I expect this is a simple question - I’m still getting a grasp on how the process works and the language around it…
When I run a sound through fluid.bufnmf~ how are the channels ordered in the resultant multichannel buffer~ I’m assuming it may be that the first channel contributes most to the sound, then the others are descending order?
And is a stereo file treated as two separate mono processes?
The order is arbitrary and if you rerun the process with the same settings you’ll notice the outputs Re similar but in a different order. If you supply a stereo buffer it will treat each channel as a mono input. Same goes for anything above two channels.
With regards to the first question about how the channels are “ordered”, it’s random. Rather, it starts from a random seed and starts reconstructing stuff, so there’s nothing to “sort” the results. Similarly, if you run an NMF on the same file over and over, the results will be in different places (and slightly different too).
What I’ve done in the past is then run some descriptor stuff on the results and order them either by loudness or centroid or whatever you think is important. @jamesbradburywhipped up a thing ages ago that then takes the weakest results and combine them.
As to the stereo/mono stuff, I think there’s a tab in the help file that explains that, though when I’ve done that I tend to just split things and manage it independently.
In the helpfile, there is an example that does exactly that indeed. There are also examples of pre-seeding significative bases, which allow you to guestimate where things will fall.
the tab entitled “fixed bases” should help. There is an explanation and example on how a 10 bases over-separation of an extract is then ordered by centroid to pick one, recompose all other bases, and re-run the whole process on the whole file to get a predictible output.
After much tinkering and cobbling together of helpfiles I think I’ve got something close to working. The aim here is to split into 10 layers with fluid.bufnmf~ analyse for loudness with fluid.bufloudness~ and fluid.bufstats~ then to be able to sort through that data with dict.
If anyone has a chance to look at this it would be super helpful:
a) If I run a stereo file through it I’m getting a 20 channel resynth buffer as expected, but then 40 channel buffers for features and stats - why is this? (I’m assuming I need to read up more on what exactly these are, but pointers appreciated)…
b) What do I need to extract from the dict to measure loudness for each channel? I’m guessing (admittedly with no real knowledge of this sort of analysis) that taking one of the mean values will get me there?
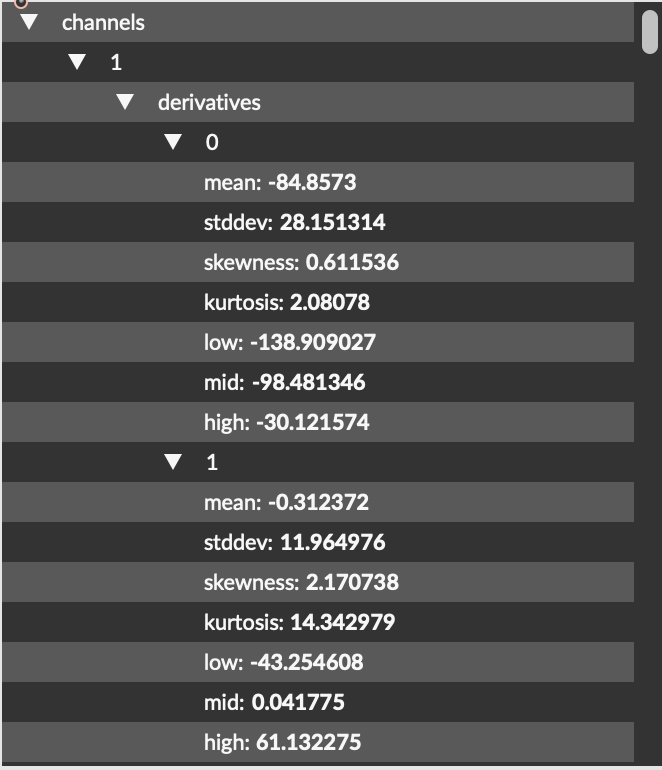
I’m not sure what the relevance of the derivatives 0 and 1 are:
which describes the change between consecutive samples.
.bufstats~ will calculate the statistics of both of these time series and give you the results in separate channels.
The idea is that you can capture the variation within a time series by analysing the derivative time series too. There are pitfalls to that assumption, for example, imagine we have our original time series and a new one, 4 3 2 1 0 to compare. They have the exact same first derivative time series and we cannot differentiate them unless we start looking at some other metric or form of analysis. Further to that, adding more derivatives doesn’t help, as the next derivative is 0 0 0.
A new channel for each derivative of analysis is produced in the output
I think your patching overall is pretty solid - can’t see anything that would hinder you from getting toward your goal of analysing the components of .bufnmf~ by loudness. Its likely you don’t need to enter a dictionary at all though and you could use several zl objects to sort a list of indexes that describe the order of components.