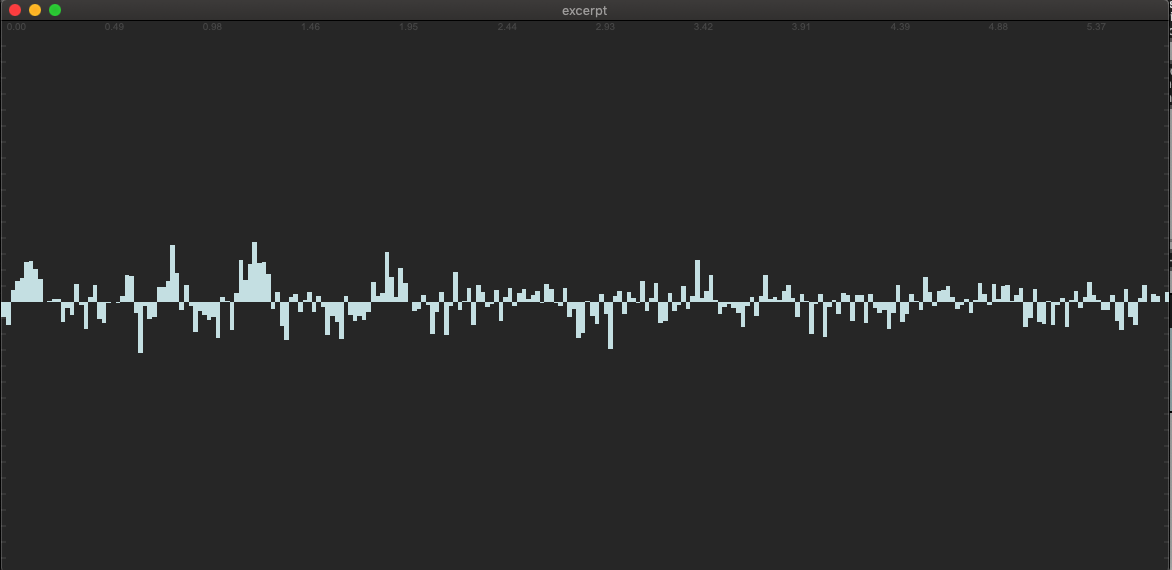
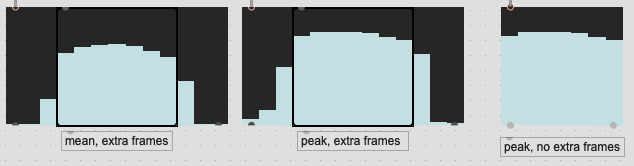
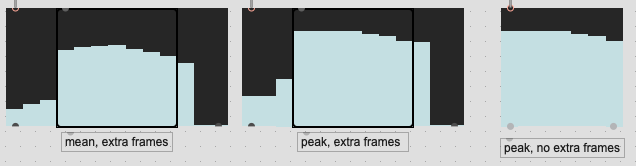
I was thinking about this again today for a couple of reasons. One is how having a pipeline-like workflow might be made a bit more complicated if I’m fussy about what frames I’m taking (since I’d have to scale that up/down with the @numframes), but that it’s not always possible with certain types of analysis.
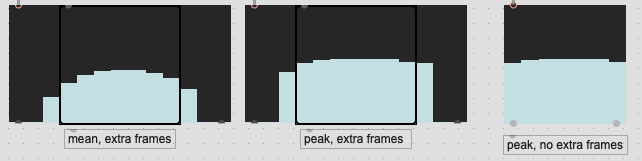
What I’ve been doing for a bit is what I describe above, where if I’m interested in 7 frames of loudness analysis, actually analyzing 13, and pruning down to 7 so that the overlapped area contains “real” information vs being zero padded. In the tests I did above that seemed to produce quite decent (visual) results.
It then hit me this week, while coding up the LTEp thing that I can’t exactly do that with offline file analysis. Or rather, if the files are sliced tightly there is no “real audio” before the start of the file anyways. So for the sake of consistency between descriptors, I’ve since dropped the my semi-“workaround” for the lack of mirrored frames. Bummer, but I think having more consistent matching/parity is more important than one side of the equation being “more correct”.
Somewhat related, although not the exact subject of this thread, is choosing which frames are analyzed. I’ve always done all the frames for loudness, but then only the “middle” frames for spectral/pitch stuff, based on some discussions from the first plenary. Now that we have weighting, I think that somewhat mitigates the possibility of skewing stats around by funny stuff in the edge frames (though not entirely since loudness also gets zero-pulled). That got me thinking about the scalability and reusability of different analysis pipelines. The demo code in the LTEp patch is hardcoded to 256 samples (7 frames with “middle” frames for spectral stuff). If I request a larger amount of frames, my @startframe 3 @numframes 3 thing doesn’t work anymore. I could programmatically have it such that I always ignore the first and last x amount of frames based on the FFT/overlap, but that’s getting a bit fiddly, and has ramifications for buffer sizes down the pipeline, particularly since things like @weights have to be exactly the right size.
So this is half comment and half question in terms of the current thinking or temperature on being selective with the frames you choose to apply stats to within a window vs letting weighting process that for you.
Don’t get me wrong, I still think having a native @edgeframe option would be handy as I think, for short analysis windows in particular, that having mirrored windowing would be ideal, but for now I’m wondering how useful the results are vs the additional faff.