Hello! I’ve just started using Flucoma in Max, so apologies if this question has a very simple answer.
I followed along with the “Building a 2D Corpus Explorer” tutorial, and am now trying to expand on it. I would like to query to KNN algorithm with an MFCC, rather than with a mouse position on the 2D map.
I understand that the kdtree needs to be queried with data in the same dimensionality as the data that created it. Because the kdtree was build using the output from umap, I’m not sure how I could convert a new MFCC to the correct dimensionality. I imagine this would require some way to save the state of the umap function so that the same reduction could be applied to new data- is this possible? Alternatively, to get around this problem it seems like I could just do away with umap and make the kdtree from the MFCCs directly, the downside being the data would be more challenging to visualize.
I have a separate question on the same tutorial/patch, so I figured I’d ask it here rather than in a new topic.
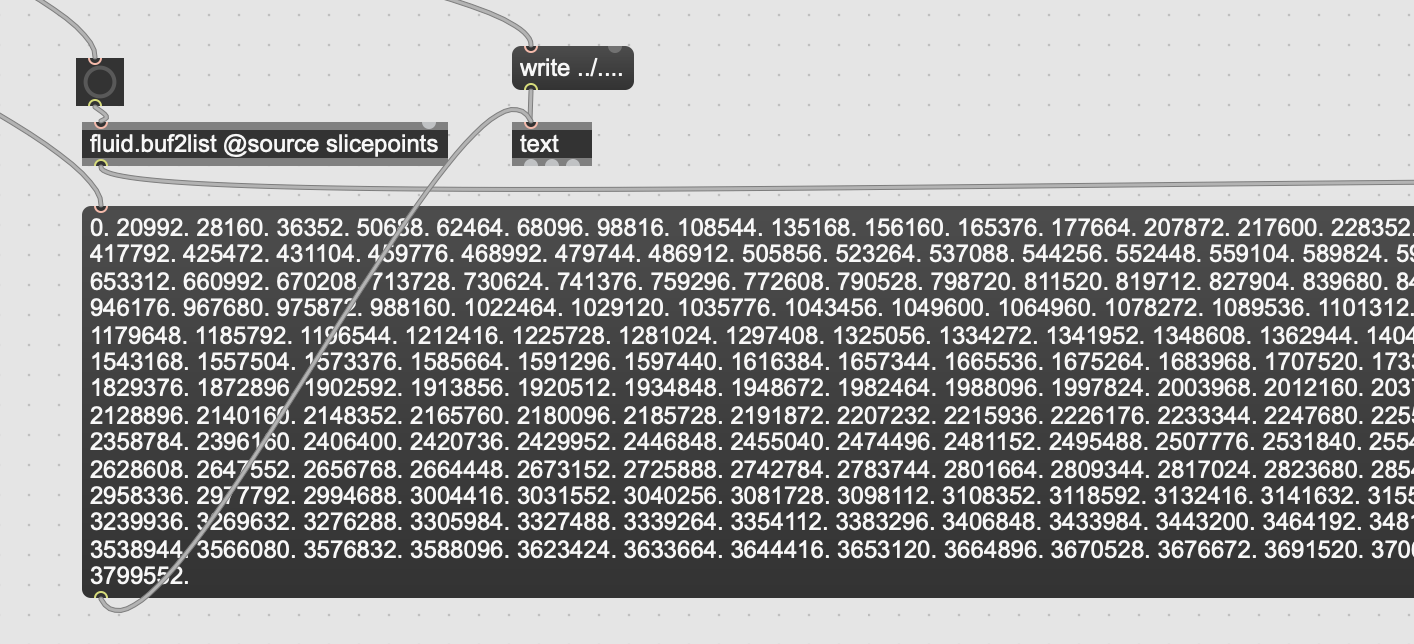
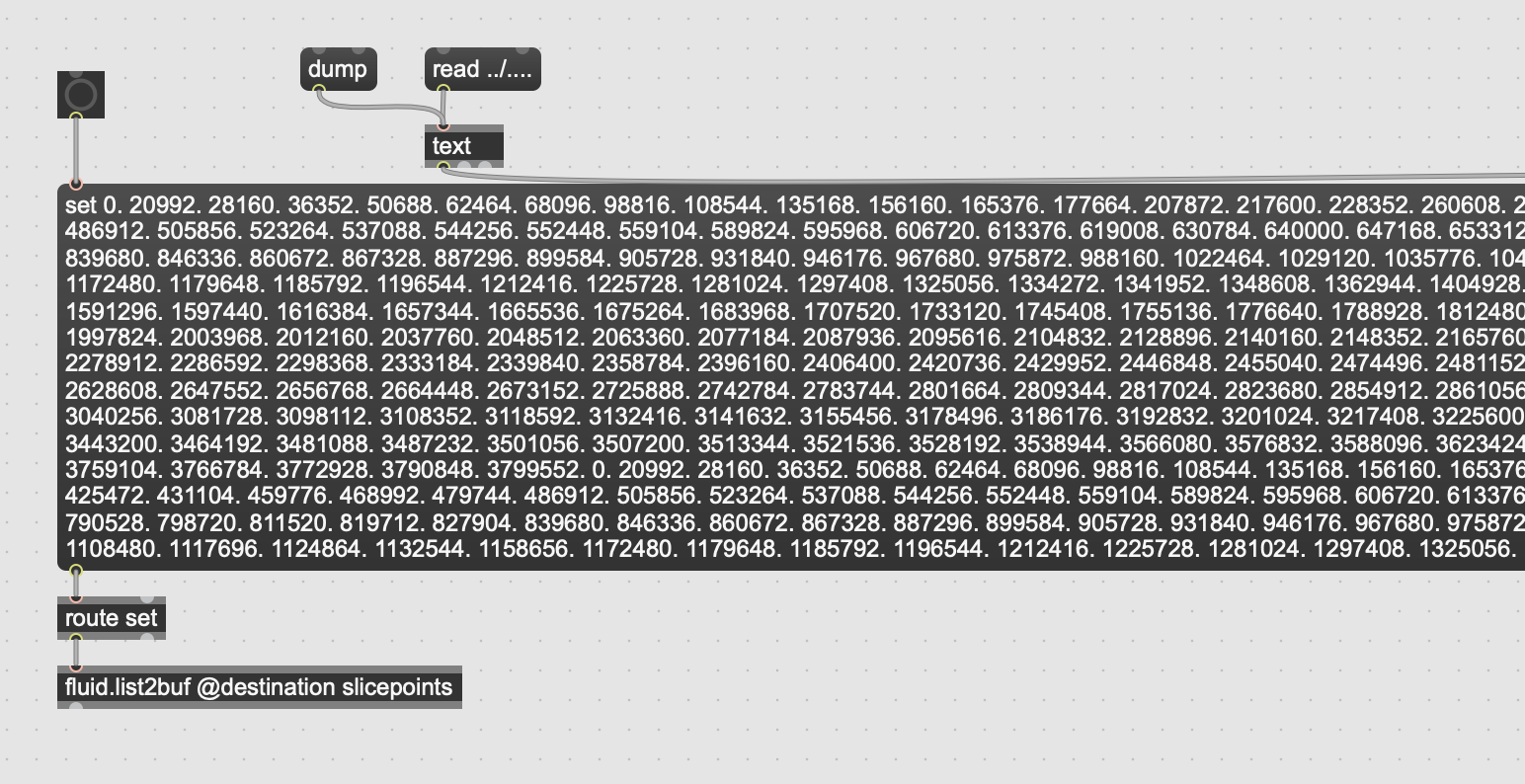
I’ve built it so that all components can be saved/loaded so I don’t need to regenerate everything each time I open the patch. This has all worked well with the exception of slicepoints. I’m generating this buffer in the same way as the tutorial, with [fluid.bufnoveltyslice~ @source sound @indices slicepoints @minslicelength 10]. I’ve tried using buff2list, saving as a text file, then loading using list2buff, but this is failing in a way I don’t quite understand. It appears that the final slicepoints has ~450 points instead of the generated slicepoints with a size of ~2000 points. The loaded text appears to accurately match the saved text, so is there some special way I should be saving this buffer?
I’ve pasted a screenshot of the saving and loading functionality below.
Is there a reason not to write the [buffer~] directly to an (not really) audio file? If you send the message (samptype float32, writewave) it should behave
fluidbuf2list behaves the same as the zl objects, in that the default list size is capped @ 256 items. To have it work with something longer give it an initial argument like [fluid.buf2list 2048 @source slicepoints]
I had tried with all the different buffer writes but they weren’t working- turns out the problem was specifying the samptype. Now it’s working- thanks so much!
Most of my first passes at Max coding tend to be excessively complicated. I won’t even tell you what I was originally thinking for the umap question…