It’s all closed source, so not sure, but from this thread ages ago I remember finding this:
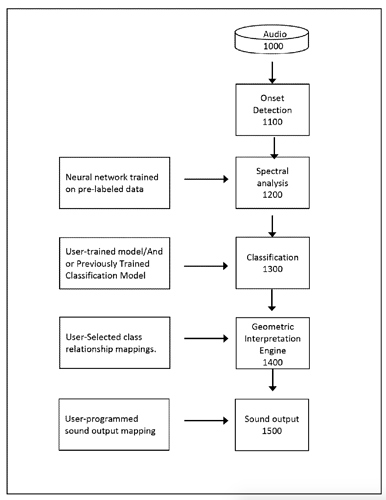
So fundamentally MFCCs->classifier, with the “geometric interpretation engine” (and instant “fitting” in their software) leading me to believe that it’s a KNN-type thing.
No clue what that “neural network trained on pre-labelled data” part means, as it’s at the spectral analysis stage.
As in another descriptor type?
The sound difference is fairly subtle:
center and edge example.wav.zip (167.3 KB)
For certain they are using “timbre” as a metaphor here (well I guess it’s always a metaphor in a computer) and instead doing something with the classes/differentiation. Part of the reason why I didn’t implement something like this before was that I was happy with just having “real” timbral descriptors going on (loudness/centroid/flatness/etc…) so wasn’t fussed about this specific idea or implementation, but for rounding things out in the toolbox, it would be handy to have.
I plan on computing the means today to see if I can do something with that (step2 above).