I keep thinking about what kind of interface to have for this… obviously if deleting all, clear is the way to go, but to delete a bunch is more complicated…
I have an idea, based on datasetquery: maybe there is in your dataset a value that would allow you to select an interval?
Wouldn’t that add significant overhead to big deletions though, because you incur a copy? That seems to be in conflict with the spirit of the feature despite the interface being fairly consistent.
I feel like a lot of the dataset world could do with its own grammar slapped on top for manipulation (all in place).
I have a great many opinions, which aren’t all consistent with each other. This general point has come up internally a couple of times – I certainly remember @groma flagging it whilst we figured out the basic design.
My general feeling is that it would possibly end up with greater divergence between environments, because what constitutes a sensible grammar is going to be tied to what’s idiomatic within that environment.
So, in Max (resp. PD) the established practice is for idioms that involve joining boxes together up until that becomes too clunky, whereupon we get ad-hoc solutions like expr, FTM, odot (plus js stuff) for expressing things with symbols.
SC, otoh, is already symbolic, so the practice there is to try and make things work in the functional / OO idiom of scalng. I’m not aware of any ad hoc additions that propose new grammar-like constructs (besides the built-in differences bewteen code-in-sclang and code-in-ugens).
As you all know, I really do not fancy divergence between environments… but then what I like vs what is better for the project and the community might diverge and I’ll always pick the latter
Yes, and what I find most frustrating in my experience is additions to languages that break convention or are against the spirit / zen of the language itself. Speaking from experience with different paradigms sklearn is an excellent example of a whole ecosystem which feels like you are coding machine learning in Python, whereas something like the Python ReaScript API feels awful and far away from the design of the language. It’s a real barrier in the latter to thinking creatively and tugs at your attention all the time so I definitely something that is worth getting right.
In light of that, I think datasets perhaps need better ways of accessing them programatically that is suited to the language or perhaps better documentation for those kinds of maneouvers people might want to do. Without being the total fanboy of Python there are numerous ways to access data structures depending on the task at hand.
Do you need one thing from your ‘dataset-like’ object?:
x = dataset["label"]
Now you have a speedy pass by reference to that vaue (no copies)
Do you want all the keys from a dataset that start with drums?
x = [dataset[x] for x in dataset.keys() if x.startswith("drums")]
Do you need to do something horrible to your data?
for key, value in dataset.items():
if "modular" in key and value < 10:
yield value
I’m not sure what the answer is, definitely Max is going to suck at constructing these kinds of accessors and queries but perhaps SC is a place to think about these types of manipulations initially followed by a whole load of JS spaghetti for the visual-ites.
Perhaps another set of lightweight objects that perform primitive dataset commands would be useful.
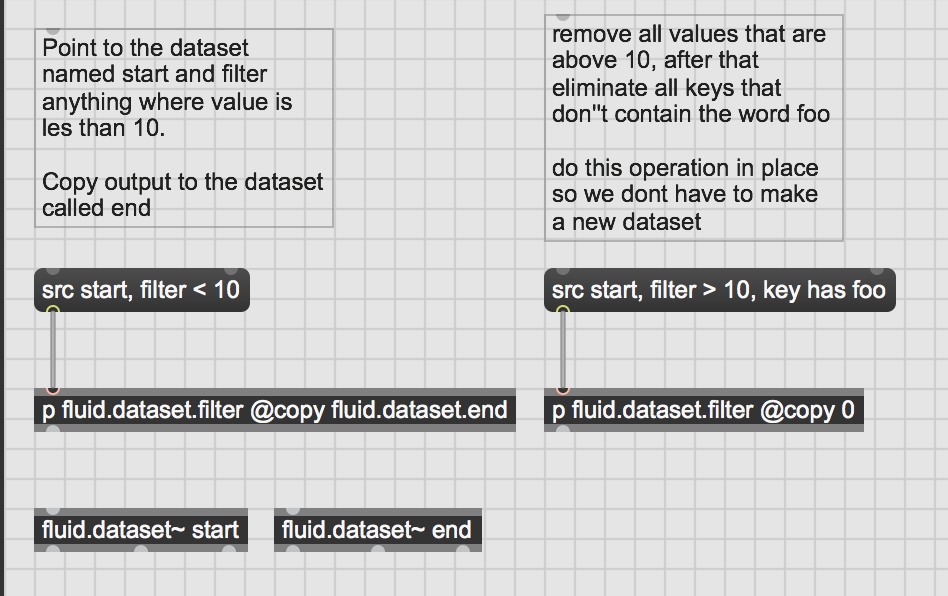
Here is an imagination of how that might look disregarding all possible problems this entails
Honestly, the barrier to datasets is the only thing that stops me using them more and prototyping stuff elsewhere rather than Max (which is where I prefer to test out things dirty with audio to boot).
Thanks for the thoughtful post. Without having tried, it looks as if fluid.dataset.filter could be implemented as an abstraction around fluid.dataset.query (to the extent that they actually differ). Differences I see in above (having barely played with dataset.query)
your filter op can apparently apply to any column in the dataset
what’s the key here? Is it the label for a point in the dataset?
you’d like in place filtering
How does your object know when to process? Does it do it both after the filter message and then after the key message?
Yes, but that breaks the whole system of having columns of equal size For anything with a single column this way of thinking works but perhaps it would be ‘disabled’ for anything where len() > 1. This requires more thought.
key would be the label in the dataset, so the bit thats not the values. I can’t recall what it is referred to in the current documentation and help so excuse me if that’s incorrect.
In place would solve a lot of headaches with making new datasets where you don’t need to retain the original. Less boxes == less debugging ( for me ).
I didn’t think of this, but I made the assumption in my unconscious patching mind that you would send a message like transform to get it going and a composite filter would be constructed under the hood from the various ones specified outside the object. So in that case it would create a filter that would remove anything with a value less than 10 and all the names that don’t contain the word foo. I don’t think order here matters but pragmatically it might make sense to a user to think about removing the most coarse things first and finer things later.