So building tangentially on some other threads as well as some discussions with @weefuzzy has led me to think a bit more about data augmentation, specifically in the context of FluCoMa and “small-to-medium”-sized data.
The main use case I’m thinking about here is classification, but there’s obviously implications for regression as well.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
I came across this playlist which seems to cover some basics and techniques etc…:

And that’s been useful to brush up, but with lots of ML educational concepts, I often find not a lot of it is directly applicable back to FluCoMa/Max, and/or the scale of data involved, and/or the time frames involved.
In the second video of the series he goes over:
- Time shifting
- Time stretching
- Pitch scaling
- Noise addition
- Impulse response addition
- Filters
- Polarity Inversion
- Random gain
- Time masking
- Frequency masking
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
The one that interests me the most is the first one (time shifting). The reason for this is because of the tiny analysis windows I’m typically working with (256 samples) and a funky physics thing that @timlod uncovered in this thread about onset detection.
The main point from that thread is that when working with audio traveling through a membrane (i.e. drum head), the distance to the sensor can radically transform when the onset is detected as there’s a “pre-ring” that gets compressed or expanded whether you are near or far from the sensor, respectively.
Here’s a relevant image from that thread where the top image shows a strike at the center of the drum (i.e. equidistant from all sensors) produces consistent “pre-ring” and the lower image shows the difference between a strike near the blue sensor (tiny “pre-ring”) and the red/orange sensors with elongated “pre-ring”.
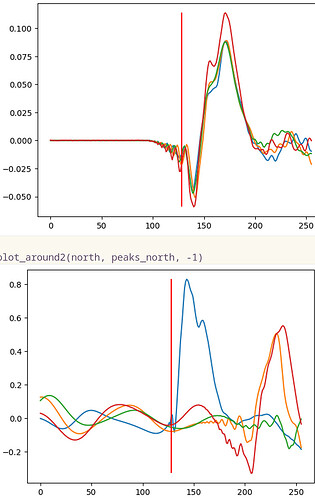
Here are some more images which shows exactly where the onset is detetcted.
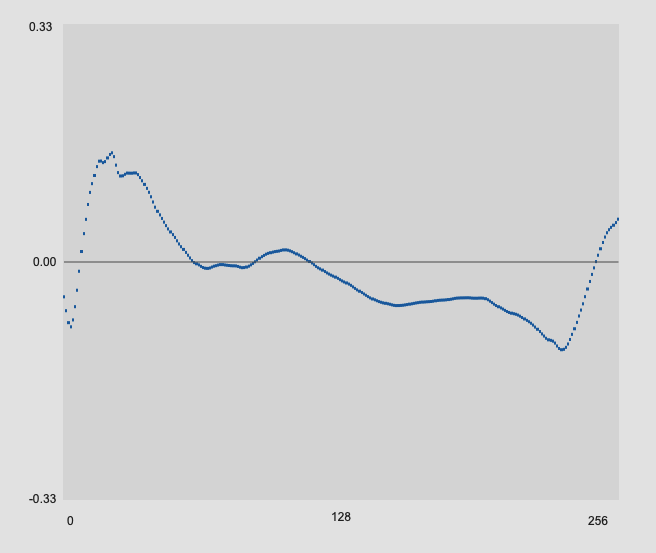
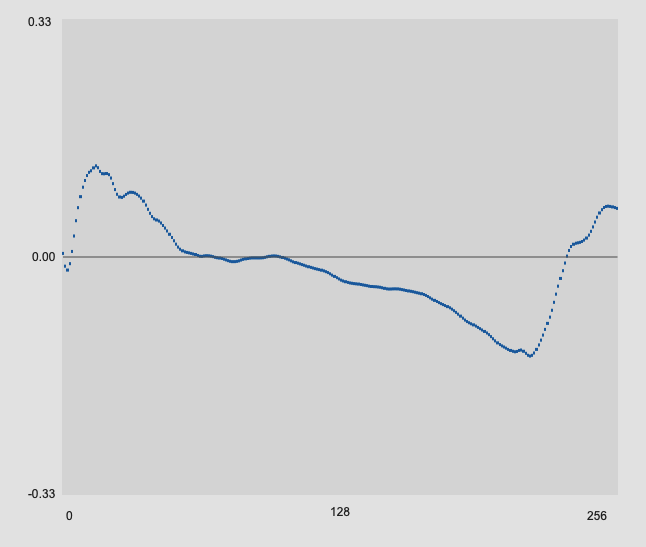
The first three hits are for drum strikes here:

That produces onsets that look like this:
And here are some strikes at the furthest position away from the sensor:

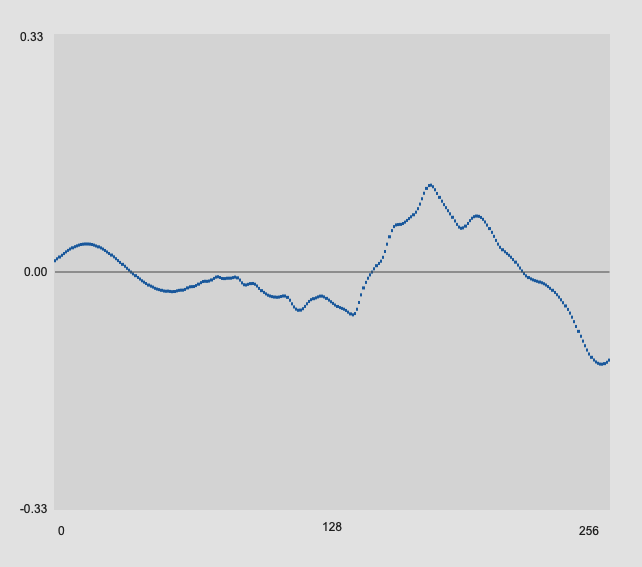
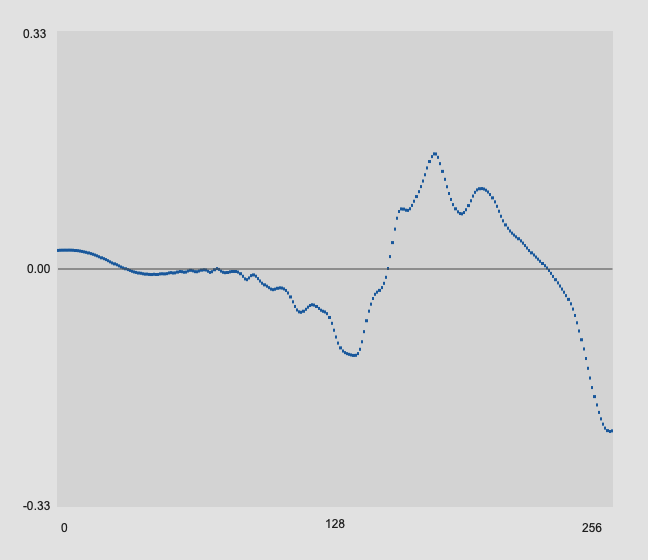
With all these onsets, the 256 samples plotteed here are the samples immediately following where the onset is detected.
You can see how what is captured in those 256 samples is pretty radically different based on how far from the sensor you are, meaning that mechanically and and sonically identical hits could produce pretty differerent analysis results given where the mass of energy is placed in the analysis window.
So my thinking here is that if I want to capture an accurate image of what a certain class is, it may be useful to augment the analysis at the point of training where I still use onset detection as I’m currently doing, but rather than analyzing just the 256 samples after the onset, I additionally analyze a hop (64 samples in this case) ahead, and another behind such that each onset produces 3 “real” analysis windows.
I don’t know if that technically counts as data augmentation as the data is “real” in this case, but this seems to me, on first blush, to be one of the most significant vectors for capturing a more comprehensive image of the audio I’m analyzing based on the stuff I’ve read/watched.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Onto some more general thoughts/questions, I’m not entirely sure of best practice here overall. In my case, for classification specifically, I have a training step where I typically do 70-100 hits of varying positions and dynamics, which seems like a decent amount, and up to this point has worked fairly well.
With this scale of entries, I would imagine I wouldn’t want to augment the data to the point of having an order of magnitude more points, with the bulk of them being synthetic. So I imagine there’s some kind of voodoo/best practice/"it depends"™-type stuff where you take a subset of the entries and augment them in a subset of amount of ways, but there’s so many variables and permutations that I wouldn’t even know where to begin…
@weefuzzy also mentioned something about generating new data from the descriptors themselves, which obviously simplifies a lot of things since that can happen on a set of already analyzed data, whereas the pre/post hop analysis I’m proposing above needs to happen at the time of the original capture.
But in general, at the scale of audio and data that we’re typically working with in FluCoMa, how viable/useful is data augmentation likely to be? What approaches are likely to be most useful here? And more practically/pragmatically, how to best structure/save data with datasets (do you keep real and fake data separate and combine to fit or just merge it all from jump, etc…).