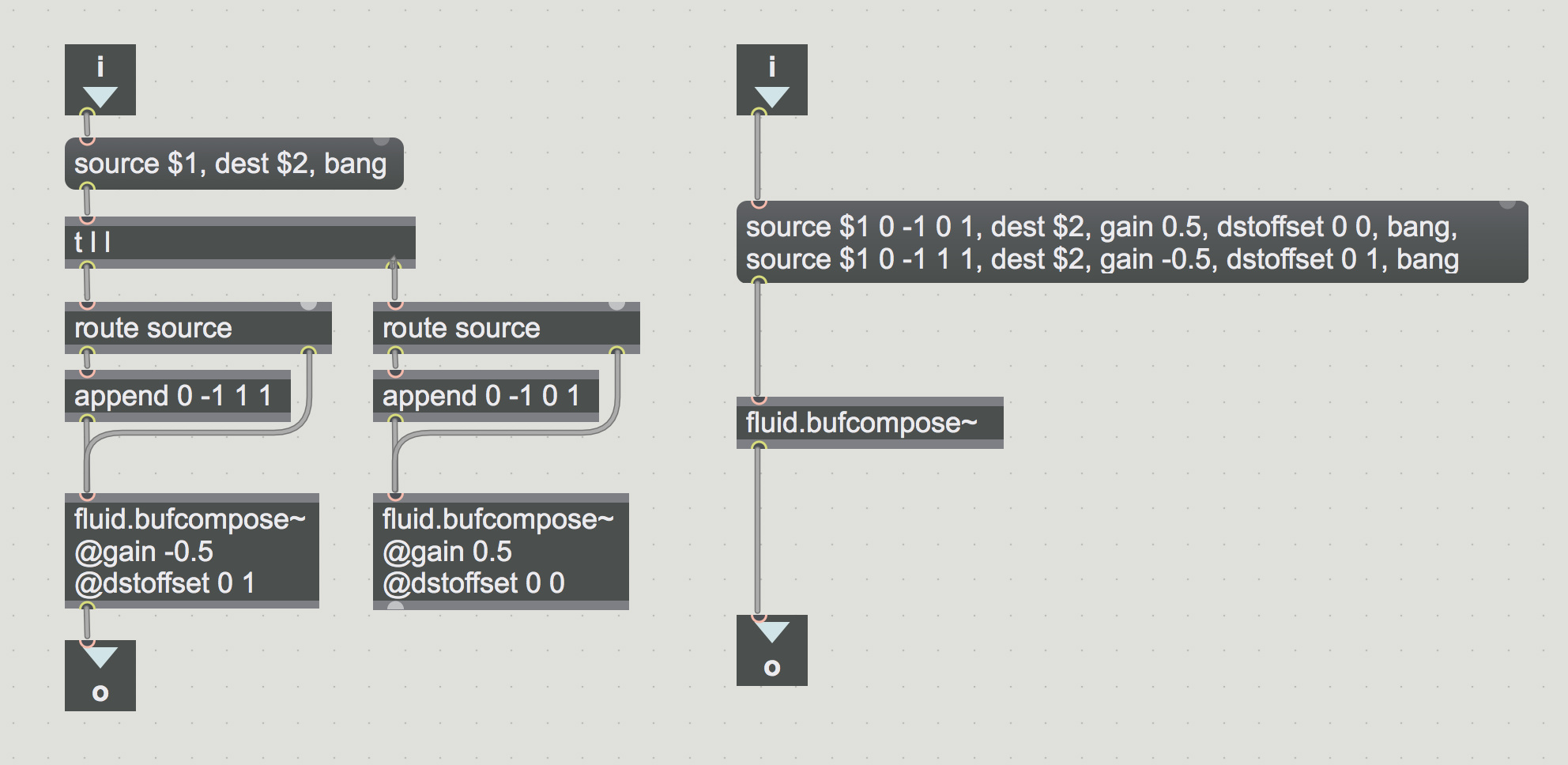
My thoughts are turning to how to improve the interface for BufCompose in Max, and I want to get thoughts on a suggestion. Buf... Objects in General
All Buf... objects’ input and output buffer arguments are exposed attributes (I guess this is true in the version people have) but attributes are no longer also useable as message arguments in process, because it’s confusing.
Ergo, the message to these objects now has no arguments, and can become bang, which affords setting up cascades of processes more simply.
BufCompose
Instead of always dealing with two sources, it deals with one at a time, so its behaviour can be summarised as:
mixing a section of some source buffer into a destination bufffer (at some offsets), with an optional gain applied; it will always resize the destination buffer where needed.
This gives possible attributes (ignore the detail of the names, it’s the functionality I’m bothered about here)
@source buffer name [start] [len] [start chan] [n chans]
@gain gain factor (default 1.0)
@dst buffer name
@dstoffset [start frame] [start chan]
I appreciate that it’s a bit inconsistent having the offsets for src as part of the attribute, but not for dst. It’s exactly the sort of thing that makes sense from inside the code, but probably less from outside. What would people prefer to see here?
What I’m digging about this general approach is that it should support different coding styles. If long message boxes are your thing, then you can chain stuff with commas; equally, if boxes are your thing, you can make instances with labelled attributes to communicate what’s going on.
I definitely dig the fragmented (comma separated) message style. More legible for sure.
Having the offsets happen in different places is weird though, although I guess from your examples they can also be set by messages? (unlike the rest of the @attributes?)
Will there be more default values? As in, would you be able to send a message like source bufOne, dest bufTwo, bang and have it work? I’m still not loving the 1 -1 0 1 soup from this paradigm, so I would lean towards having defaults for all params (start = 0, len = sourceLength, etc…) to improve overall legibility.
Also, what happens if you send source bufOne, bang as a message? Do you get an error or does it just “process” the request ‘in place’? What happens if you send two bangs at the end of your example on the right? Does it execute the last process again? (ala int, zl objects etc…) Would that be problematic in some contexts?
Nope, everything’s attributes. My thought had been to bundle the source buffer up with its various offsets into a single attribute. But that might be a pain. OTOH, I’m not loving the idea of six seperate attributes for each possible offset / length, but maybe it wouldn’t be so bad.
Yes. And a benefit of completely atomising the attributes (hah), would never needing to type -1 again if you didn’t want. The defaults are currently, and will be as you say (source length, source number of channels etc). It’s different for the desintation offsets, because there’s no lengths to speuciy, just a start point and channel, both default to 0.
Thus, with no extras set, the default behaviour would be a straight copy of A into B.
If dest isn’t set or doesn’t refer to a valid buffer, then error. I think being able to accidentally overwrite buffers would be quite irritating! If dest is set, it will happily go on its way.
It will execute again, except that stuff will accumulate into dest. This may, of course, not be what’s required in some circumstances (but I, I guess, be in others). The object will always block until its finished (future threading notwithstanding), so the choice we have to make is whether to discard bangs that arrive in the meantime or not (i.e. decide they were accidental double taps, as it were). Current behaviour is that they don’t get discarded, but then it’s harder to double trigger at the moment.
I could just be not understanding things here, but in your screenshot aren’t you setting stuff by messages (dstoffset 0 0, etc…) as well as setting stuff by @attributes (@dstoffset 0 1)?
I feel I might have created this confusion by making some @attributes instantiation-only in the current version, and also by having the @attributes useable as message arguments as well
The messages I showed were lots of messages in one box, because of commas; most of these set attribute values, except bang, which is a ‘real’ message.
So, in the glorious future: @attributes will be more conventional w/r/t Max expectations. There won’t be any thing as an instantiation-only @attribute, and things will either be @attributes or message arguments, never both. Where objects do have instantiation-only settings (e.g. some kind of maximum buffer size or something), this would be an object argument, as with Max objects more normally (e.g. [delay~]).
That will put us unambigously in line with Max objects in general. i.e. if an object has a writeable @attribute, this means the object will accept messages of the form (attribute_name value) to set its value.
The only thing I can think of at the moment that wouldn’t be a writeable @attribute in our objects is the latency report folk asked for, which will be read-only (for obvious reasons). The new objects will probably have dumpout outlets, like other modern objects, that can be used to query @attribute values.
Seriously though. An extra pointer in our object, and the obex system presumably mediating incoming message calls. It won’t have an effect on audio thread behaviour, if that’s your concern.
This all presumes that I manage to infer how the mechanism actually works from the, uh, sparse SDK documentation ;-D
So I haven’t spent a long time adapting patches, but I did change one over yesterday and holy moly the new syntax/messaging system is sooo much better!
I was looking at it and thinking “this can’t possibly be it… I can read this…”, but it was!