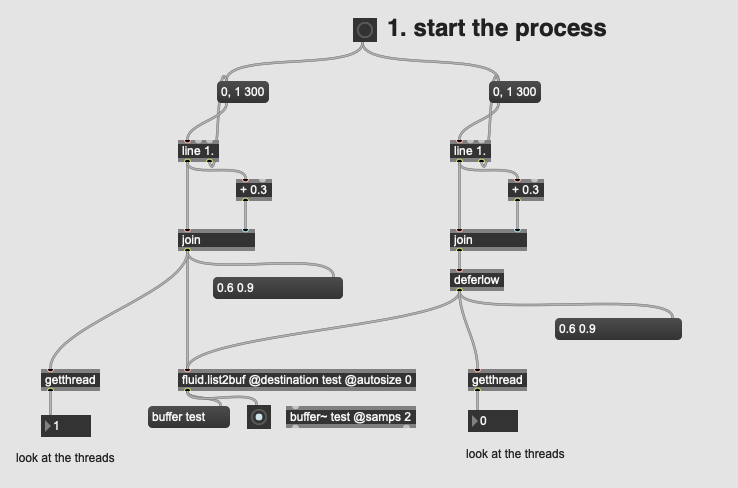
So doing some regression stuff and I keep getting this rare/intermittent errors from fluid.list2buf which outputs terse and often malformed error messages:
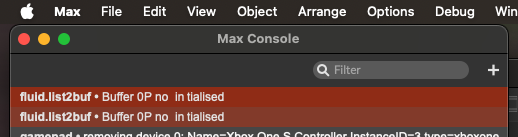
(it’s worth mentioning that the buffer being used for this error message is 4458tempinputbuffer and not whatever Buffer,7 is)
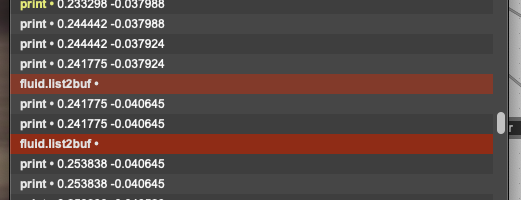
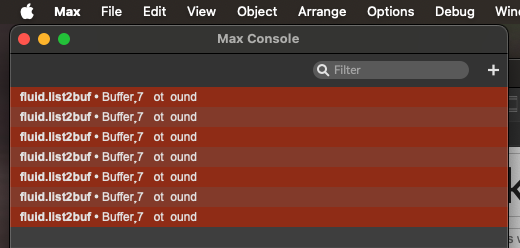
The third one shows the messages going to fluid.list2buf when the errors happened. As far as I can tell there’s not really any pattern or reason (and the empty error there doesn’t really help).
/////////////////////////////////////////
Actually poking a bit and it seems like having multiple threads coming into fluid.list2buf freaks it out. For context I have it set to @autosize 0.
I (occasionally) have a line 1. upstream so when paired with controller input means that different threads are knocking on fluid.list2buf’s door.
Here’s the output of getthread when errors come up:
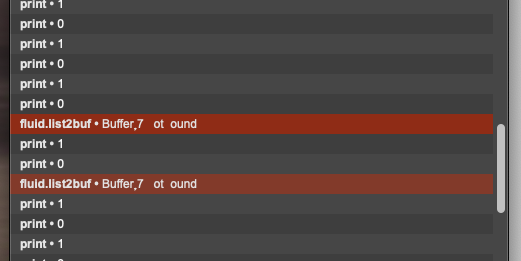
Interestingly/annoyingly, it doesn’t happen all the time.
/////////////////////////////////////////
I managed to make a patch that produces the error intermittently:
<pre><code>
----------begin_max5_patcher----------
961.3oc0Y1saZCCEG+Z3ovJ2NFJ1Netq5k6cXZpx.FZ5RrQINsrU08rOmiCs
TfP8Rb5XUpjFWS96emu7wvSSm3sPtiW4g9B5anISdZ5jIvPMCLo89IdErcKy
YUvz7VJKJ3Bk2Ly+Sw2ofwykxefXJj5Nt92RNaU094rkoVdWlXysk7kJiVTx
b+YnfH+lKX+3lKD8Mnu29dD0EYhbtBDE+5fxZ09Q8aGMaEr.jKt+y3Xulwdd
5zlWl8ghTPhgovHGyTnKYBOGUoXkFn1VJWxqdAp0RgRvJ3vD+JO+AtJaI6RH
6SAHMnRRatPOj3lm3Z1R9Q.2Gqf+gqxpreAOSRvb+dXbVTqTRw9GnQX0O2xM
T4sfI138BCmK5MltG0YvZv75eiiFeJhguZoK0dAEu7VtfsHGVV8ASA+Q8y8j
PfU707xb4icx+EYOH1PcBt4RnAdxfgmF0mn7BczKaC+DDaR.0tG+9gXnODIm
BN4PxkIjXMgDO24C+DxeNsS5VmKYpKiHIApRkBdQZjqXj5PFyyDbDdd29vYV
jp1FthMtw.7kAkdVPImAz.GB58xLwvRFMbEG6J2XnSSFmioM+nCYCf+nmYkw
gPrpopKl3LXwtEVhlyv9gHgZ1OMAp+fa2ewAH5e8TbkPiGghqjjqnhqj1V.c
bwURv0VwUbZxXTbkzqcQFZScjnXCEwNsqNbjqaqqq7xE0q0M1gT7JU+RMwQI
FK.bIwU4l3qi8JaCVc8dk390VWcwBd4.asIw3tHfiJzuOchelrujOnigrQSL
bn5NsBYBkMF.Z6QQRczQQR+W4PivF+YrS8mQ+23OM76Z2oKq9XJw9anFK5lJ
Vw1JD4c5TvFOO0O5fJuuaieV66c4QNWmWmsZddVkhnMCnaVosAYBlJSJZsGr
Zkr4SlA0cqgFCnM0oaCCHzDGEG7l17gmEzDzQe3mvBpY72Zfpj0kK2CQ6GVC
50UzA1hCli9D+GNIY4pFz6JoykJqaG9rJiGjxoVnbqvCRm.KzIxA5PirPnzw
vRZkx5Cl1bRKGG9Xkz3yCMYXJaUNiSbr1DAczxwUdVqjlNFEF.owVVSZXJQs
09hGpRDaTJvALcTIyNpqRcgR1DhfINv5AKWrk6ULbkdWqWvXD1akzXxXjris
I5LXLpkZkxT+wXCDqjFOJlaaDNZLhwrR4fyaswmz1Ia61G3kUsucPTcG32Kg
omLCtMSXtMBtsj+P194Cs46wJ08MqzMMWWZ99Z2EE3YdqRsvh5rVs03pkD5t
u461sZa6WGKbHfoOO8O.DlLS+C
-----------end_max5_patcher-----------
</code></pre>
This produced this in my console after running for like 30s:
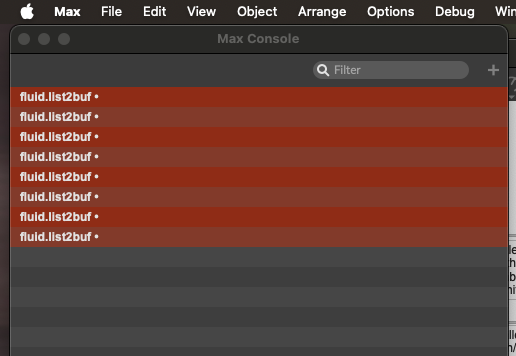
(p.s. it’s impossible to copy/paste the error as it’s empty empty)
/////////////////////////////////////////
Is there some internal thread stuff that is not safe (sometimes)?
Off the top of my head, messages coming from the high priority thread that involve buffer access probably have to be defered internally, which certainly doesn’t mean that hitting an instance from different threads won’t produce funniness. Garbage error messages are worrying because it suggests that stuff is getting overwritten that really shouldn’t be. The blank error message will be something different I think, but should be zapped.
Can you put the last bit of this (the patch to reproduce, however intermittently and a description of the error message garbage) in the flucoma-max issue tracker?
1 Like
I don’t really remember having this (kind of) error elsewhere with threading stuff, which is why it stood out so much here.
I’ll post it to the git issue thing tomorrow.
I have to say that this patch’s threading management gave me spasms… but hey, we can expect less-than-super-flucoma-coders to create such conflicting threading conditions I reckon 
1 Like
Hehe, to be fair, the real patch doesn’t do this, but it was a compact way to get it to freak out consistently enough.
Ok, I’ve found the cause of the malformed error messages. Those familiar with the Max API can gather round and have a good chortle that I was sending a t_symbol rather than a string as a parameter into object_error. I realise that this has only niche entertainment value.
So, now at least I get to see what the actual reported error is on @rodrigo.constanzo 's patch, which is the rather unhelpful Buffer test not found. What I presume is happening is that, when being hit from two threads, periodically the object can’t get the pointer to the buffer because Max has locked it whilst servicing the request from the other thread. I don’t know if we can detect this condition separately from just being unable to get the object and thus concluding that it doesn’t exist.
Anyway, I’ll put a PR in for the message fix and we can worry about the quality of the message separately.
3 Likes
Can confirm that the garbled messages are fixed in 1.0.7 but it still has a hard time finding over-thread’d buffer~s.
Yes. Until someone can point me to a better diagnostic, I don’t know a way to distinguish between ‘this buffer doesn’t exist’ and ‘Max has locked this buffer’. Presumably what’s happening is that a call is getting deferred because it implies a buffer resize, and you’re talking to the object from the high priority thread.
So, to solve your actual underlying problem (besides the imprecise message) we could try and figure out a way of being able to avoid ever having to re-allocate, like presetting an allocated buffer size. This would shovel some housekeeping responsibility back on to the user, but would at least be more predictable for use cases like yours.
In this case I’m already doing an @autosize 0 thing, so having to do an @autosizebutthistimeimeanit 0 @buffersize 2 wouldn’t be that much more an issue (if I’m understanding you correctly).
The alternative in this use case would be to manually defer things above, which I’d like to avoid as it would (potentially) introduce jitter elsewhere.
Yeah. I should look over the code again, but the ideal is to try and make sure (if possible) that we can avoid any defferals for your use case. It might be impossible (I don’t remember), insofar as Max itself will always defer certain buffer operations.