So I’ve had a couple of tricky issues with normalization recently and want to float it out there that perhaps having more control in the normalizers would be useful.
The first issue is when working with different kinds of data encoding, specifically use “one-hot” mixed with other data. When going to normalize or prepare a dataset for the input of an MLP I want to normaalize (or standardize) just some columns while leaving the one-hot encoded data along (otherwise it wrecks the idea of having one-hot encoding in the first place).
Granted, I can separate, process, and then concatenate the datasets, but that becomes really complex if you have arbitrary dimensions and/or have data that isn’t at either extreme of the data and/or want to just normalize columns in the middle. The shuffling required to do this with fluid.datasetquery~ becomes overwhelmingly complex.
It feels like it should be possible/desirable to have some kind of mask that is applied to say what columns are transform via the normalizers (can even be the addcolumn or addrange messages from fluid.datasetquery~ with the default being -1 so it operates on everything unless you specify differently.
The second, and somewhat related thing, is that it would be useful to normalize across a whole dataset, and not just columns. I feel like this would be more useful for things like MFCCs where the relationship between dimensions matters, but I’ve run into a couple of issues lately where I would like to retain the relationship between the columns. I’ll detail two of these now.
- Normalizing data that represents a physical space (e.g. positions on the strike of a drum). I have data that is between -160 and 160 and it could be that each column may have different min/maxes, but I think it’s important to retain a relationship between the data so that is “learned” by the network more effectively.
- Normalizing data where the signs are important (e.g. having data where A > B get turned into A < B by the normalization). This has just happened to me where I am working with data where the first two dimensions represent the time arrival hits on a drum, and they are always sorted from lowest to highest. By doing so this means their min/max values are different and because of how the data can be laid out can mean that values in the raw data set which are
58, 63get turned into0.753, 0.612.
The second one is especially problematic because I’m experimenting with one-hot encoding to represent position/quadrant information, and having the signs get flipped like this is making the network learn incorrect relationships.
To illustrate the point, here is an MLP trained on raw inter-onset timing differences:
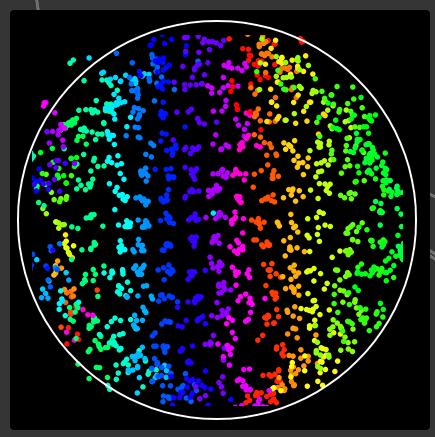
And here’s an MLP trained on trained on a(n experimental) one-hot encoded dataset (with the sign flipping problem outlined above):
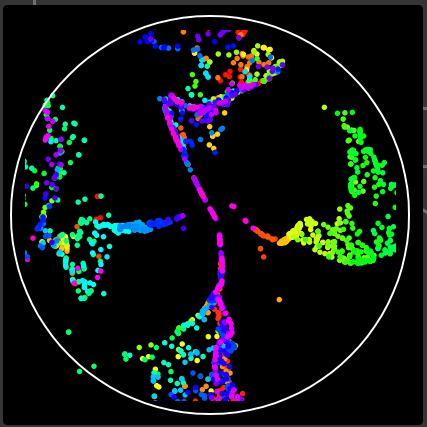
Granted, there’s probably more to optimize here, but I feel like I have to jump through a lot of hoops to work with one-hot data, which feels like fairly standard for the field.