Ok, I’ve realized I did this all wrong…
I’ve been mirroring the frames of anlaysis I have gotten back, and not the audio which is being fed into the analysis, which is what I think actually matters here.
I went back and tried to mirror the analysis frames I get from fluid.bufloudness~ to try applying the loudness weighting for spectral descriptors ideas in a slightly different way. At present I’m taking all the frames I get from fluid.bufloudness~ and then the “middle” frames from fluid.bufspectralshape~, to avoid pulling things down with the zero-padding, which the mirroring I tried to do earlier in this thread was getting at.
In doing that I discovered my stupid oversight here.
In terms of edge-case handling, I think for loudness I would be better off including the material before (and after) the desired analysis window as statistical “context”, and to not pull down the averaging with the zero-padding at the ends.
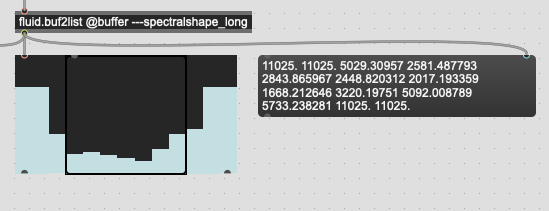
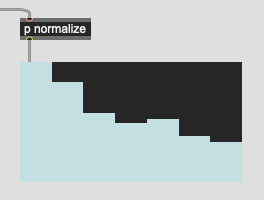
So I’ve made myself a handy chart:
Each cell represents 64 samples and the darker green area in the middle is the window I’m interested in analyzing. The rectangles underneath correspond to the frames that are being analyzed with a hopsize of 64. Using settings of @windowsize 256 @hopsize 64 @numframes 256 gives me 7 frames of analysis, but with zero-padding where the light green is. Given that I’m mainly analyzing percussive sounds with sharp attacks, at present this really flattens my first frame since it’s mainly filled with zeros.
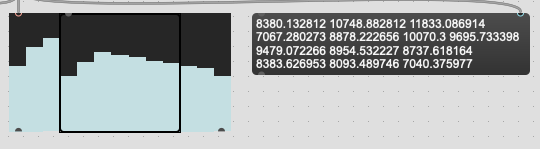
So what I’m now doing (patch below) is accounting for this by anazyling a larger window than I’m interested in, and then discarding the frames that fall outside of these 7. So I have the same total number of frames, but with “audio” in those outer frames, rather than zeros.
In my case here, this involves analyzing 640 total frames, and starting 192 frames before I’m actually interested in analyzing, and then discarding the first and last 3 frames before taking the stats.
This gets philosophical here, but I think that “what really happened, but outside of the window I’m trying to analyze” is better than “exactly what I’m asking to analyze, but in an artificial vacuum that never happened”.
So this works, and gives me what looks to be better results (not as “droopy” for the first frame), and overall higher mean, which is to be expected. The 1st derivative is a bit more dramatic in the difference though.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
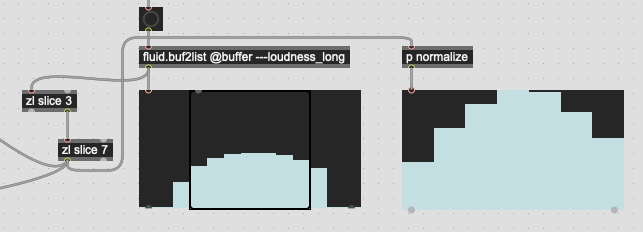
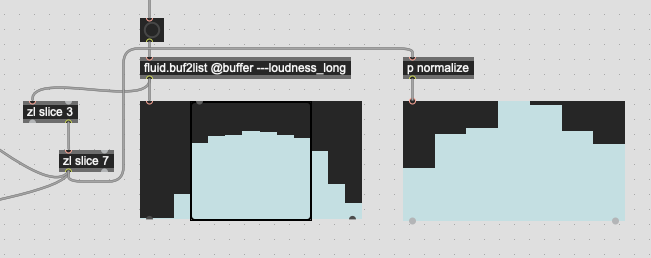
Thankfully, for what I want to do with loudness, I can just use the existing @attributes and a bit of math.
Where this gets trickier is trying to do the equivalent for spectral descriptors, where mirroring would be (IMO) ideal.
Now, I can manually reverse/mirror 192 samples on each side of my desired analysis window, and then follow the same process above, but that would be time consuming. As it was, mirroring 6 frames using fluid.bufcompose~ for the examples earlier in this post took a whopping 0.15ms, so doing the same for 384 samples will likely make things too slow, particularly since it would be 384 separate operations in order to do that.
I’m certain this has been mentioned in the past (though a quick forum search didn’t turn anything up), but being have to reverse material with fluid.bufcompose~ would be a super welcome feature. Both in general, but also in specific cases where you want to mirror audio for analysis purposes. Even better would be an @attribute for the kind of edge frames you want for any given descriptor.
I know @tremblap very much likes the zero-padded analysis windows, but given the flexibility of the tools, it would be great to not have such a “curated black box” when it comes to edge frames and how to analyze them. 
On a more serious note, is the a better way to mirror audio for spectral analysis that doesn’t involve manually reading/writing those samples one at a time?
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
edit: I was taking stats of the peak and not loudness channel.
----------begin_max5_patcher----------
9453.3oc68r1aiabsedyuBBiBbauWuNyCNyPteZaRZSAZ11Ec2hfhzBCJIZa
FSQpRRYuNEc+semGjT7wPxgRjRZCjQhWZN7wbd+XN7L+mu5UWsH9S9oWY8Fq
ex5Uu5+7Uu5UxSINwqx+6Wc0ZuOsLzKUdYWsLd8Z+nrqtVMVl+mxjm+0LPw4
13ks7gfn6uMweYl5YiQ2.t1xgXeCCRYNHW4ONjqsPXwHPma.V+q76OZ653sY
g9Yx2HH+rAqjum3E+7qQvhW0cwQYoA+huXHH3FvtmPPTwC.JN2+8q9Jwut9.
gxdgQp.RX1RPE5tGfEZtAq0aCyBRCCV4mT7pJdMrtALBSAXN0HdtTaN0CofV
NfhcYTJE6Z6Bro.6RvN0OiOq4SC0CiymHtCPmHFzt6KM6kPENH+bpKK6kM9p
G1UWcM++KePUwk16nTIdq8y7St0Oxag54M67IlHMP4bJShz.37UZffA6qz.j
M2fk+urxa4m6AFP.E4f5dCh55.P1LByAxfrqsrIhgD+dDfj6U5l6n8XtuPNc
2IF+Tf+yOEjFrHHLH6kZxL2cGWTJW3yVLoeMtxjNLd4i9qVk3ce5xj3vvpS8
kgAKeL6gj3s2+P0yqDjdn8MnF3o1Cr390wqpI5sHNQnEpxYzo4QxDgn2HDMT
LQNtchw6TKQZv8Qdg6zSDwUHHwhq7WGmFuMZ0MbjK+8ekFZlSwI8RtO2R4Uu
8t.thDttmEIaSevO8Fuf6D+4aCii2vO.JN9o3P9g0lr6n4f8fluIz6kvfzrR
V13jf6C3PVl+5MwRL.Zm3wBuzfkYai3XTwP118fmQNtUPzDIqMC0Ihlje1BZ
p5cUJHEve9KiSDO9f3npj363rEwOeeX7hJSZv.jsq0ej3+WEHeEdIuri3lEr
1OMKwmOITOmcPwcwIq8hxzO2ppQ0DaGbgiMO3Gb+CRbHCVh3KnJg9Q2mULGD
XT9Ta4io6lo+6sdEBq0wf00rkexUdYd4LG4bGp4Po2aUFPvstHMNbalOmZKm
CW8NukAQYwoOX8m9t270+8T+jzuNIdEexF+0e3knke86Sh+YNZI8q+iga+13
2480uWphI8q+XbbHmyzB90eabTZlWzuD+52mvexI9q9.G46eyydOkO2knYtv
QoHl42xiAQJRf21UAwJIrxKHm5rkg...WYLrxXRgtcXJIhgaxfaw5V9qNyu.
qUE+zGehx8ivsIhKoj9UaTsbRMeDlxHrSpI8gf6xEIg2n+gUJ17SJo8ddiqS
0O4anY3mD5FpcAEx0+TAeY6YZ+PdN5QOjnUIPKz+Fe+U5u+JhMUlfEiK0opN
H+jpyLRcsQ9Oy0DTZc0KojgVxc964H4WRCRa4RzFKsi2osMnsFeKbktcfPi2
R2cgwbqX5bHFtyPlV0KE9SzPCiPL7ItphbBcgH1Uda1T4z0js3HxeNV9fbtt
7TAQpSUJidUhuveE08yJOqWBGOkwQRaSTn6OQsuZ2igyXlDsMnziOIIsTYHm
3IHSoa7VlaWhSiKFth0NnzMHGULoJOTEgltiMi6uhxunJJ74X6M9bYlMI9ob
UKdMrevUP6emGO9paq4tJ5FsieW9LT6fkrZ+9j.gst7K49jfUwQhIQMJg3zE
uNtvhz1MjTEXjWQj2FM2LmyPnxW+fBkmaSW3kHcrTY8CULXlvnPsgJuuP+6x
xGdSPTTCrXV7ltGLQXOs6gWDyGbceOa4Ho2tMRM5sbdBtU.umpisy3pHykvq
+3+jWTvZtIiBM+bqMEC1xoWX8QdRyHq373K8eNXkR8OnJy.+xC1TvDcUIUdU
v8byR0OWlmxyycmoLx3JmZaQLA2JzpFla3a2EvkN3NOl9P7yo4WXAiVUDfeG
9SrScYC6n0SvfeZp28ULbWQ0HFBIvapNjFshPhTbjPkp.U+QUEgcqLriDDT6
FqnOjbU8GXivwZXJ458DenlOC.ytNxzAPbugV4GBj6KtR4DFzKB.nGBQcBgU
wXEw1WkUQ9fhV4+oJ5YmDzQMqp04NtKbavpa7VuIkGzo+msd6CbUAa323cI9
+agbHv5sbqawIVulP3Gxkq49luY6FK7t+ZU7yQVXG9YR4tXjONBAH6Ng7RTm
hiQjuLk2RVPtMXq2x0+9.WC+CwgqrfP9ee2c6NQMllvfH+k7fGkyeb+jXrsJ
OHbKOUowTj60V1.I821sWhLpOt7JQE0E+NratgIj.WOSQ0ovbqlqrR4jfPeK
I2kUVrUgdPNc0qtOSswwngTcnviTvM1tU9wFyQ7Ho2VX79HHAQmbb2ydAYVY
O3akyqFeWI5x5YNxL948FqwjdLfQPMXM.4.vZfSNVSJyViiyiiE4l1E3Odbo
00LOJrlijWCwQdvpxyNTAVyc+wZNmbjlL9EN5Zy1grawsmeCWvBwiZA6v+Mh
HTlIskIWw.zdY1BeTv.8XIZiUdJSG.5wxnHrgMLayP7S5La9s3zM9AzbBuKb
t5nhNCqqqP6Zb65Bwqiv75NTugC2qqP9pE1mAg90L7OTdj2x+wNmVY2fYUeL
fFDGnIwBNX7fFFSXOwEZVrgCDe3fwHNXbhCDq3vwKNXLiFD2nIwNNl3G6IFx
Aiir+XI6Odx9ior23J6J1R8wW1QLlFEmogwZpOdylJZZpNu03CZXqtt8+PTJ
WSSJ2UJtm.BVZ9TL6yVYdOJOI2+JN8tvkAtSBhS8Dm6m6dJ2YUumhCVIbffa
IvJHMcqe5MMeUcEUPmK8BzovaAw5jJMeZyZHh1qwy9h6qGin0LjV2X5gREZY
bsgA1D+MhXAZYlsSSs4qCKRrf41TnsC0ARsATjHwc5L01u4VCL41DoxbO2wp
u1BZNpjwtwgvv.lMOxTGD.C43PW4p+MAXxfnrdQlNfdQlnSOxzakxnlEOx5m
RM.uhI6jhcXFxRhFjk7ZCPlvSNxrUVtFRPlGe.gAc4xxLjCARDBx5S003T8g
6WHswfcj5qNR+kF7Wc2nDZ9GvXlDkHtt9QtowaSVVvCTPisfsvKbi8YAQd6V
EtRoKwposWD98dFBpVqCCLCEJSO5yvhWpQyP7fSvJCVMVjqD9Jt5VkOy25kk
kDrXalhuPWfX6k+Zp0NsgiUc4R2W0F.l63m4B7wIqDKub+gP6nRuOOPZb0eD
odh5dnQP2nneZppvEaT5wuDGcmwQSTKSMFoV9Bnx0Uvk3nuDG8k3n+UdbzK2
ljvGuHR4MwoABTk0BeQnwOmDjk4GwCY9PiNFCgRcL7+wAy0zfrY.FOZEQplU
peNrXkom7n5FBSqOc7cguXHQLbpZuVeR3GG9w9rG+7sI9bIGKOqrmisR4LWQ
qr9mWsJdKWz2Zw16tyO4edkH4MJmRrhi7KtLwhnIwtYOy0DXkFa87CbtV4Bq
8KB9XBDkygmdsHUPI9VAoVdgO68B+erdxKLXk0xG1F8XkmUb9Cvu+TCYOBle
IcjHWtAJ3W0oFRQv9r0qe8qkqOWpbk+ad48aHuCro56xAykGvUzj.nNhDKMY
QrqJ.OQkg6IptxdhaGBP5fqN7x4bjXwA0URvz.8RNB8RN3aH7eDXdGaBf.oJ
F5oIqSChwsgm6r++uVvalDlcwmrhKwACXt.D.5fPBtbmafPHv0FRnt.H.ilx
j9UuzS0ywiODN9yfzBtJcirhx+7zPjHjaPtPpMDgI37zfoUFAanLhsIYl85J
Zox+6gxwHTuN3ufzUsI9Q+JlUlF5m3C3iS+PDWFkS7HpBBgw+gSOcQHBhP4j
OWjgjudrb6RNDB.9zS.9+9rksMmOZhzuwbkhNUQ8b+jPHDzwACwNbsdhuOUi
kbFT8llzI0aJk9RT8lz4zOaAlRJkxxOjGXhn5XpopiaKZpL9X.0ww4Kbpybn
BS4T7ro0hPO20ZIealfnpDJlwqT0Tv1h6ODbPOqoUOoNvnk25nu7fHlcSs5M
iWSl4mIYoBI68ZEtuI+57ZMEcwiX8vDteHV.xi6ZJ5LlYndvYcvpMwb2ayQh
4ksKz4Fa9OPaFylvnNPQwNyGqo2bsutVufxOic34KtQnFVyxGWN0QmuScgXp
wjU.4FYiIA5Pv.DCaK5PI7.pZRVaeccia.GUbiHEEFia5.QtLNTs3g4esw69
k7Ko8nBOBqWiSIy.viacB204mB6BbrA7SJOCf69J2nAffPLFgccyOgXcrPDk
unTnrf9q6mJA0JXi1W24BKznP4RMCGMT9IRWoLuSiyPBb.oJhKAvYFbE0NG0
Uf.H.nKhiUbXtXnCRgkbrI1LaWhiMz0wH1PQfs1MSbGEHY1Hj7uMGGWQ3tsR
9flq6bgobbj.ohsiGI3jwVBFQUc0EFbxPJF6Spb8rGvozcAhJhA4CxBa3124
GsstOwEklQ+XtE2eWPXXIf9pNuRdvx4wVkiVttwv0PVHWaHzQfPvPLCQkGwO
fPzPUxuWXwMyQfbATwsXS4gsPjG4HLFbskl3Rxuczt2Mmrndi.WGkJTr3TPs
rnu5Jun6yKHDFnYTybVvj3MwIkUPyMX2V2+1r36S7VEjGDSMw+5z650DjpK3
vuK8kwfPClnox07Y1m.SIywOrco29vPTMUGbwi+5Fd3VevKJ05C9qCVDGt5p
9ESrYDHVRxPbACW0QDnThQmBBQJXjOfaChDkzUYSgAgcQPp51K3GPLGardxH
mSttkUtUSlTJkOI3wXHOxF4xjyHBUy8OdIgRp9.BCijgrt3fSoPfCCPbbTG0
Ihno3.kq0RdOxOgNl5H0S7jHMz.sm5Gp50M0PYLgJV4rFRYHkbuC..s0S68V
tzOJq1S.K3ZjXZ6BDfP+icGrg7Yw5lOBlCGeoP7buEbTGweZR+FZqV+HIX+9
eun0KwerfIP7VkKyA7QkHzlqjZrY.IirfOFOVI51wKMjHrRFQ2Q5t8kg9dIU
dBP0KykK8STR.bAHFtq28uNE+G8sejk+qlz5eRl1ZSjtGRo1IQx7QU2e8GEU
K79Ha1j0s1uNQvzZuOQaTlxlBNSjdfFnBtVHSXPT74ktPvxk7NsHRMKHxn4L
3dXw8DF4V0flvwHaB7TCdsaPQGEdkoVucEMuE5VZejAZdYNhXVtV6Qce6+pH
JF8ZMNLtKcqz0dH8H4kpDgYUGYNIRNpUl9aB25+Z39.c578Ex3dpIMJVBnth
SAOC.zj3milLHcG7QJ0EhOSfzu8EuoCPAHdTrJSYLLFozEgfPH9zCneehu+D
BoRpo7iUSE+mvC1SOP9NtksnLuICLcrATpJvVJ.Rk9qvntPWxoGV+G9htH69
Aps8mm3B.NF4yFh.YJqjPGYzdhbtdZ8oOZ65E9Ieeb3pIixyJihlvcOkHgXX
UK6mD.MQE7h.ROXarTawlUQtJJVdt23DRWrQw8edhf1ge1ONgFo1fAAR.yEa
SAt4YmjAIFmfqySrTl2lIHsT+fWVr0On5+6y.bb46Kuquub+U2Wq.769KKWe
uYCYvWVducaS027hlO3j5kLO4T2H6J6uQCfrvtp9loppXp2AHUsJ6C46vu82
ERczD8nzHd6AMs7ANczPNJLCWuWEHx1OgLy8p.tZ3SMuzJ+PuW9rEhPE+uY3
JDsMCkKb1wUNmZFpTuGLiaB4.p2NfUsOTTqtp4rhubOJ3ql4UrG9FR2EY8TB
3HlQcRygqn596U165C+sJl2c3Pc0PRELoAEuamkMRidsSujxwNMbLeZzpDTm
9JWYRAMI6gQvlFZwzW+bZJRoSD3BOFPay56U9Up55111K1tigzi7.yCxC3Zr
bPqZ18bZx0pZP0SHvPh.cCrcH.DkSLkswdmNF5nxFqA+1EvxlQEikOcClGjY
cdPMbdPZoed14KMcpgFPiiCgfYDjiqKj5JMc..bKGLLC3xeKpJKfqCBJ9lpA
PGUcxbrUvBHGfXng0z+zNiGkKFv9TajqkVzCSZoAW9og1ze21WXG6vW01Pb5
v4JCJFUMY.pBpoi0usZdV5tvS22hN8.J3zCnXS6dIZ6e4Y6YoYqlWnq+pgyJ
V6LhoiatihHseB43Jbz8tnQmjBF8PJVzQwwpqRC1+04+.pLr8unPmEt1pIc8
.K.zCq3OOrB+bVD5dmWV1XD5J5Ki+TC6DMVINvrOw0UYpiRmQ6pQcuqD08qh
hNfJPcuq9zeUnOYT25LqPo+JJ8PplzYQp4G+3ebOEW9SurJI9d+nOJ4N9WMy
+mpk3Uk0P3VjpnJPh1Tkh0fSsT4+oa4NnvcJkoPgvl7xYENV0uDDjhyKEIHy
NOBB9Q.2yX4fQ7oCbt4MX2hANCKFP.LpJERTBVUIFPNmBxPql1THOPLUQ0gn
14KMMjqF3XHFIyFd4178XEk9d+H+m7LQHpWyG0wG4VlzczrXsxA6xJp64b6j
hSQNPaNcD0Eb7u1CRboInl6qe6iNHAMSjkbGVTZPZ+wPV3a1lkwgLCkHZ65h
SI4AjezQap+c0ZwReAMw+dufnOuGybNuWoo01Gc7l9oOK1A5ME.Zw4222sxQ
Xdi9hah+mUkU19xq2XF2ssgdsinOD7wX+Rq+.mC5.+A+U6udjtvW5fVZOINd
9.u24kkD7okYIgSDTdTlz9Y9Ie17DDON0jeIvU9WhW4mtWVIFgiOC30x4KxY
uUIBNQLz+EYQha5DVm111NtbDm9uOXY13v4ms7NuWrg2j8EomieXY7F+8y0w
cqZka42MyvtDbVPv9n2h8CjOPmSFTO5QA34Q8u3fBRqa++55Kq5nqb7iw2KB
+dVBIZ.hbwWBn3trkKHNmIIeIcOFf9ee8HVH7yffQ9Qum7uKNY8mmcp03i3P
9c+OqHgUdIO95HwGcxqko9yTjf97DZuq2CTtXzkKKsiDnzmAv8XIUlnTmCGP
tY1xl2rk1b8YySipwAWYwYky6my+bf.fJeYYywiGsuKL6hPetUJU8b7MwwOZ
Rlx2spZsNn+UNs2UfALiYx17W6Wr79MiIjL6r1AQOdXZRojqq86NW6jxafi8
.NkN6fohs6kAVrFCumlq3xHzQ2lKe2xpJea3pGMCKXy3.0SfMgSRgFYHgWWU
CX1cpMYg8bqyp3n9VT04qiogB2wFWHRMyWHv0NufBkeuK4GwbLLPQi6vHyB7
2pQ5zOrOAKib+saq8sUaMaHmFe5aiICBF1Fslsodq1k07PamzHCFSKw5.ZGV
GIWjlxZrtsj534HZ1hqFahuGnsVMKbx5aeUib0WGQKqZNAhlslpQCEmViE5a
6TiFHLtUSMi.QqVJ03gBCZiTyH.nocQMZPv3VD0LBG+M+UGDLvJCV.VFSMH2
x6wBFZ2NqFN4GCzBqNf1W07CnneMCnZ6GWimszzlmzr.Da1lrI7vc7iU9MIH
10gcTqgkPM2vkkMFXCTN+hH.pqT.E4PnniRs5l3uzO3Iyq.Bc7fk4aYGrCNZ
0ru1lk1H7VaDMHs8t4nMK.dpezpzuDsJqu6sMBR1H5XameJbp0U1FUl+01I1
lo4XZl+caCCy1+ELV7A.yjXYZYLihTswbF9CUwgPfpkoihYX02QJkqRgdbHP
Jf+z.6HGlixQSbonIF4h0roNcFlirLQe16KwuWxmEYg8k8Tv76BRxdw5Ober
IKEGz0EnhefyPamWfST..Ca+ke0o6Fl+MC2Qp1ABFTYdev47kb8h4K7Z+0tH
lNMDi7mQwCXnF9XN1uyF8ntl73.M3wlM2QUxkj+VwqHemU56Wp4PO8Gsc8Fs
Eau6N+D41XcX71UQ9oo2ll4kkdaXbz8VuUrm5lZAK1zi00kvboTgMZGUGBCg
cZ1Q4z2KG6pyD1rQNpcyWVSO2aZvG2EtMX0MbrhDI7YNBP1FNpgexwLhKna7
VlWRlnSFZArdKexJNjiGyG3tDNM1BKGQdbpEy5sKBiW9nXKKFIGf66QvS76o
XNpjP2pR0Hta5AykpZUa1pt9mr8sY61I8.2E8nnuZVRWzSSPyMMYiUheJWvL
8iweWvxrdXEsYpVmoKVxQ5N.mHrKHeUfTSjWxK5AYfdPt5DyOooFg6BB8EJG
y0HTzq7txaylJmtlJbN54mU5Bctt7TAQpSU1r83wF8TPw8yJOqWxRgwhkYaS
T5S9Dc2dW9Uqi47WQaCpzgcJ0QppsKgdnzM4F9tpRdpuZGBmHQwPEqF0V0kW
cpV3Cb+FDr09qp1G+tJdieTPzFQk2FkU1.aJGN2n1scr6zWa7BSyZGbWqlIo
xWG1U2mDrJNRLIpQIDmth0bofi326.F4UD4sQyMqrHzwfoxlbyBuDAgZQ9hM
TpdONNr9Pk2Wn+cY4CuIHJpAVLKdS2ClHb.u6gWDyGbceOa4Ho2tMRM5sbdh
raEV+pecdgg4xs0e7exKJXsWleVfhDf.kC5G4wAzG3FHiCCqAupQdRyHq373
K8eNXU1CpkhoB8dDVZ2YJsVmJpwo1tHWF91L+0aB4PQ8KPT4ioYoOD+bZCi1
UQ.c0+iLqAc1dmwYmFwDe9jhaU52fs9MPqeC2MZkt5d6lmDUG7LmsFiOzF+Z
mcxSh6otiu9ywAQFgMPNJak1z4CavN4MT430K39NXIcnfqr8I+z27FqHq2x8
c8964ldrfC0QpYLI9gHQS7HCNzV1cMuIZgwvmZLVl0BKfQLPPfRpxdpZh4AQ
c2btInScamV5+Y0u4mdYWPxxAgZRKl1tObi.mbcNSy.nH6t61zjiCJhauza4
ibCTs+OyTIovZXjIrTrg6z6WuWGzI9kdpYAyrBsVXlroKxbk6Cptp2cW.6S9
lKvuDZwc1OwhYFpgVFU3LpH219j6HPZtMNqeK+pr9FY1N9s+O5iZ++42cyFe
+G+sv+4+7Z.++sf1+temYnSUROvHmYyMBzoeKGXWr2C3hosDMv+Cxgo2uRX3
UT+2MJB1M619uis3udQ8PiJxgH2iet.2spPV54BVyCvu7RN56NKBb3MRKRq8
8hdiUZ1JdnT7+8Q+mE7+uw5wsIYw73YdiUX7yuwZcvp2X8.O3w2Xl4JkOglY
tBZH0t68HfNovrIDcVrECnCeJLCX87C9QVqhi7G.EAgUcRL2sYvPeKBptlV9
uf8hPA5wSX3QQYgI6gDJtDavzrGRzImAkL5MOBi2wH1WzSqcezdvOXyQPcPy
o83Y1ghAlk8LCpoMfaBZF6H6DS6F+H3bNKLs8zSlysODhoaeHxoKbtlEnVsu
b8yBQrdVn95y4LaoJTDUoChU9Wy4T2Hlo4byNv1z8bAI8t+FEuCU0n3k1hHz
c+0bM2McSH.NmJEroFxBBQynffbVfLcVflyYA1zYAdNmE1lNKrmyYAwzYwrJ
iPMcVPmqYAYLpoAy4rvD8EEJVlmYgsoyh4bykw3sLpho67LKLceJgNmTDHZL
tx.5X2L4WEU9iLC.OE3+7vENAAmmcPlJONvNKcBflph.d9THHX.9XTHHT1kB
A4RgfboPPtTHHWJDjKEBxkBA4RgfboPPtTHHWJDjKEBxkBA4KyBA4fqADj6k
Z.4RMfboFPtTCHWpAj4oFP5096k5.4RcfboNPtTGHWpCjK0Axk5.4RcfboNP
tTGHWpCjK0Axk5.wn5.IutINn5.gBl65.oylViQ8qFFjcCyE5xntxebD8Ssh
tWCvc95dMH2SAhoVe7AagLnS9..23.bIDahC.inTQKBCAoyHlgdBvLEHEVu3
D8bK5vPPGvLhgbNC57Qc1zi5oeGMQM0HR8dZDbd6oQHxjgs23E4G1C+kiZQo
HX5MLt9VGjhMykJ1NDPx0sBVMcgCq+EUrp47YVxJU4mgpcFi1km0WRahpEq5
6UWqyuUqB75Z+Z2anY20mLcby+RnUZX.m8k0qrM4FTSYahCoMkfP1WQ6N4wf
56kYnY.Gf6AGPYtZvA53FmCb.dtwAuVr3uWMXyRCRTd5P22BEsZoHTCBgSFD
VuNv1AhU5nb+FXsB.qO.1UBvPHdegXsfq6bSOKsRUX.plgp3nTeg0n678DE6
ZpFGgdNHZU7yhh6TrrUVu8g3Mx+fZWsa7QsAUMcsmsfODlcTZAevoyiaYCvr
1F67Uk0c6v.rV8FnbqXPmavb0LhtXssKvlBJSiyUbpFedymHpm1qYEVjFPSi
fZWT0lvQq8gtSLoyEx8vwn01Ip5A2YSTqdZ4uGq.Y2cMSxQAPqKw9j2tvXKE
ZQgAoY+D7e0sXs7J3hdR20aI9Z.VTUw+HHbR0qgcOFRXrd7+k8km7kM37P.S
g6lO4Ka3Yk70dHbMLxSIVAclVwJa7zIVMIdGQlSmivmuNGYpeQxg1e+hH0cK
ZlihGOL2k71pWLCJ7ey7LmSEZmeYP07K2QtkwUVixVTZSeSXjIuIxD7lPDCd
S10Ru+UkYZ.N+uZJS+qFbX3WrAuZzTfecM3EUvWcPunFHpNvlSwax1Djm8j7
lfl7lvSg.mIzI5rvJZDGBdND.wlH.hcmBzqQZNgSwaxjWzTvwXhFZn6rn2zz
2Lbp4UM5MCczCznC5U23odLw2l+pmbDtYu5YBiaahnDXNzIZzqFYOKD6ZkGW
WXb6IPABzHh6rn3GZHe0rPaMwldaaNJm2az0DDuiFcKgFcJg1cIgt6PBM6NB
xZ.Q8kh2HfgcMXfsqBh+f7y7+124GsUECRi8oo+SwBk0Zm1tn5QJ2gsUiV1P
FpuIWayIaxMGIHlgTa20hclbR0Jxpw1wckM747chI9QhsTabsLB0bq31zMTa
8al1cuQZ2wlncQEtbcNijtcro56VSUY7JIF+v1kd8Q.ZrAY8W23GY8AwJW+A
+0AKDaUikbk02H3YDnZ6HG4hcbUGQf.pa80PsyMFKD1EAUaXbkzCjbius9Cn
wRo5BrgL09HnKwNeSfzF4xTepHzJ22vbVM2612ucP8V616ELU61tMcZCXMYu
LbiBax3tJSvotMcLFhSHcTa1jLjRtvA.D6IwUoM51RxK2J6J24hw4aucUuSc
aHdLGNbqPb.nii5H9SAgprg3cvBDuyKKaHABMa1cctQ2cvSn2+6ytUdafQHm
pZhK5EMcy2c3DhCE6elfpas8CIZ1YAQzRVrXqzs8QUuskg9dUK4Bn5g6xEeI
JVdtjBC27c8kk7qw21DK.2d6ntOwygzxLIbz+3G+iifU9O8xpj368i9njp9u
pl6zVaIiHgYd0lfKBRnJEMBrMp1VxXc9.nv0.k4AgPf7RYENIzM2Mjh4hOx2
Eyl55leDv8LgO0LMsmbuXzyl5zOaJAvn1p8aSBVssoC4TbjAVQroPHP4SmKh
Zmu6ACcXNSIKtbkHBVNB17u2Ox+IugXv6T0acXLWattilTM7NXW0NNJ+fbaJ
hSQ1Cc0Z7hGNtWydyJ2Djx86r8Q6k.Pe74t8ylOHcbJ4U+lJqRrdN11lncJQ
wf7il7o02U1M5NilTeuWPzmMbVw4AJMqz9noepk9b.WyQeStVbZvbw7c+ZVl
SnypI0etZIlXFuUiYidchcp6TenTlpqVqsrio9geve03jC0gCztQm25hmxoM
OdtjfOsLKI7.l8S5DRT9Ket+jdMN0GmKbH+k3U9oFqUzPCs8Xw7zCviREBXl
Yr9KaWun+IiNMPsMZNCSs2GrLaXb0Imd9dQW1M6ryaiOrLdiu4tarKq0tXwO
C6F+QEI+QuElCJGfwwA0uLo.EORpEi1AZ89SnIPf4UwwGiuWDJyj4NaODELO
tcFTcG1XnLlL67kUYJAo+95AVXoinil+n2S92Emr9ySNFd7dTV1ORNXfakWx
iuNRz4resLUE8Ab5ykgcoXIqbAdJWpGG4DtclJFY5TOfzuAGfmcxy7vjm5s5
YdPiZkAWIfIgS4my+n8Af7x.eJdTnwrXHKB84ZlUqa42DG+3PYYaWVvacP2q
ZQuYbELgYCyrWyWD7jM8smLYrbAQONdMRTx009s1bkVdwbr.vozvLlB3pe5I
orFb8Mytpg53ZyItaIMjuEb0ilfDyZNHcD0kdTV3aCHh5VUsguKsIFomaaRD
SdTES1OJJsmSsyRgBWIF1E5l4FA3ZmWbIttXGV9QLGCBPfV5rAoT8YA+4zAW
q89DsbGgQOLcfKCSCRhzEut4EcpGQDKWnZZA3J87TShxCgIH251wDZ9lb5Ps
OApoiVbvdX5TtX6sOpGUiLGQUocs1iNhlzOj5TqtzgYTwpcKVSS5VkZ5ax8u
U8sl8Mga8eMbTqvgnpDY40PvNkQtStJn7IXR7yQidFdbTRplge6KdieBBPtD
0p3yXXLRI6ffbOfl9I32m36uGyPI1qLUbPpvutoex8NtlsnLuQO8brATpJIg
T.exIQkTWnKY5mi+M+Uid9wJcTDVFuCH2hwTO+9G9ggwO2+TrcAUQbA.mds4
hHphTg4.cjd+xuGhMY1..zWh.fb4K993v8fEoL6EDteMDU8.U0j1jLA2rMYS
3947.qr9GsgDt7uTIkPMP+kXFFXCTNFgH.pqTH.4PnnIsVkR7W5K1oqFqdix
XR2ASfIuVASTgnHXKL1hO0VzhGxMDvxqAbN2pKtWr8wgKJ0OZU54lEjcH49k
8ZTduLHfoVmIaJvMuT6YPxfADebP0YdaFQVB+AurXqePDE5US16OMy+tsggY
iaAVDezJLI1gV5qtHU.kknXGEjpCg.UoQmhYX02NAkKRRmVjpBnNNvDxg4nb
NAWx9iQtXWmyk36y7SOu9dAdVjMmWFAi+2Ejj8h0e393gRKNz0En7OjyTYmu
n2T..CqWc0cZFzrugkNR8FPv.IiwEmy2v0iju.FcWuHX59gXUe5bcr699U+2
u5+2aVhky
-----------end_max5_patcher-----------