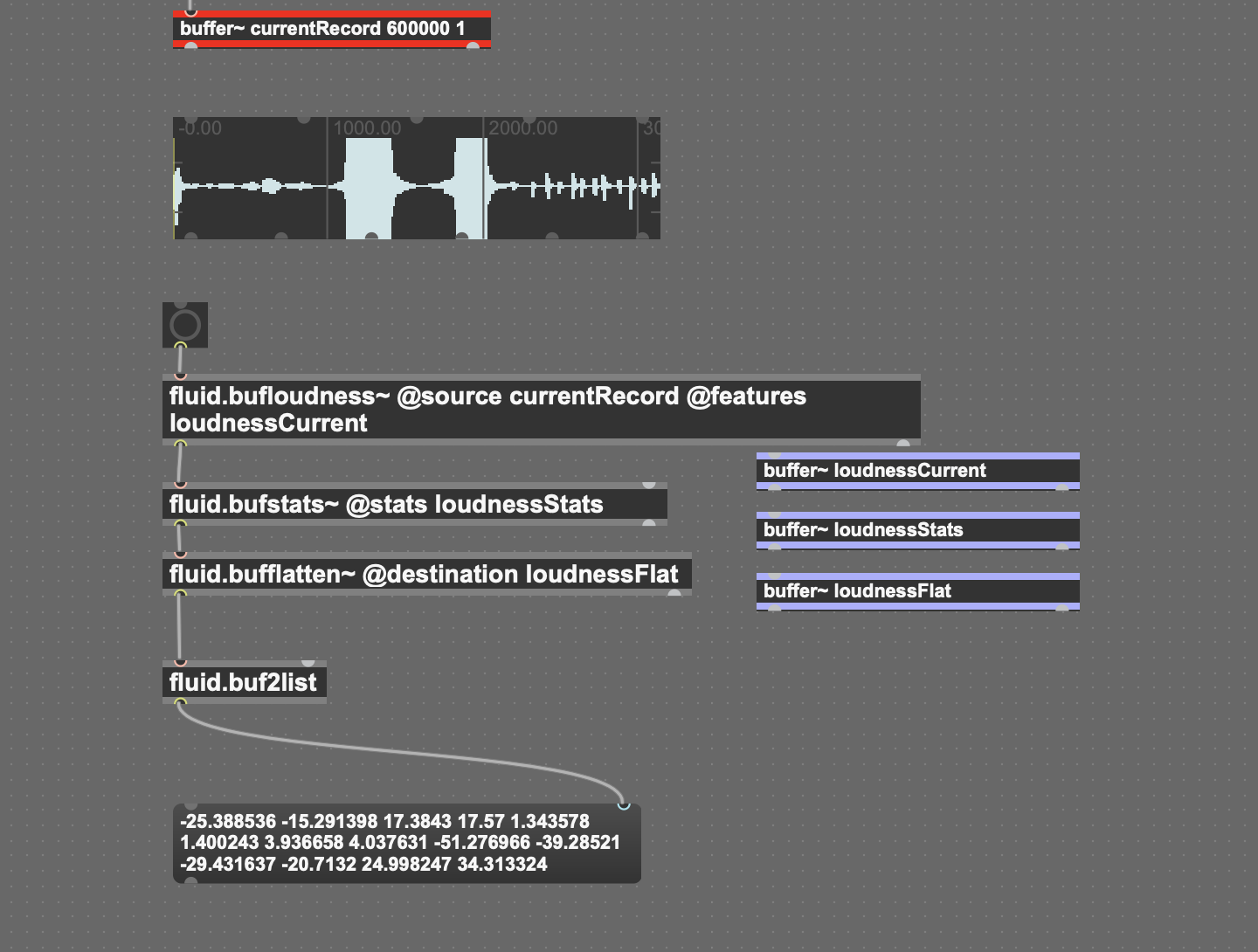
fluid.bufloudness~ will give you the EBU loudness in LU as a time series in a new buffer.
fluid.bufstats~ will give you all the stats you can dream off.
A combination of these 2 will give you what you need.
This is harder but possible. It depends on your signal, and how long you analyse for, and what you want to consider ‘music’. The same princinple apply: fluid.buf* where * is a descriptor will help you by giving the time series. you can then get the bufstats on them, and decide your valid stats (mean, std dev, median, centiles, etc)
If you define the type of signal you imply by words/music/noise then I might be able to help. The best way I found to get a feeling of which machine listening feature / descriptor works well for a task is to look at the time series vs the signal and compare. @amundsen shared a cool patch to do that here
Ok for the loudness. I think mean can be already good.
For sound classification, it doesn’t have to be very accurate, in my case of use.
I checked fluid.knnclassifier~ object and example patch.
It seems, afaik, that you’d “just” have to setup the patch with let’s say 3 samples taken as source of analysis and then it could try to classify an incoming signal among the 3 samples as source of analysis.
Is it that easy ? or did I just fall into a specific case where it works always.
it can be, if the description is done right and the classes are so segregated. Try it and let me know if that works for you, and if not, we can go further into training a slightly more robust classifier.
In effect, you can add a few examples in a knnclassifier (a few of each class) and it might make it more sturdy.
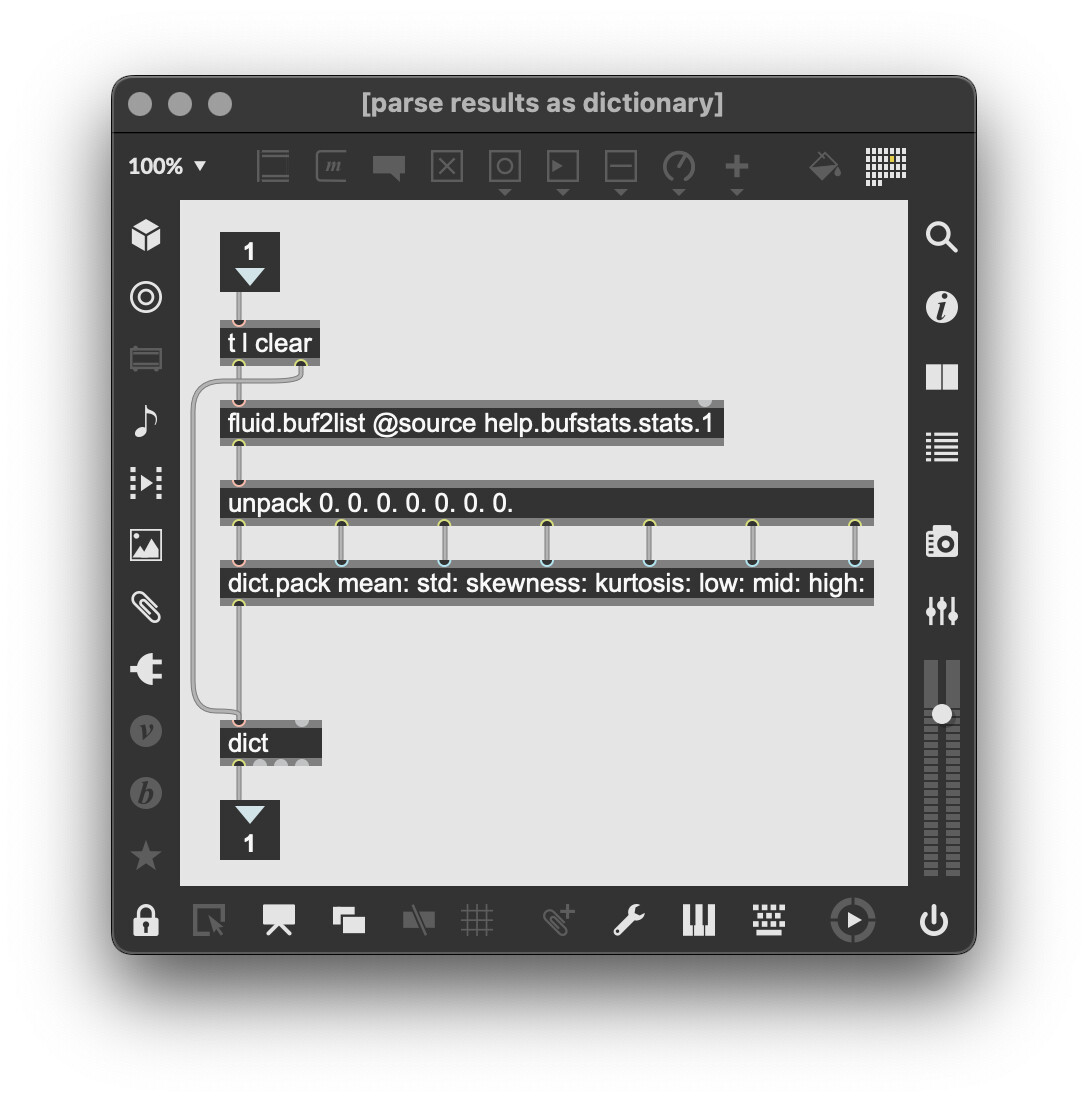
yes, and also the 3rd tab (select) gives you the order, and also the reference page, in the first line:
fluid.bufstats~ statistically summarises a time-series (or any values) that is in a buffer, returning seven statistics for each channel: the buffer channel’s mean, standard deviation, skewness, kurtosis, low, middle, and high values.