I knew something like this was in the works in speaking with Jordie, but hadn’t realized they had published the paper/code already.
Abstract:
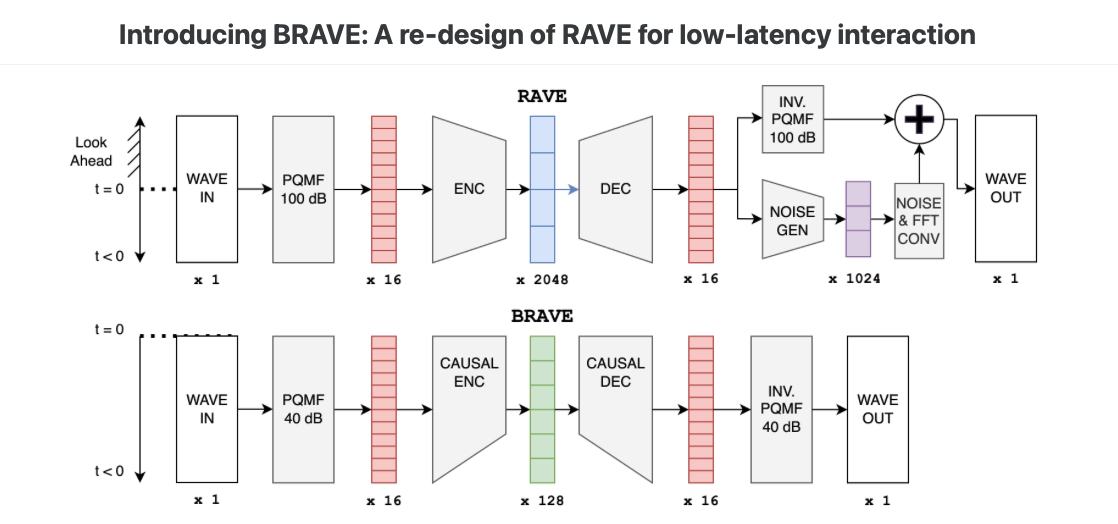
Neural Audio Synthesis (NAS) models offer interactive musical control over high-quality, expressive audio generators. While these models can operate in real-time, they often suffer from high latency, making them unsuitable for intimate musical interaction. The impact of architectural choices in deep learning models on audio latency remains largely unexplored in the NAS literature. In this work, we investigate the sources of latency and jitter typically found in interactive NAS models. We then apply this analysis to the task of timbre transfer using RAVE, a convolutional variational autoencoder for audio waveforms introduced by Caillon et al. in 2021. Finally, we present an iterative design approach for optimizing latency. This culminates with a model we call BRAVE (Bravely Realtime Audio Variational autoEncoder), which is low-latency and exhibits better pitch and loudness replication while showing timbre modification capabilities similar to RAVE. We implement it in a specialized inference framework for low-latency, real-time inference and present a proof-of-concept audio plugin compatible with audio signals from musical instruments. We expect the challenges and guidelines described in this document to support NAS researchers in designing models for low-latency inference from the ground up, enriching the landscape of possibilities for musicians.
Video examples:

Webpage with diagrams and audio examples:
And plugin with some models:
Looks like it can load other RAVE models too, which is nice.
Having a quick play with it and it is, in fact, really low latency. Loads better than nn~. It seems to need a minimum of 128 for the vector size such that running at smaller vector sizes makes it really unhappy. I imagine this is an unavoidable issue with the plugin inheriting the signal vector size from the host even if it can’t actually compute at faster rates. Don’t know how VST works with regards to that.