So off the back of an interesting conversation with @tremblap about getting the most out of a feedback system, specifically ambisonic feedback…:

… I got to thinking about how to go about building something using fluid.stuff.
So at a basic level, I can use fluid.sinefeature~ to pick out the loudest peak(s) and use that to drive a filter of some kind. I guess a notch filter for a feedback minimizer and a peak filter for a feedback maximizer.
I do have some questions on how to best something like that up.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Question 1 (the q question)
Mapping the frequency outputs of fluid.sinefeature~ to a filter seems straight forward enough, I just don’t know how to best handle bandwidth/q for something like this. Should it just be a dialed in static value (fairly resonant, but still with a bit of width) or is trying to tie the q to some descriptor analysis beneficial here (e.g. spectral spread).
This question is twofold, the first one essentially being “what do feedback killer systems do?” and the variation of that “what would be more effective for mapping in this context?”.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Question 2 (the minimizer vs maximizer question)
For the feedback minimizer, it makes sense that a straight up notch filter (using svf~ or something fancier?) would be the best choice.
For the maximizer I would think that a notch filter might be most effective, in terms of narrowing the spectra and focussing the energy on that area, though I do worry that it will end up making the overall feedback sound more like a nasal wah pedal, rather than keeping broadband noise/feedback going, just helping it along.
I don’t see myself toggling between minimizer and maximizer during a performance, but I have always wanted something that let me (quickly, and while sound checking) find the “sticky” room modes I want to dislodge and just set some notch filters on them without having to do tediously do this manually (what I’ve done for gigs in larger spaces in the past (including Kaizo Snare)).
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Question 3 (the fluid.voiceallocator quesetion)
One of the interesting things that @tremblap mentioned was combining fluid.sinefeature~ with fluid.voiceallocator (thread) to have multiple filters handing things off seamlessly. I suppose this would work well in either approach (minimizer or maximizer).
Where I get real confused with this is what to do with the state outputs of fluid.voiceallocator in terms of managing multiple filters at once.
I built a quick mockup using sine waves following the loudest two peaks to get a sense of what is happening (with some example audio), but would it just be a matter of driving the filter gains instead of sine wave gains (though not sure how that would work with bandpass filters).
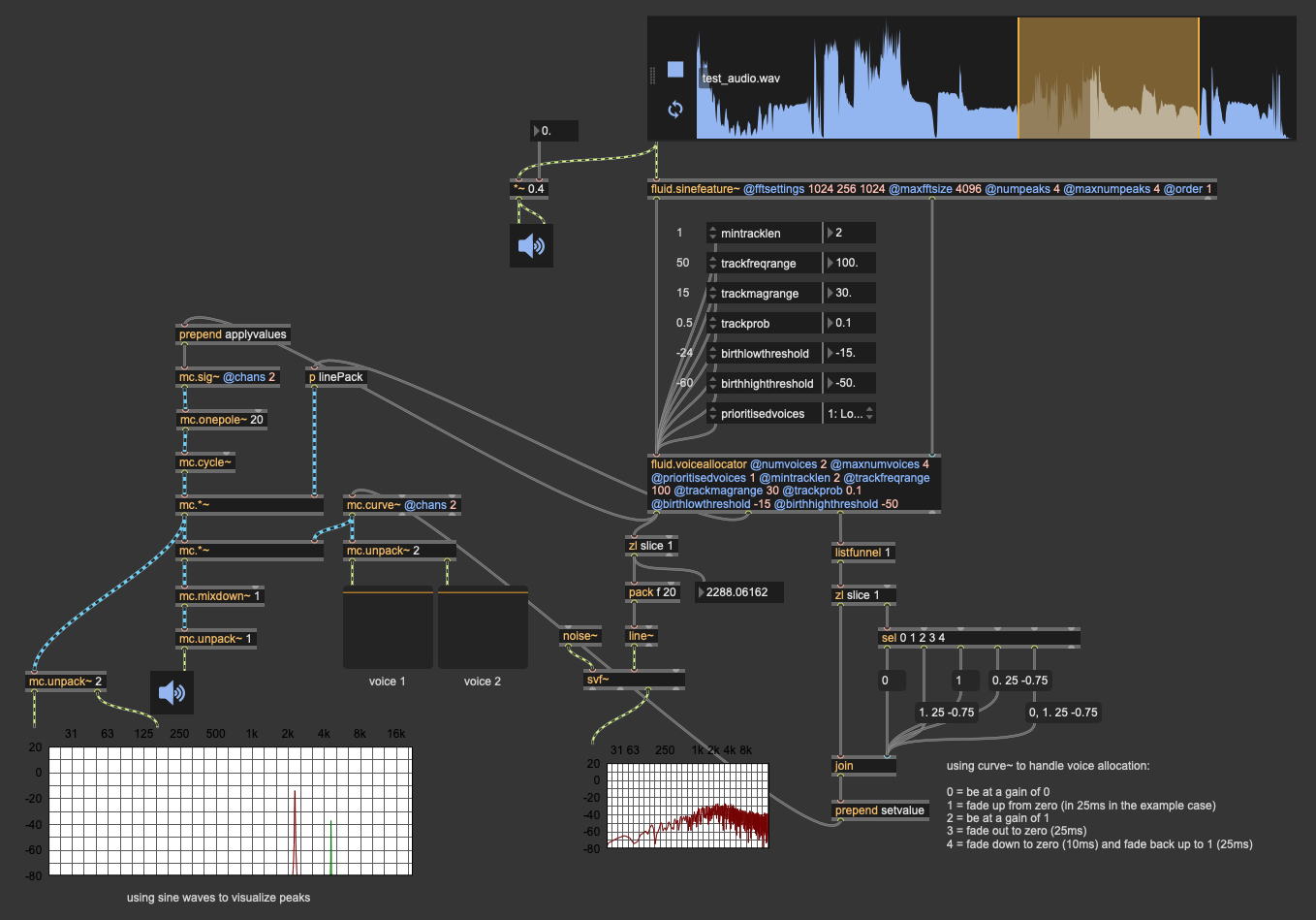
patch.zip (3.9 MB)
(this takes some bits from the mc. patch I had built in the voiceallocator thread a while back)
Also, if I wanted to drive multiple voices, I guess it would just be cascaded filters? (though again, not sure how that would work with bandpass)
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Any thoughts welcome!