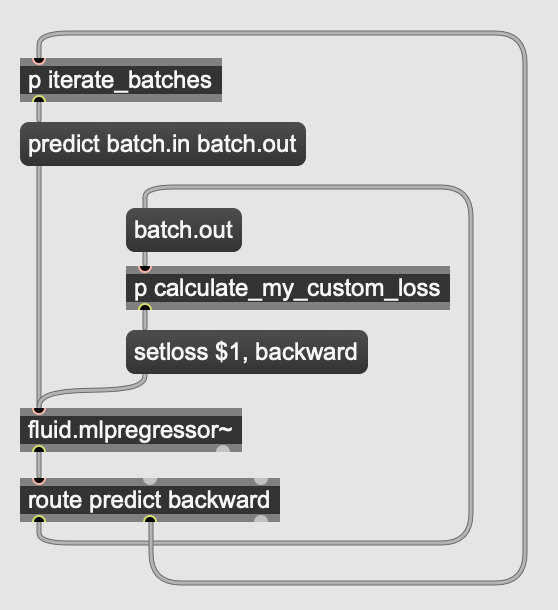
Hey there, I am thinking, if the user would have the possibility to provide custom loss values to fluid.mlpregressor~ then it would be possible to define more interesting architectures. It is already possible to define AEs, but if a custom loss value could be fed to the object and then a backward pass called right after, then VAEs and WAEs would also be possible (and probably many other exciting things). I have no idea of how much work would it mean to add this but here is what I have in mind:
Here
batch.in and
batch.out are buffers.
This could be further abstracted to the users needs, as it captures a very general mechanic. But this would give the opportunity to come up with any loss function, create networks from multiple modules (potentially with separate optimizers), etc.
In my naïve understanding, this would require the implementation of:
- the
setloss method that would be a setter to the internal loss value
- and the
backward method (or updateweights, or optimizerstep or similar) that would call the backward pass and update the weights based on the internal loss value (probably there is already a method like that?).
I realize that going crazy with NNs inside Max is not the greatest idea on a large scale (and with this I guess it would still be limited), but who knows, maybe small scale nets with small datasets would continue to be amazingly inspiring?
I wish I was a C++ master to be able to make a PR for this on my own, but since I’m not, I’m putting the idea here if anyone’s inspired to implement this… Or just let me know what you think.
I am not certain I understand here - @lewardo and @weefuzzy might have interesting insight… I’m not certain adding to this object’s interface is the best way forward, especially that I think you can at the moment do something similar within max - i.e. updating the learning rate according to the error for instance and other shenanigans… and there is also the upcoming lstm for more complex feedforward and feedback network possibilities, I presume you have tried those PRs in progress, @balintlaczko ? If not I’ll showcase some next week in Oslo
1 Like
Yes, but you cannot change the loss metric from what I assume is MSE for fluid.mlpregressor~ and BCE for fluid.mlpclassifier~?
For example, if I’d like to define a VAE, I would use the MSE for the reconstruction error (like in the case of an AE) but I’d need to add an additional loss term (that regularizes the latent space), and there is no way to hack that with MSE. If you give the user the opportunity to have custom loss functions outside the object, then you create more possibilities for creative use (while MSE will still be perfect for the vast majority of cases).
(Okay, technically another problem with defining a VAE would be that the Encoder should end up in two FC branches and then reparametrize from there before decoding which I have no idea how to implement here without breaking gradient flow. But, you could go for the simpler - and often better performing - WAE that encodes deterministically to z just like a simple AE, and you just need to formulate the MMD loss on z - that would be possible in the above subpatch.)
Not yet, but will soon! I’m super curious. I think I tried/seen the early version of a sequential dataset object some months ago.
Yes, do that please :)))
Yes, you might be right there, maybe would be better to have another “dedicated” object?
Another example is the parameter estimation problem where custom losses would be useful. You could implement a Multiscale Spectral Loss and a parameter loss term and use them together for an AE (or something else).
Yeah, one could do some cool stuff with pluggable loss functions, including much more experimental things (bwaahaha, evil cackling etc).
It’s a familiar kind of interface problem for flucoma, but also for things like bach (e.g custom sorting functions with what they call ‘lambdas’) and I don’t think we’ve yet cracked a nice way for any environment.
What you suggest is probably about as good as could be done with max objects, but I agree that it shouldn’t be added to the existing mlp objects, which are already chunky monkeys. Also, I don’t think we can do anything like this in SC, but maybe that’s just me being pessimistic.
Pretty quickly, one drifts towards the idea of having just having a scripting language to specify all this pluggable stuff, and the recurring idea that just wrapping libtorch might be the easiest way to get something truly flexible…
2 Likes
That would be so huge that it almost feels like it should be it’s own package. Imagine multithreading and CUDA support. (eyes watering)
Actually, if there was something like a more generalized wrapper in the line of RAVE’s nn~ it would already be great. Like an object fluid.model~ that can take a model .pt file, works with fluid.dataset~s and makes a forward on a bang or something… Scratch the whole scripting language and CUDA support, just an object that loads a model and can interface with dastasets. Would be gold.
2 Likes