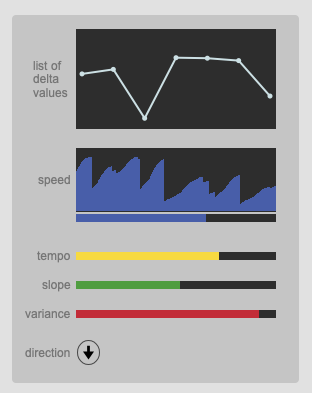
This has been on my radar of things to test for some time, but finally getting around to it.
Basically taking the core idea(s) from this older thread on regressing controller data but applying it to delta values of onset timing.
One of the main issues with the chunking approach in that thread is that it didn’t seem to be possible to find a balance between having a reasonable gesture window for capturing meaningful data from controller input, and the required chunking/memory to capture that.
So either you needed gigaaaantic chunks, or a super slow sample rate, neither of which is viable for realtime/fast controller regression.
Fast forward a couple years (!) and after having an unrelated chat with @weefuzzy about SP-Tools things, he was talking about time series and deltas and that got me thinking about this again.
So I’ve dusted off @balintlaczko’s patch from that thread and tried to create a version that you can train on chunks of rhythmic data instead (via onset timing deltas).
This sidesteps one of the main issues in that the “sample rate” is irrelevant as it is an onset-per-entry, so the chunk size is directly mapped on to how many notes you want the “rhythmic memory” to be. (as far as I can understand it)
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
This first pass was just to get something (somewhat) working, and then to try and imrpove on it.
So here’s the patch as it stands:

Archive.zip (12.0 KB)
The first glaring problem is that, it’s not very good. It does produce some delta values, but it’s nothing like the source material here (which I purposefully kept very rigid/square). This could be down to the (small relative) size of the network, the small amoun tof training hits (~80), the (potentially too small?) size of the chunks (16), or something as simple as me doing it wrong.
There’s also a funky thing going on where I have to reinstantiate @balintlaczko’s abstraction before running it or Max crashes. I plan on troubleshooting that separately, but just skipping past that to get things going.
So firstly, is this, theoretically, the right process here (for this particular approach (time series chunking into an MLP))? Or have I messed something up along the way?
I was(/am) still confused at step 5, but I guess the idea is you feed the results of the prediction back into itself with the idea being that the chunking will predict a new value for the last step of the chunk which represents the latest entry.
As mentioned above, this doesn’t sound/work too well here as I seem to be getting really erratic and somewhat random sounding rhythms, but that can have a number of explanations (listed above).
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Now presume the above works and produces usable rhythms, the next steps would be to create some kind of larger structure to things. From an email chat with @balintlaczko he suggested having multiple networks where one encodes low-level patterns into “syllables”, “words”, “phrases”, which can then be zoomed out and extrapolated on. The technical specifics of doing something like that evade me, but I can think or imagine of things like encoding x amount of deltas (as above) which represents a kind of low-level rhythmic grammar, then separately account for things like amount of onsets at various time frames (3s, 5s, 10s, 20s, 30s, etc…) and encode that separate such that when generating material one network informs the other on how often generate material etc…
I’m aware that the NNs available in FluCoMa aren’t really designed (or able?) to do this sort of thing as none have feedback or memory, but at the same time I’m not trying to make generative or “AI” music in any way. This is hopefully adding another dimension to some of the things that can be done with SP-Tools where you can generate some kind of rhythmic/self-similar material based on previous training.
If it works, it would also be fantastic to include multidimensional input where rather than just feeding in delta values, I feed in descriptors at each given point, with the hope that with sufficient training it could predict the time series, and corresponding descriptors, for new hits.
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////
So, any thoughts/suggestions/comments welcome, both in terms of fixing whatever is wrong with this patch, and how to improve it (drastically larger training set and/or network structure, ways to encode multiple levels of memory/structure, etc…)