Ok, here is an early test/results. At the moment I’m only matching on 3 descriptors (loudness/centroid/sfm) since pitch isn’t very accurate/consistent (more on this below).
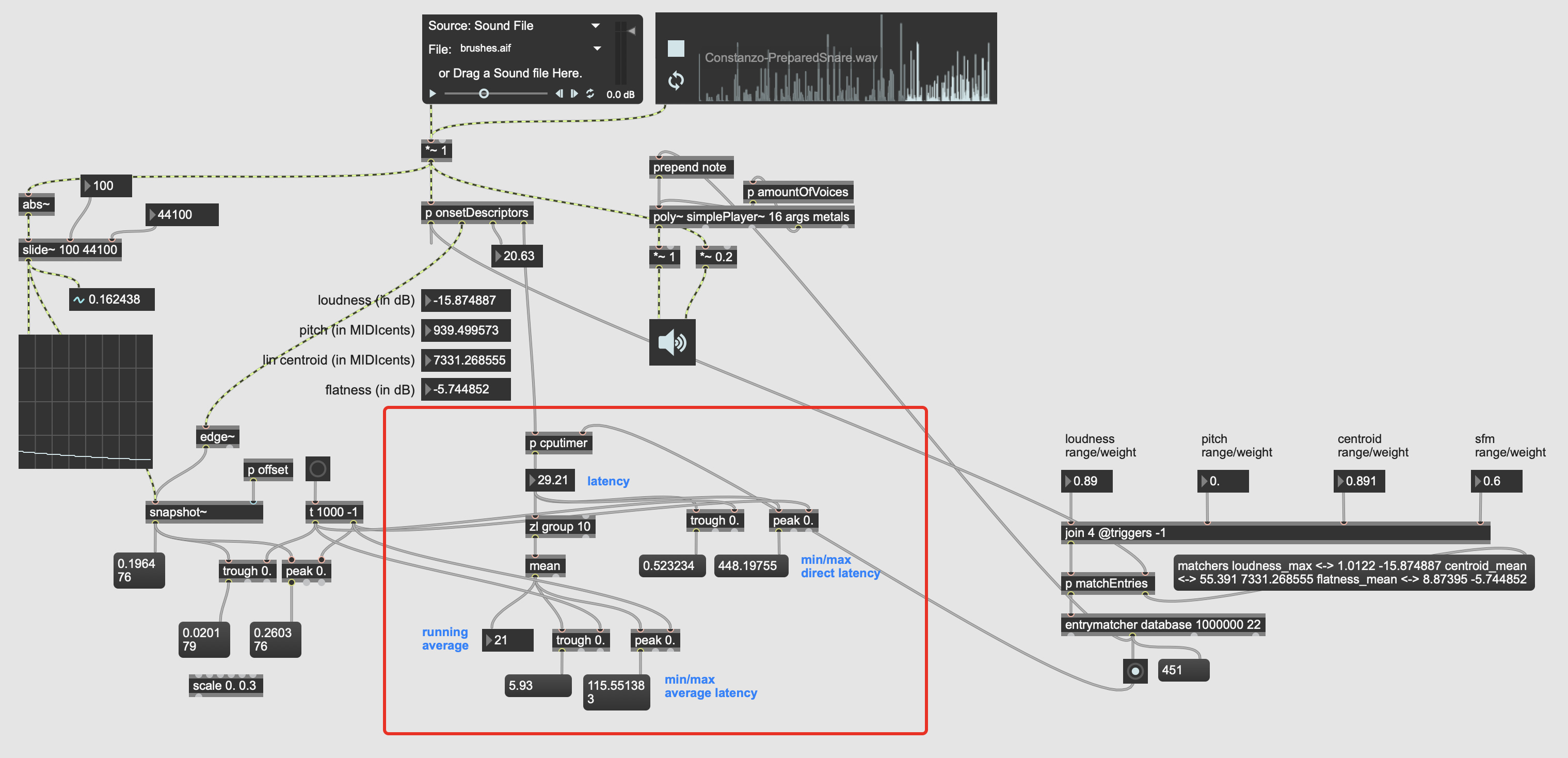
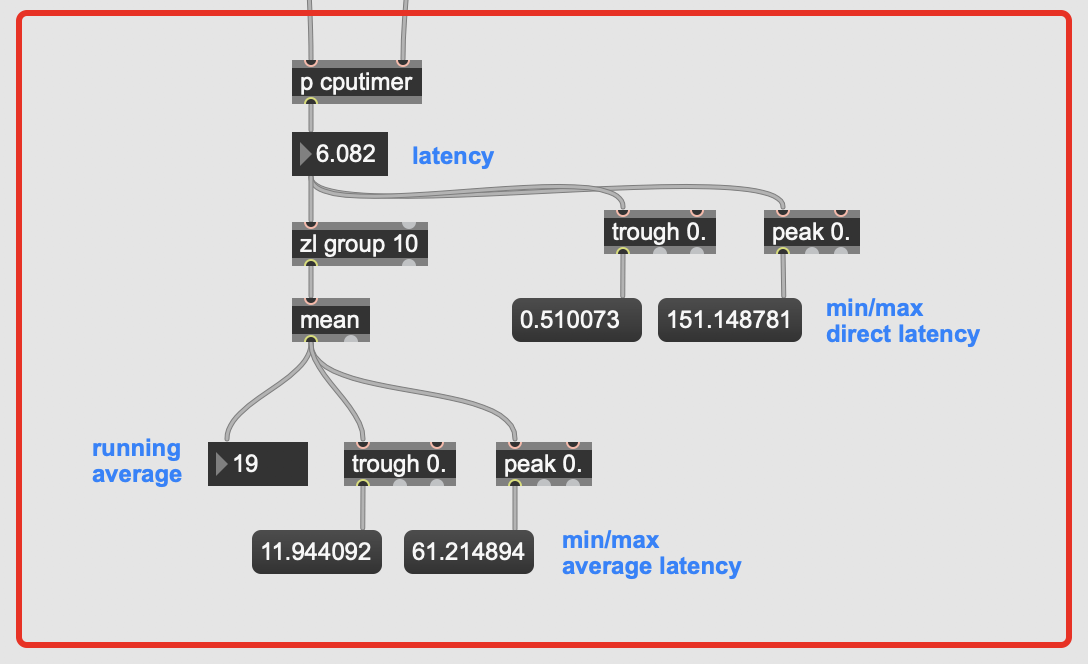
The patch is messy, and the rest of it is still pretty big so I’ll post some patch once I tidy it up, but here is the relevant bit of patch, and I’ve thrown a red panel and labelled the important section:
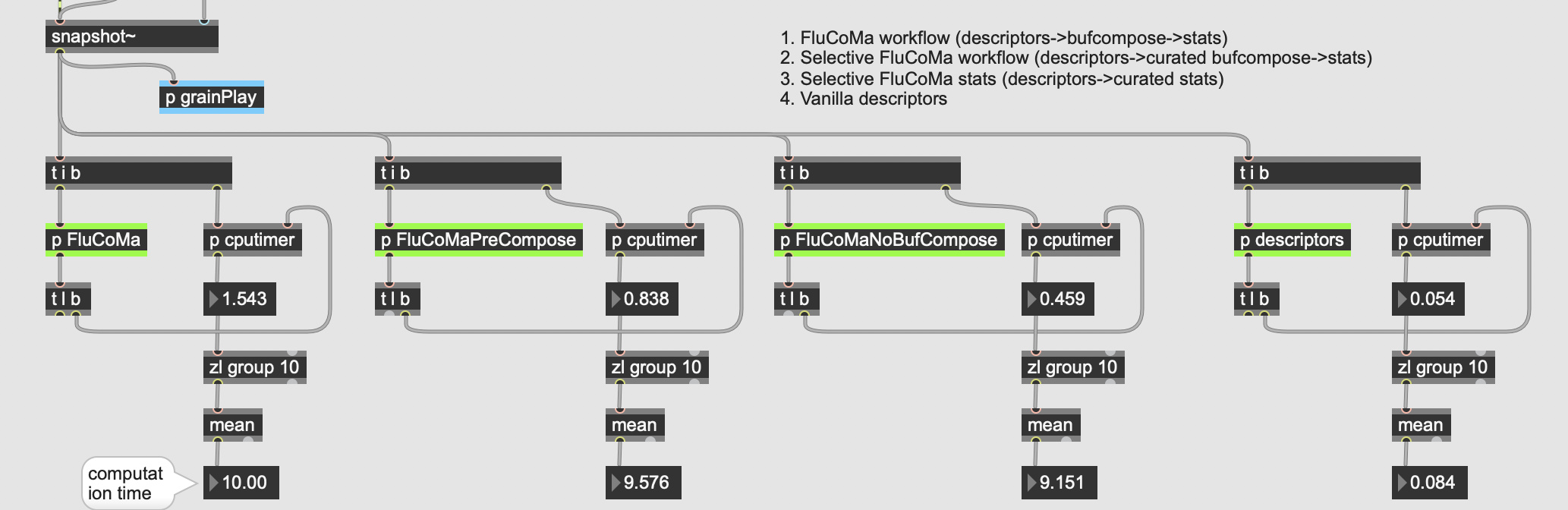
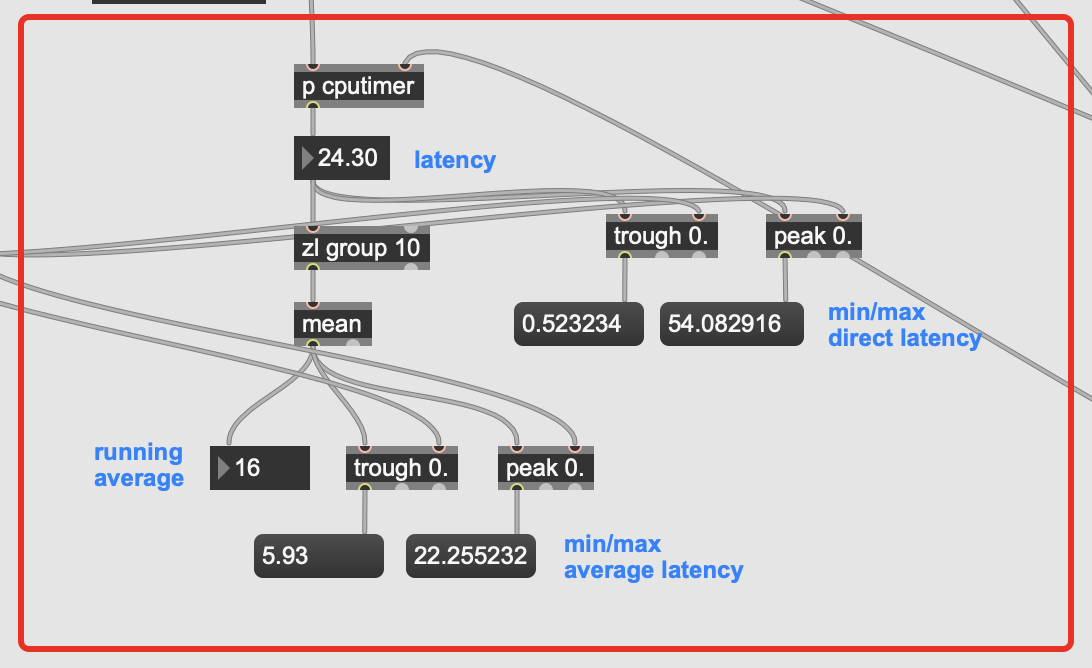
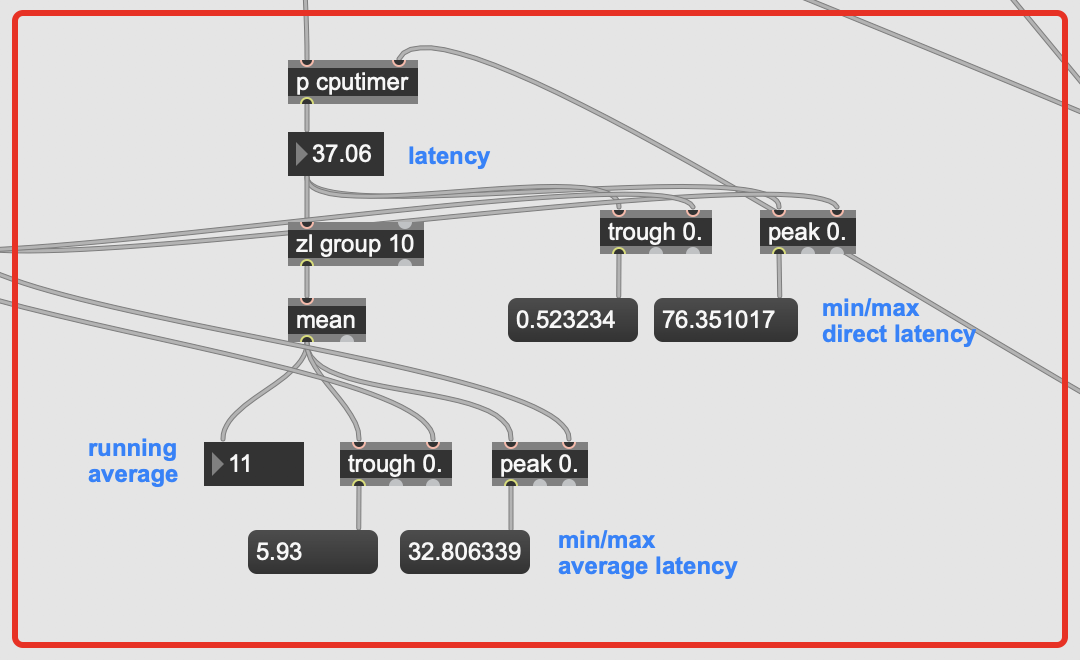
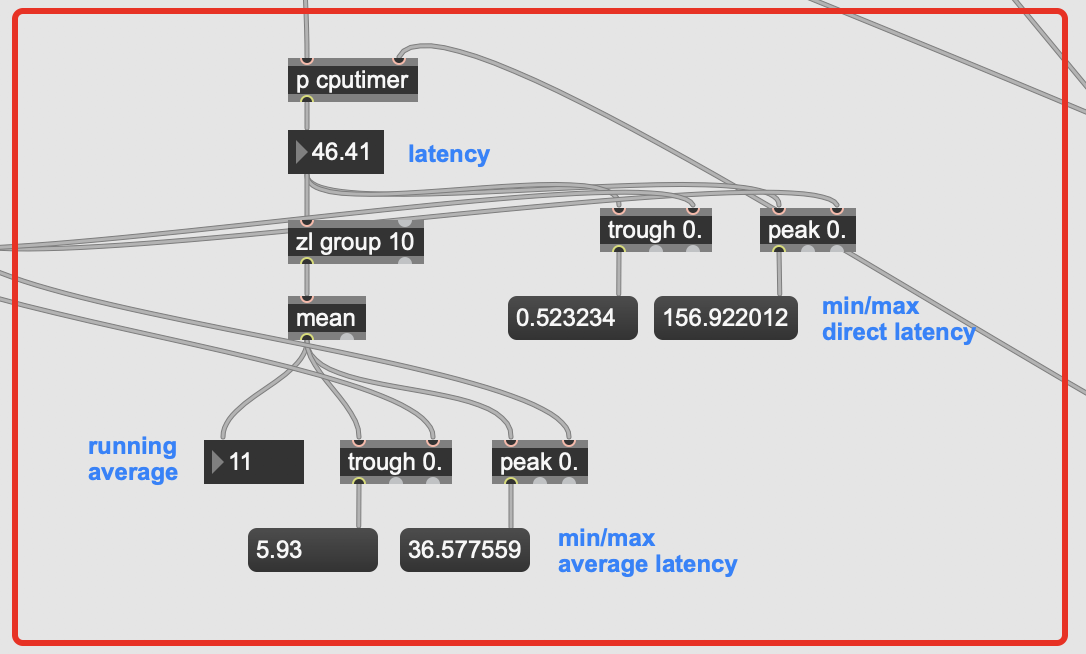
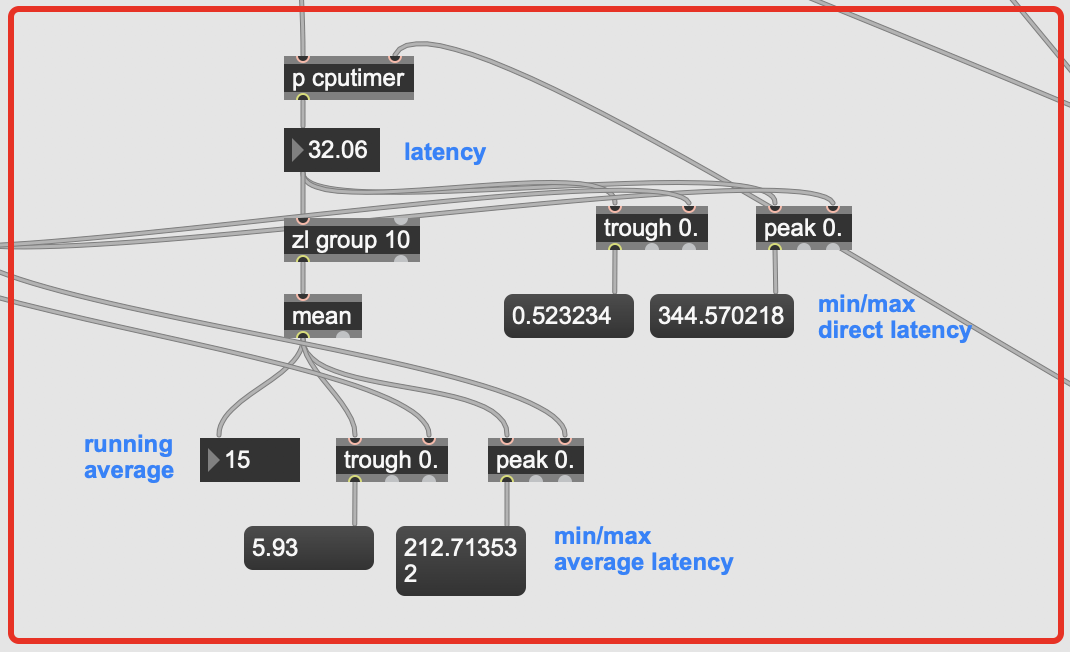
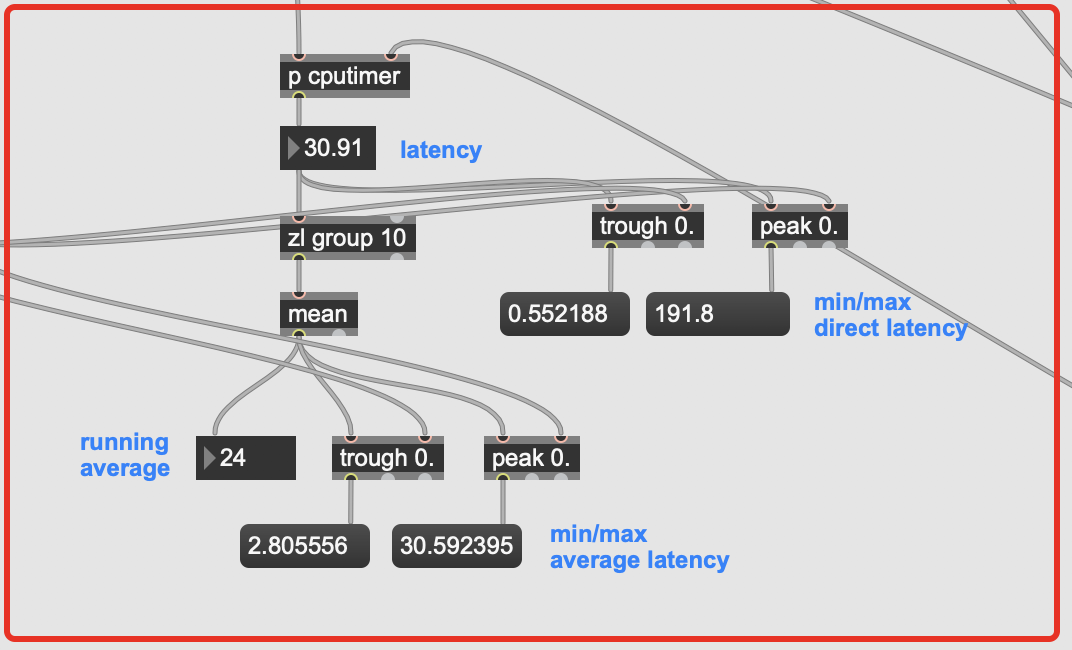
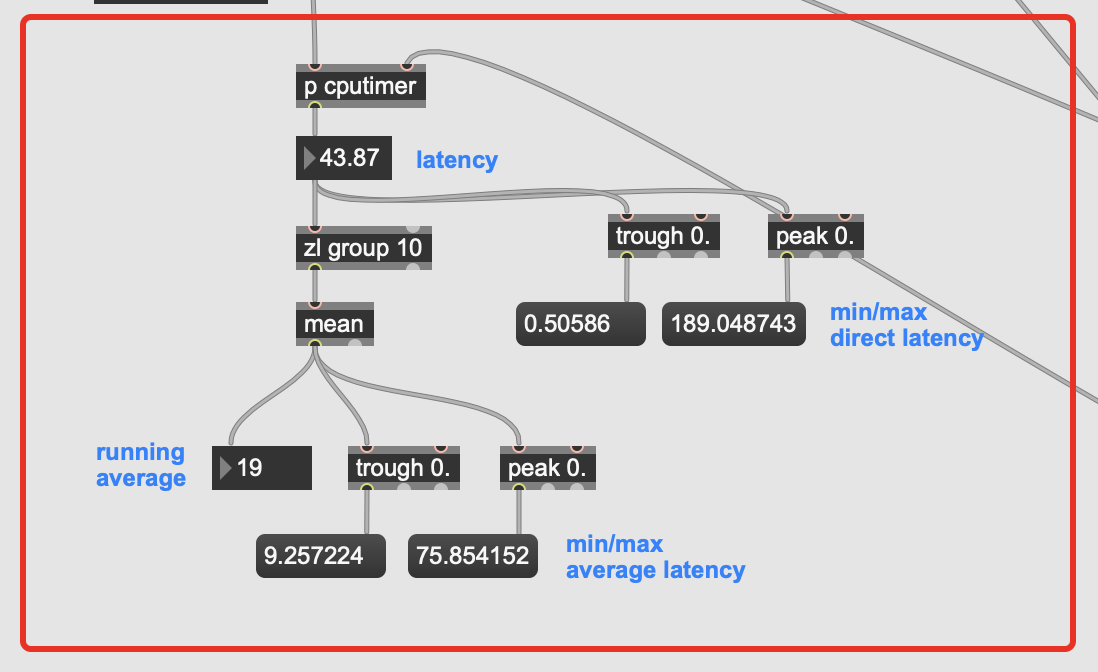
The audio file I’m playing is about 40s long, and I left it going for about 5minutes just to be thorough on the min/max ranges. The timing is between when an onset is detected and a result is returned from entrymatcher, so this includes entrymatcher latency, which is nominal since the database only contains 3094 entries (vs 100k+).
You can see that it’s pretty fast on occasion, but there are spikes of up to 500ms latency in the mix, with a pretty high average spike as well.
Sonically it’s kind of hard to tell on my laptop speakers since the audio files I’m playing are flurries of notes anyways, so I don’t really “hear” the latency, but this test wasn’t designed to do that (though I’m certain I would hear that 500ms late example…).
///////////////////////////////////////////////////////////////////////////////////////////////////////////////
Part of what I want to test/compare as well is the “accuracy” of the fluid.descriptors~ objects, but that becomes tricky here since my corpus and JIT analyses are looking at very different things.
The corpus is made up of robust stats across the length of entire samples, including statistics based on length (duration, time centroid, amount of onsets, etc…), whereas the JIT stuff is looking at 512 samples and a limited number of descriptors and corresponding stats. So accuracy is more like “accuracy”, at best. A perfect apples to orange-shaped-apples comparison.
This is inherent in this approach though, as I want to analyze audio now and have results even now-er, that there will be a tradeoff. Hopefully in the future (toolbox2) I will be able to stitch together bits of audio ala multiconvolve~ so I can get fast and responsive analysis and matching, but there will always some kind of projection required if I want to trigger longer samples from shorter inputs. (on that note I started experimenting with creating a time series of descriptor data on a microscale, which I would then stretch out to apply to longer-than-the-original target samples (i.e. the pitch contour of a tom mapped to a long string gliss)).
From what I can tell (listening wise), it is consistent though, which is important. The opening onset from my audio clip always triggers the same sample in the corpus. I don’t know if this is the case throughout, and perhaps it’s worth testing to see if I get the same exact results each time the 41s sample plays through.