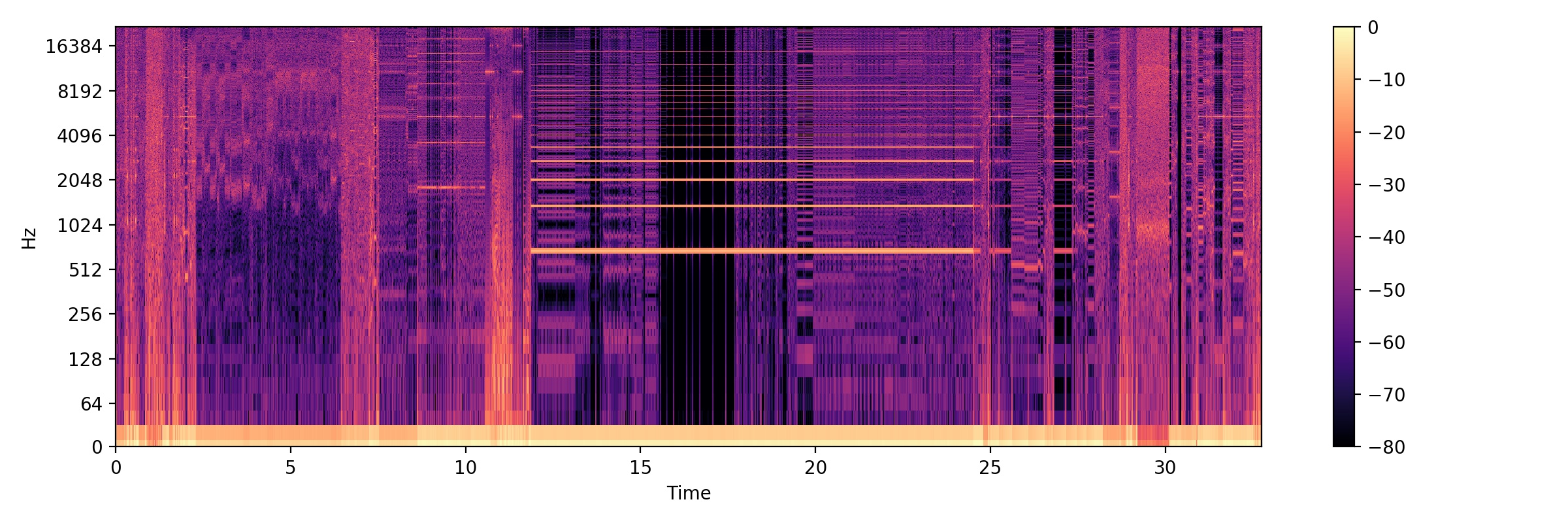
I am trying to segment some pretty onset-less audio. Below is a lovely mel-spectogram of the stuff. The audio in question is this file here - beware its very loud so turn down if you want to listen. libLLVMAMDGPUDesc.a.wav.zip (229.2 KB)
To me, there is some quite interesting visual differentiation in the melspectogram that correlates to the different motifs which I hear in the audio file as a whole. The question now is, how can I get the computer to look for such changes and return me a bunch of slice points.
My first inclination was spectrul flux, fluid.bufonsetslice~ @function 2 to look for differences between successive frames but it seems to be very hit and miss and to detect some of the minor changes but not the major ones.
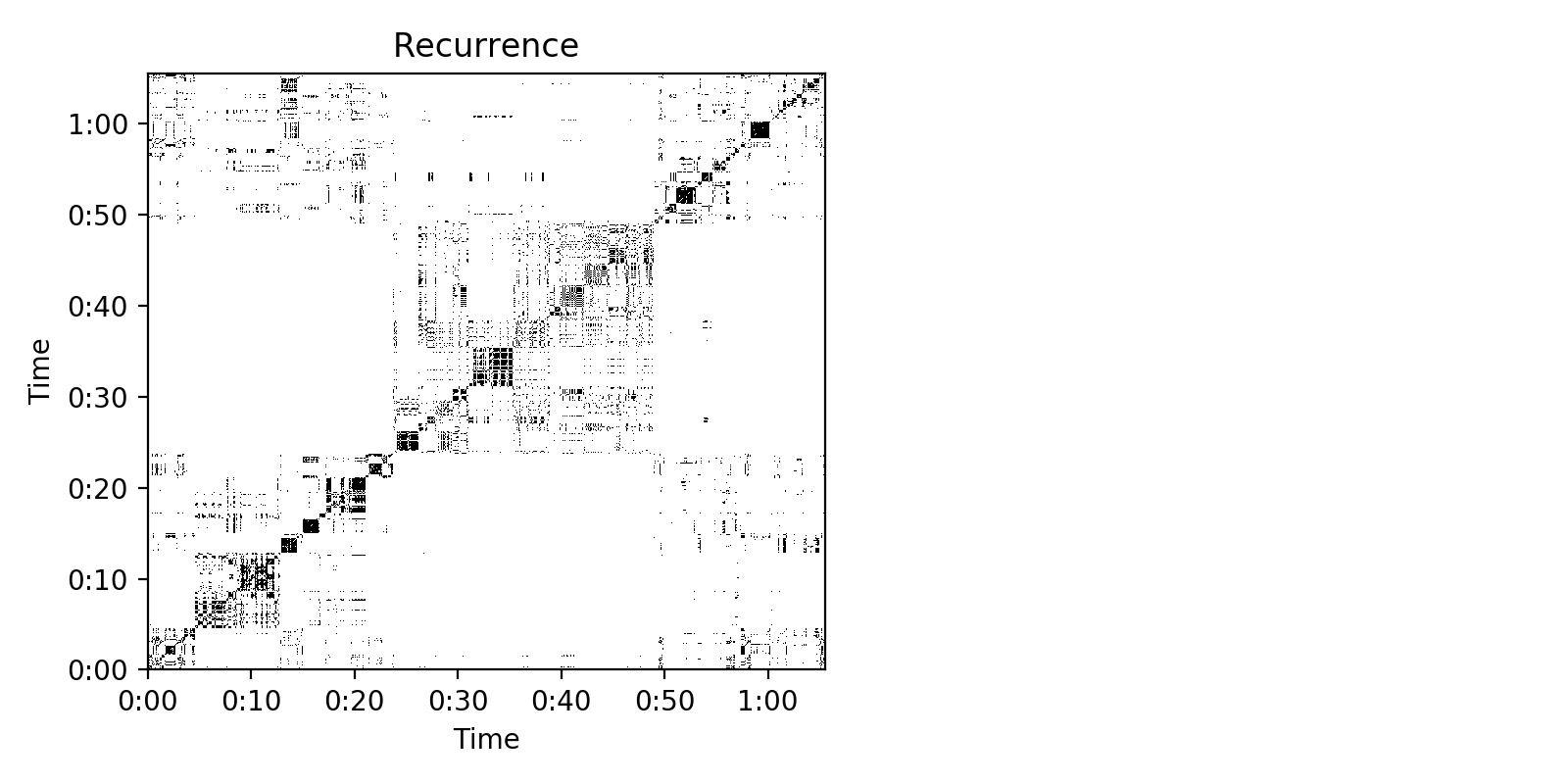
I’ve been looking at things like self similarity between frames, and constructing things like recurrence matrices in Python which returns data which looks something like this:
Its fairly clear from this that there is some degree of representation for what we can see visually and it might be interesting to segment this data to get some times back. At this point I am stabbing int he dark a little and playing things that are beyond my technical understanding.
As such, this brings me back to the fluid tools, something that I think has more flexibility than the Python analysis and is more transparent to me in what it is doing. Any ideas @weefuzzy@groma@tremblap on what tools I can investigate further for pre/post processing such wonky audio to achieve some sort of segmentation of motifs?
noveltyslice~ is actually pretty good - I’m a dummie for not trying that next.
So is novelty in fact some level of difference between the spectral frames, or groups of spectral frames? I get the sense that it somehow correlates to the separations that I see in the visual melspectogram.
This is encouraging Novelty is calculated using exactly the kind of recurrence matrix you posted above. Imagine sliding a small square across the main diagonal of that matrix, and adding up everything inside: this (give or take) is how the novelty is estimated for each frame. The bigger the square (kernel), the longer the temporal window that novelty is estimated for.
So a further question: The kernel size is how big your square is temporally, so up the diagonal of the matrix. What is the general shape of the box outwards or is it a little less straightforward than that?
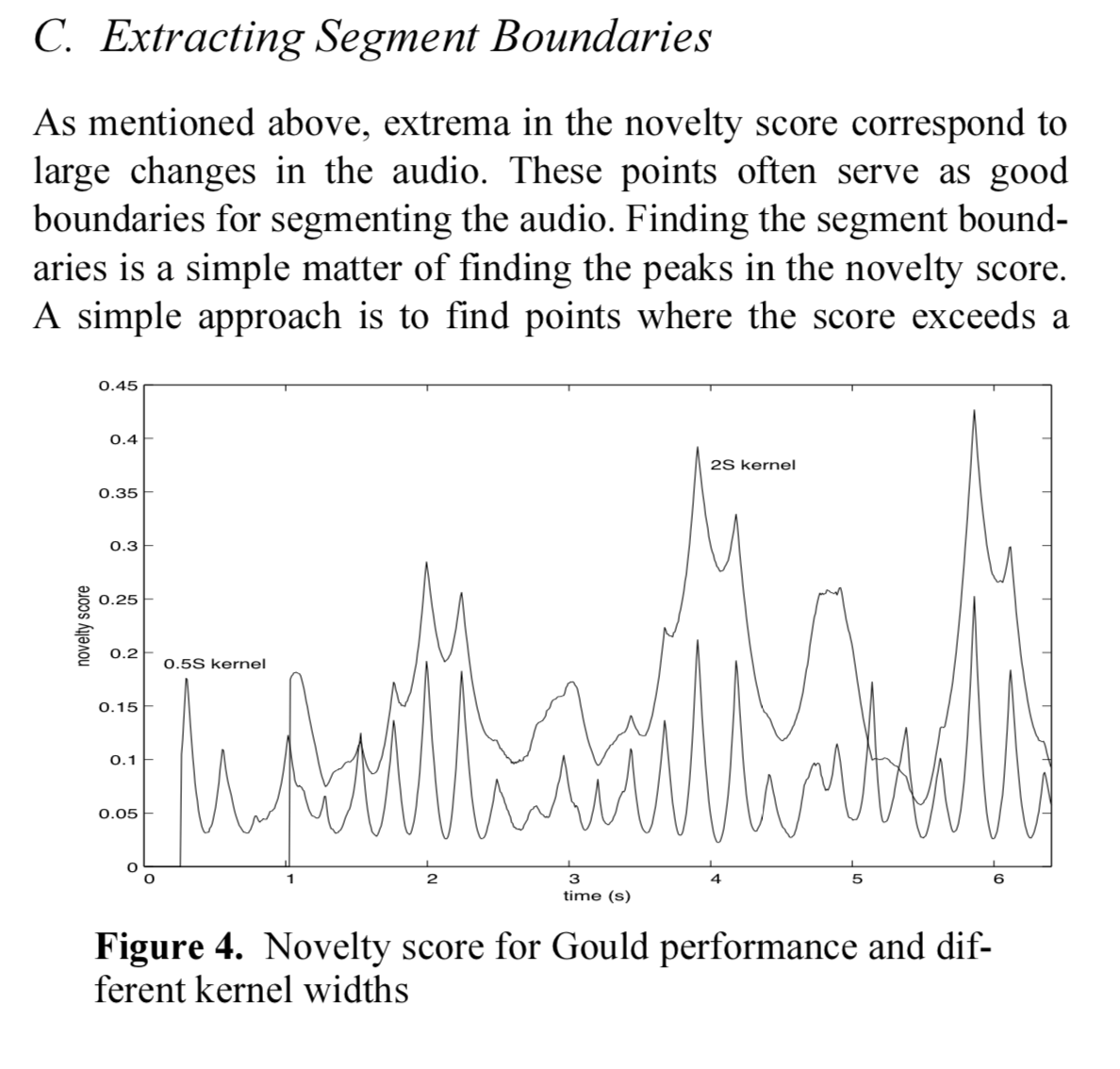
It’s the edges of the square, rather than down the diagonal. Here’s the paper the algo comes from, which will make it clearer (as well as explaining that the kernel is indeed a shade more sophisticated than just summing everything in a window):
‘As mentioned above, extrema in the novelty score correspond to large changes in the audio. These points often serve as good boundaries for segmenting the audio. Finding the segment boundaries is simple matter of finding the peaks in the novelty score.’
My follow up questions are this:
The threshold is normalised in the noveltyslice~ object. If we had 1 peak somewhere in the analysis, does this mean when the threshold is 0.99 (or something relatively close to 1) it will return that peak?
Is there a possibility that we could have access to the novelty score to create some more interactive slicing possibilities? I am really enjoying the librosa approach of synchronising any number of representations and analyses to improve what we can interpret from the data. It’s a bit more finicky in Max when you’re doing guess and check with thresholds - especially for novelty which is somewhat abstract.
In bufnoveltyslice~ the whole novelty curve is normalised. So, I guess, yes: if you have a single peak, it’s maximum would end up being ~1. However if the curve is very noisy, because there weren’t any outstanding peaks before it got normalised, then the the difference between 0.99 and 1 could end up capturing quite a lot of rubbish.
For the RT version, we can’t normalise the whole curve, obviously. But I think that the maximum is predictable anyway for a given kernel size (because the distance function should range 0-1), so we can normalise against that.
I believe that this is our ambition (same for the other slicers)