I’m working on something where it would be useful to pull out the median entry in a fluid.dataset~ and I’m wondering if there’s a better (and/or more accurate) way to do this.
So this will be a fluid.dataset~ filled with a bunch of rows of descriptor data (so generally 100+ rows, and somewhere between 8-100d of descriptors).
What I’m thinking at the moment is to dump out the dataset and find the median of each column independently, then create a synthetic entry out of them, which I would then feed into a KDTree fit’d with the original dataset to find the nearest point to that.
I think that would “work”, but I’m not entirely sure that that would actually be the median value, and it does feel super faffy.
Is there a more elegant way to do this?
This is an example of the kind of data I’m working with:
fluidobject.json.zip (120.2 KB)
Hi Rodrigo,
In the multidimensional case, the geometric median is the point of the dataset minimizing the sum of distances to the dataset points (Geometric median - Wikipedia). I have seen people using the L2 or L1 norm to compute the distance. If the number of dataset points is not too large, this may be a reasonable approach.
Best regards
2 Likes
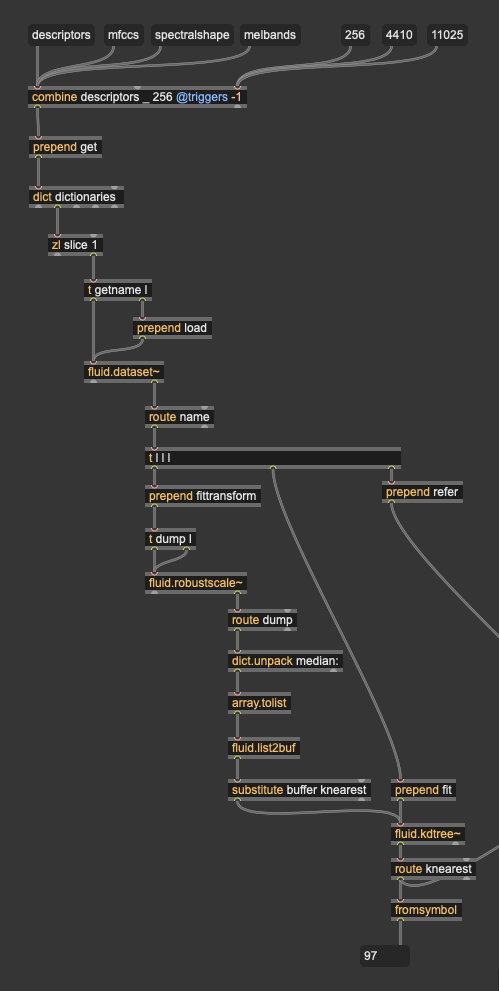
if I understand you well… you could dump the result of fitting your ds in robustscale. it is centring on the median so you know what it is that way… then you can search for its NN (I’d bruteforce it right from ds if you don’t need the tree elsewhere)
2 Likes
Easy enough!
Since I have to pull the median from the fluid.robustscale~ dump as a list, I just did the extra faff to fit the fluid.kdtree~ anyways, even though the only point here is to just get the single median entry.
1 Like
but the median of each dimension is done independantly, so you’ll still need to look for the NN. The likeliness of a single point having the median value for each dimension (col) is almost null…
As in what I’m doing above here yes? (fluid.kdtree~ is off screen, but being queried).
1 Like