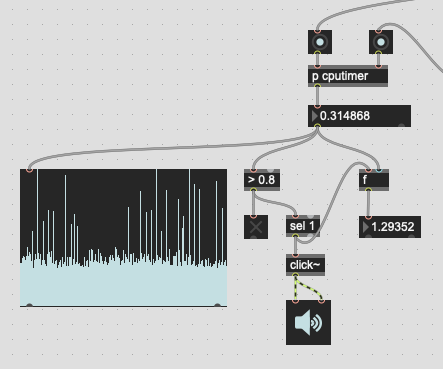
Perhaps this is intrinsic to rocking the @blocking 2 thing, but when chasing down gremlins I found that the processing time of fluid.bufspectrashape~ was varying pretty wildly. It generally takes a nice consistent 0.3ms (closer to 0.4-0.5 in the larger patch), but every now and again I get massive spikes up to 4 times as slow.
I thought this might have something to do with another query arriving before the previous one has processed, but that doesn’t appear to be the case.
Now what makes this particularly fiddly is that it seems to come and go and seems to be impacted by the rate at which the process is triggered (the metro in the patch). The numbers and timing here are setup in a way that a query never arrives before the last one is being processed, but it still jumps around a lot.
So I get something like this:
(in the context of the actual patch, I don’t trigger two things in a row like this, it’s all being driven by fluid.ampgate~ with @minslicelength 1024, so in reality no slices ever arrive closer than 20ms from each other, but I still get the same issues I get here. the delay thing is just a way to isolate the problem for demo purposes)
I tried running the same process with the “cloggers” from the fluid.bufthreaddemo~ help file, and that doesn’t seem to have an impact (other than slowing the UI down).
Is this just “how it is” when working with @blocking 2 or is there something else going on here?
I think this si just how it is: the evenness of processing in blocking 2 will be a function of how much other stuff there is in the scheuduler queue (including the previous job) but will also not be completely immune to what happens on the main thread, e.g. if Max needs to temporarily lock some shared resource.
Check out the ‘immediate mode’ tab on the fluid.bufthreaddemo~ for a histogram of timings in the different threading configurations: its tighter in blocking 2 but there’s still some variation, and you can end up with the ocassional more drastic outlier.
I think @rodrigo.constanzo’s next step is to learn C++ and code using the clients… but that is a big job
Max prototyping, then C++ optimisation, could be a fun workflow, but that is starting to be far from playing the drums… a compromise approach is probably to learn SC as I think it might be more consistent… once we have all that server-side job stable… the problem with Max is that it is quite not meant to do JiT. FTM used a way, FrameLib uses another one, but this is a hard problem…
I had a dig through that patch to see, but nothing (in the help file at least) jumps around nearly as dramatically. This all stays in a range but then has wild spikes in there, with nothing else but this patch going on.
It’s not doing nothing (fluid.bufspectralshape~ → fluid.bufstats~), but it’s not a lot nor is there anything else going on in Max at the time.
edit:
I mean, I’m not asking for a lot. I just want the perfect information, with zero latency (as a compromise from “negative latency”), with zero CPU usage…
This is literally a quote from my keynote. did @a.harker send it to you, or is it just sheer luck (and vindicating my artist hat description)
really? even with the crazy cpu-clogger I’ve put? I get some range… although your tolerance is super small (4 times 0.5ms is 2ms, so this is nothing considering max’s scheduler is at 1ms…)
With some twiddling about, it looks like there is interaction with the main thread (presumably thread sync for buffer access) that we can’t do much about. If one strips the patch back a bit, to a single CPU timer subpatch and no button objects, and turns the metro / delay up so it’s pretty stable, you can see it jump if you drag stuff about.
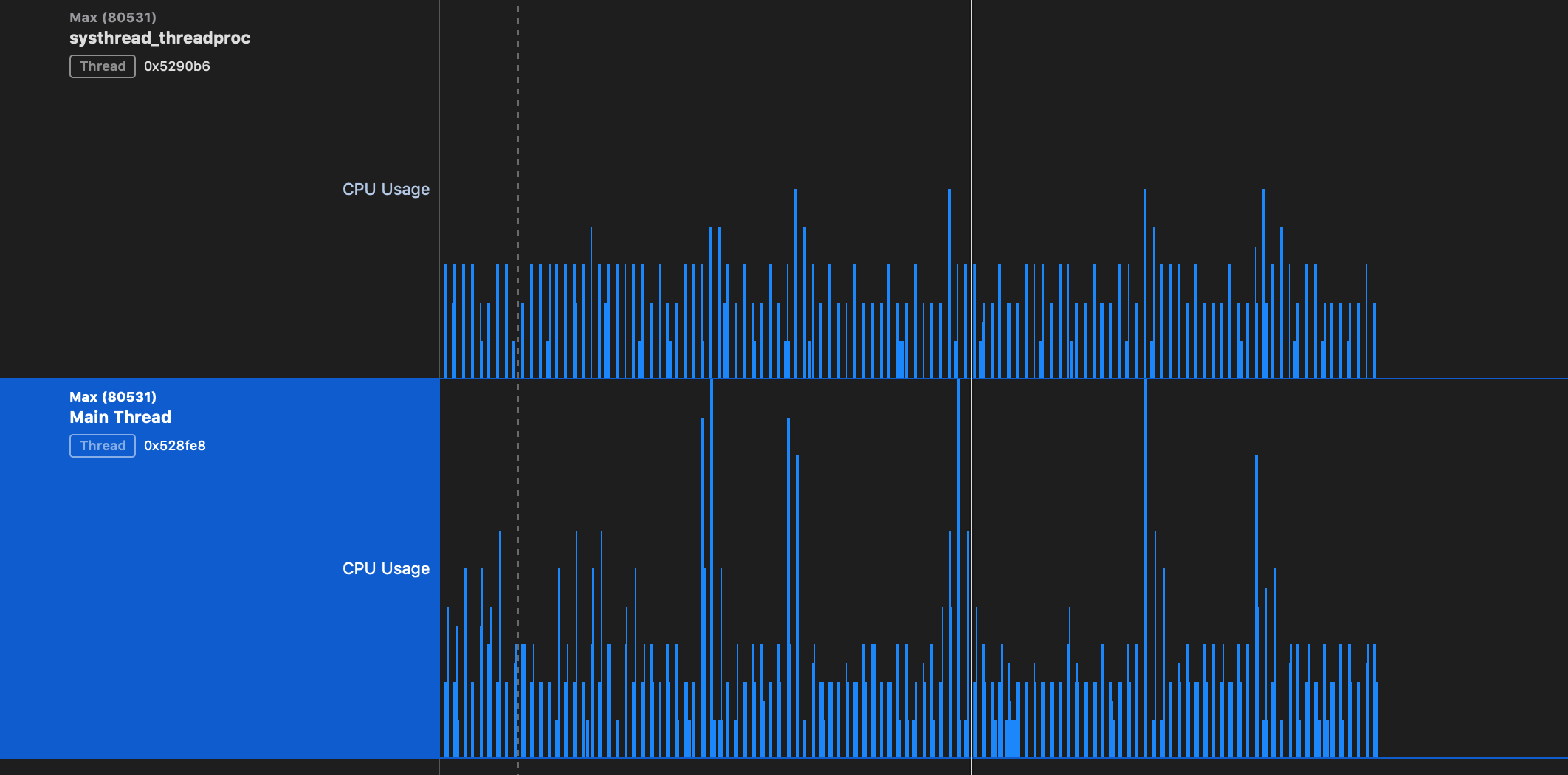
If I run it in a profiler, you can see how the bumps in CPU usage between the main thread and scheduler are quite strongly correlated:
I remember you mentioning this, but with regards to @groma’s experience in working with musicians. (them being much pickier than CS folk)
Fair play.
In the scheme of things it is’t much, but when trying to eek out every bit of juice/speed, this popped up as a slow spot. Surprisingly (or perhaps, unsurprisingly, I don’t know), I only get this jumpy performance out of fluid.bufspectralshape~ and not fluid.bufloudness~ / fluid.bufmelbands~. Both of those seem a bit more stable.
(mid-post edit: I isolated stuff as well, and it appears that they all act the same. In the larger patch I seem to get more spikes on that, but that could just be the luck-of-the-draw when I decide to inspect it)
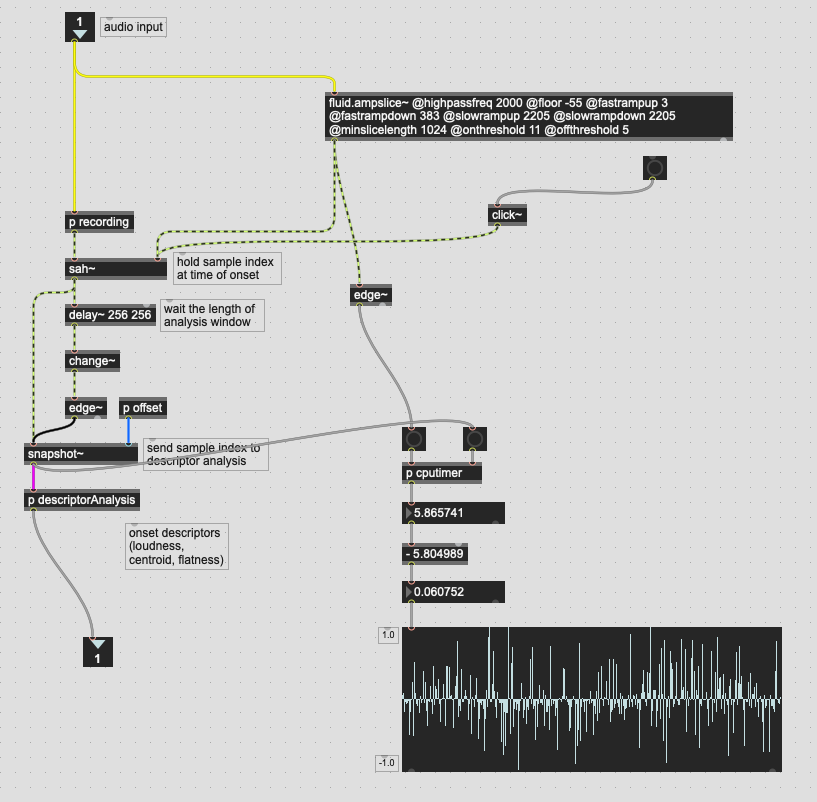
So I was tweaking this a bit more and isolated the part of the patch that does the vanilla onset detection -> snapshot~ stuff, that then produces the startframe for the subsequent analysis.
And the timing for that was pretty erratic.
I kept isolating bits of the patch and the timing of stuff is crazy.
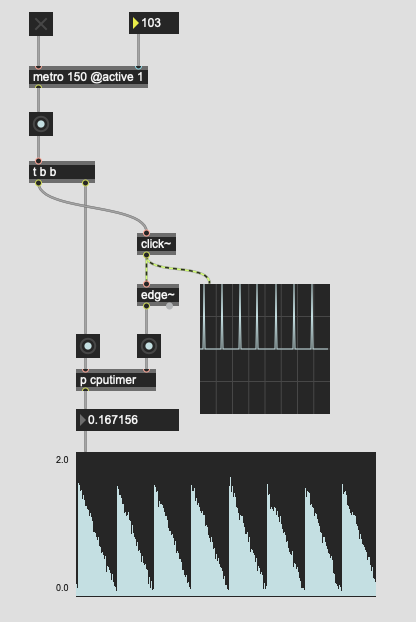
Weird things happen at diff metro settings too. metro 103 is particularly bad and gives that really obvious pattern there. metro 105 seems to create a pattern too, but not nearly as obvious (or looks more aliased/intertwined).
That seems weird I thought, so how about something more “in context”, with the actual bits of the patch that would be doing it:
I thought it might be some audio-rate order of operations stuff, so I chucked a delay~ 1 1 on the signal going to the sah~ but that had no impact on this.
It might be time to look at @a.harker’s fl.libLand @tightness really->fucking #fast. (I will probably send a polite and inquisitive message to @jamesbradbury too)
The “slop” shown earlier in this thread will be unavoidable, but it would be good to tighten up this chokepoint where the msp~ meets control rate.
edit:
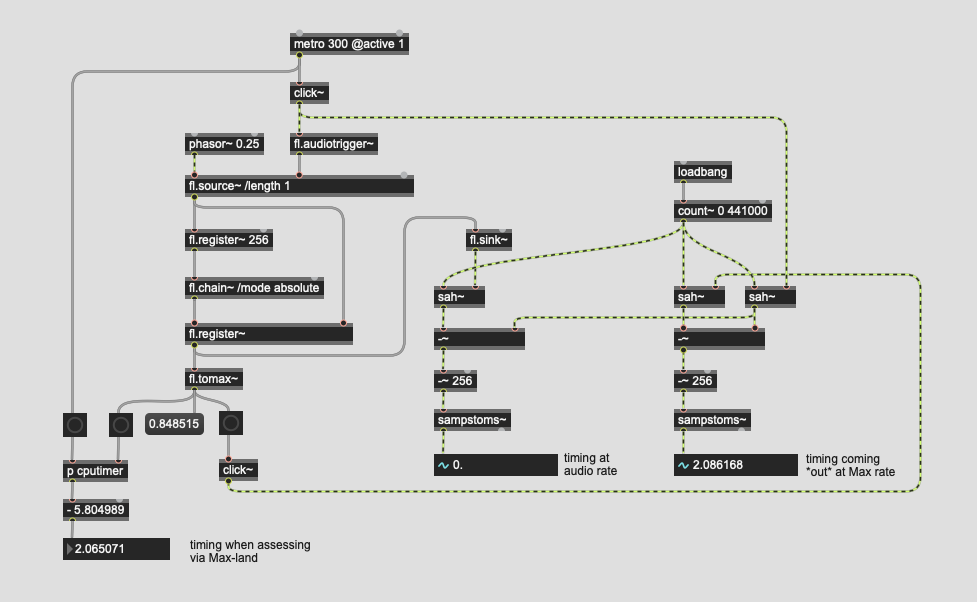
Here’s the code for those weird timing examples:
as I said earlier, this is where FTM and framelib have their raison d’être. In your first patch you are getting, I think, a phasing between your query and the size of the vectorsize. If you query at the begining you have long latency, if you query at the end you have a short one…
One approach to your thing could be to use framelib to cross the boundary, then do your ML stuff. I don’t know if that’ll be much better but at least you are almost certain that FL will be tight. Going in message land will most probably always have the same problem though… @jamesbradbury and @a.harker and @weefuzzy are active users and will be able to tell you if you swear less
It will always have to touch the scheduler somewhere cuz I have to bang the fluid.buf()~ stuff, but I can hopefully minimize needless slop and jitter for that part of the patch.
For the most part, I’m still not doing this yet. Having a way to bias a query would be super handy, especially since I’m analyzing multiple time windows now (for the offline/buffer stuff).
I was thinking today that I do need to sit down and compare speeds for that stuff too, though I imagine part of the appeal of the knn stuff is that it pre-computes the distances, making querying/matching faster(?).
More than anything, I just need to hunker down and figure out how to do this “new school” and try things out.
I was thinking of trying to combine the knn stuff with dimensionality reduction/clustering where the clusters are “directly” mapped to the classifiers, and then do distance matching within each classifier. Could be an interesting way to leverage both of those approaches.
I guess it’s one of these quantum measurement problems, in that it’s impossible to time things going from msp->Max without incurring scheduler slop.
So with the fl.solution~, I have zero slop from input to output if I time things using msp~, so with that I have to assume that the output of fl.tomax~ is also tight, and will carry on, happily to the fluid.buf()~ stuff with no more slop.
(I’ve got a bela mini on my desk at the moment (from backing the Trill Kickstarter) and part of me is imagining trying to get a stripped back version of some of this stuff working on that. (you can have a 2 sample i/o with measured 1ms from controller input to audio output!!))
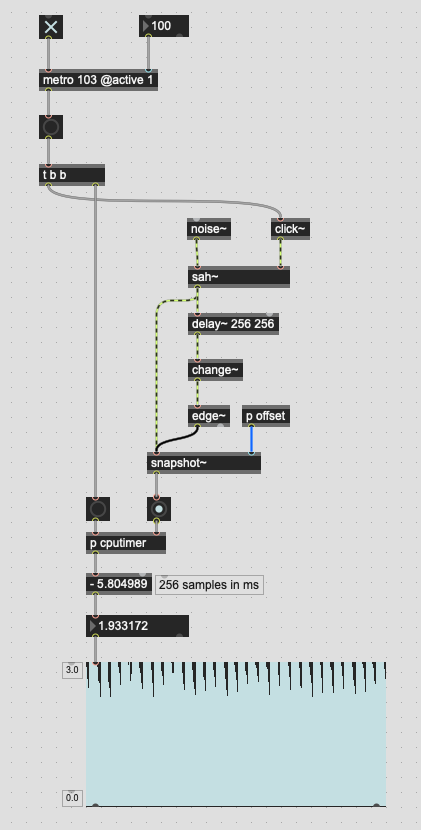
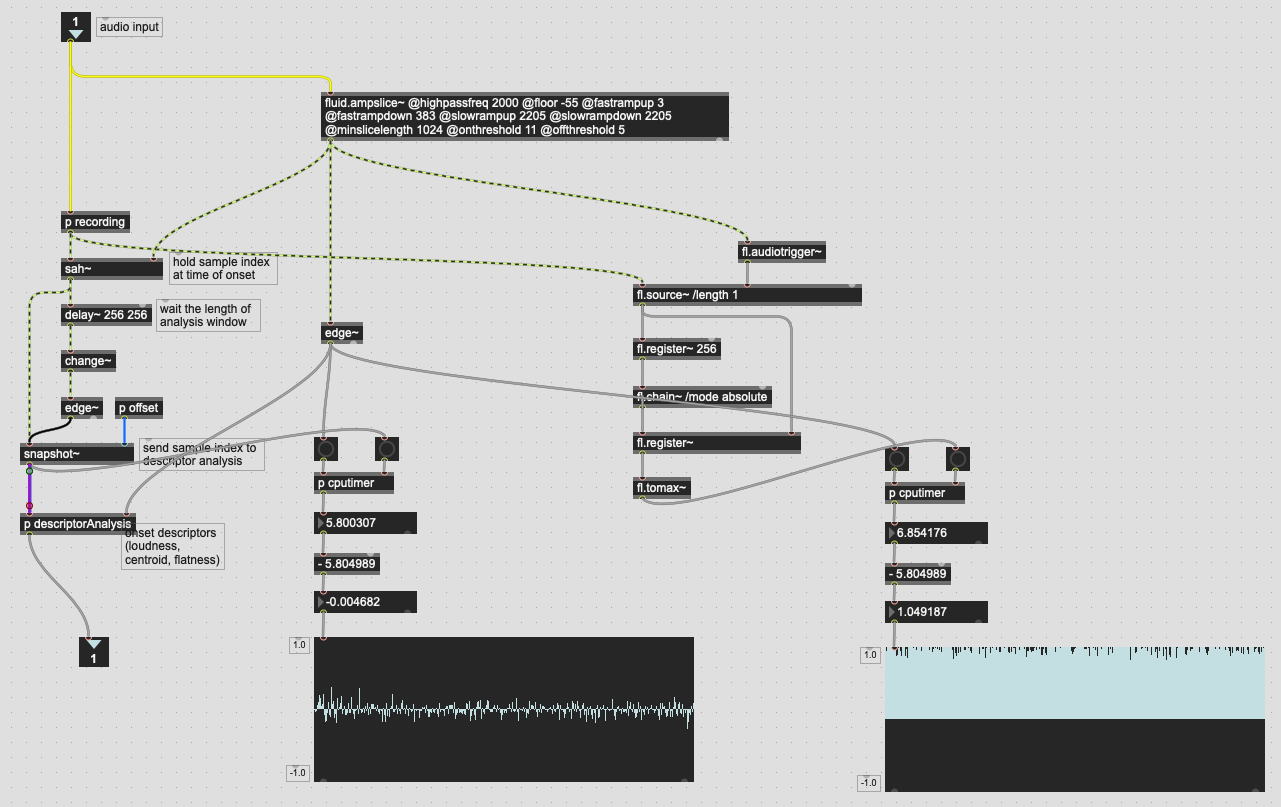
Again, I’m not sure if this is a measurement problem, or a timing problem, but if I put the framelib code in context I get much worse measured performance than with the vanilla sah~/delay~-based version:
(granted, I have to go via edge~ to measure things this way, which may add slop but the slop would presumably be the same for both versions)
What makes it even weirder is that if I measure the latency further down stream, with edge~ still triggering the start of timing, the results of both seems to be the same, or much more similar than what this shows here.
Also, I have no idea why this would be the case, but if I move the pink cable over and connect it to fl.tomax~, the timing measured in the fl.version~ gives me the exact results of the sah~ one (this could just be some threading shit I don’t understand):
In speaking to @jamesbradbury he did mention something about fl.tomax~ potentially having some slop in it. Don’t know if that’s still the case or something @a.harker worked out already.
Sadly the process needs to terminate in Max-land as the next objects down the line from here is fluid.bufdescriptors~, which need bangs to get going. So I can’t just stay “signal rate” (or framelib rate for that matter).
I think your assumptions were wrong in this sentence, and in that one:
The question is not how tight things are in msp-land (which is what framelib is in in effect) because we know things are sample accurate (in fl) in there anyway. The question is what is the tightest you will get in control-land.
You remember my analogy of the Ferarri to do a tractor’s job? You are not comparing speed of any car on a bumpy road. the problem is not the car, it is the road. In this case, the road is the precision of max messaging. FTM has hit that problem and solved it a certain way. Framelib took a subset of that problem and solved it another way. At the moment, your problem is within 2ms. You are very likely to not get better than that in any environment except if you do dedicated app for your bela… but I think you are talking academic problems here since a 2ms slop is much tighter than drumming. Actually, if you move as you play by more than 2 feet (which you do) you are within that slop with the sound’s airtime travel…
but if you want to make it faster, things to try in order of difficulty:
optimise your Max (lower SVS and IO (as cpu cost) queue size and speed (in the pref) etc)
try everything in framelib and see if you can actually hear a difference and see the cost in cpu
try Chuck which has a svs of 1 (everything is samplerate)
eventually, when you are convinced, learn or hire C++ coding people to make a custom app)
The latter loses all the advantages of a creative coding environment, but you get fast stuff the way you want. it is only the way you want though, so does not allow simple research on other means. If you are interested in such discussion, I recommend reading the Max list when Max 7 came out (or was it Max 6) when people said Max was bad because it took 5% cpu ‘doing nothing’ - at one point I don’t remember if it was David Z or Kit C who explained what is the overhead of creativity and flexibility.
I’m sure @weefuzzy and @a.harker will remember more. My take-home message is simple - if you can’t hear it, is it worth your time for now? This is a version of the very wise Knuth’s law of optimisation. Actually this article is a good one: 5 laws every developer should know
Don’t have time right now for all the details, but basically my thoughts would be:
1 - expect CPU timings to have some variance - you are on a general purpose machine, and not a true realtime computer with proper interrupt priority or guaranteed time constraints - probably not worth worrying too much about the variance, in comparison to the overall costs.
2 - if you really care about timing you do everything in the MSP thread - every time you switch threads in Max you are basically giving up on tight timing - there is no such thing as maintaining tight timing (although you can maintain order). fl.tomax~ simply calls schedule - there’s no special slop here - just the slop of moving between the threads - this will always happen, regardless of the technology. I’m not 100% sure what the framelib stuff is supposed to do in this patch, but it doesn’t look like the right thing to be doing to me (grabbing single samples at specific times).
Hehe, I just went real rabbit-hole trying to iron out every little bit of slop I could.
Having +/- 2ms isn’t a big deal. The problem potentially comes where there are multiple of these along the whole chain, which can start to add up to a perceivable amount.
(I’ve been going with 512samples (11ms) as my limit in terms of “feeling” it. It feels real tight when I’m limited to that amount of latency, but since I’m adding additional things (the melband stuff, compensation, ML, etc…) each of these is coming with another time cost, so I’ve cut the analysis down to 256 (6ms) so the rest of the shit can happen while still keeping it around 10ms overall).
An ideal solution that wouldn’t involve going too crazy with solutions would be to stay completely in framelib. I think @jamesbradbury has all the spectral moments worked out there. Don’t know if there’s any plan for more bits of flucoma/framelib to overlap (i.e. having more of the descriptors present in framelib-land), but that would certainly solve the ‘tightness/speed’ stuff “simply”.
I guess as a final question on this specific area, is using framelib in this context faster even though cpuclock says it’s slower?
If I just count~ + -~ on the outside, I can confirm that it takes exactly 256 samples to go through the framelib system (with a fl.chain~ set to 256 samples). It was just a matter of moving from framelib back to the scheduler, if that incurs the same slop/timing stuff as going from msp~ to scheduler. If so, I can just keep the older sah~ approach since it means no (extra) dependencies for that part of the patch.
There are built-in moments calculations in framelib, but you need a bit of extra code to convert some of the results to the correct units (James’s versions were I believe working from scratch).
There is a difference between the speed of the processing in framelib (time taken on the CPU), the slop sending it back to the scheduler, and the delay in doing the calculation (which is zero, although you have the latency of collecting the samples). So, depending on what you will do with that data different things matter. Time in a real-time audio system is largely a concept, rather than a reality which makes this stuff all a lot harder to think about, because humans think about now whereas the computer has other ways of tracking time (such as sample position, time tags) which do not relate to “clock” time.