Hi there,
I’ve been lurking around on the forum for the past months and you’ve all been a great source of information while getting more comfortable with FluCoMa. Since a few weeks ago I have been thinking about and experimenting with sound into sound concepts. Mainly inspired by @rodrigo.constanzo’s Sound-Into-Sound work , I thought it would be interesting to build a framework which provides some sort of ‘harmonic decoration’ on top of incoming live audio. So roughly taken: (live audio) → (live pitch analysis) → (trigger match in corpus) → (live audio + corpus match) via dry/wet or some cross-synthesis alternatives.
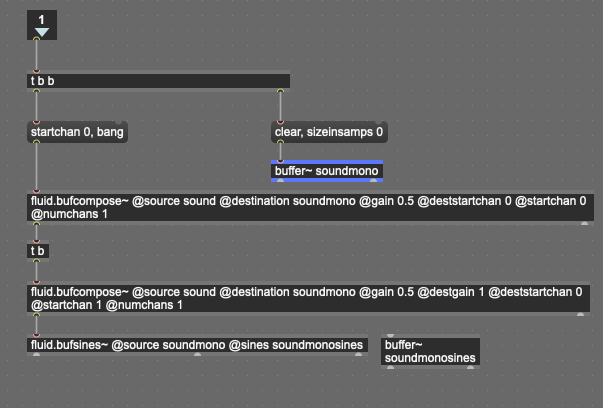
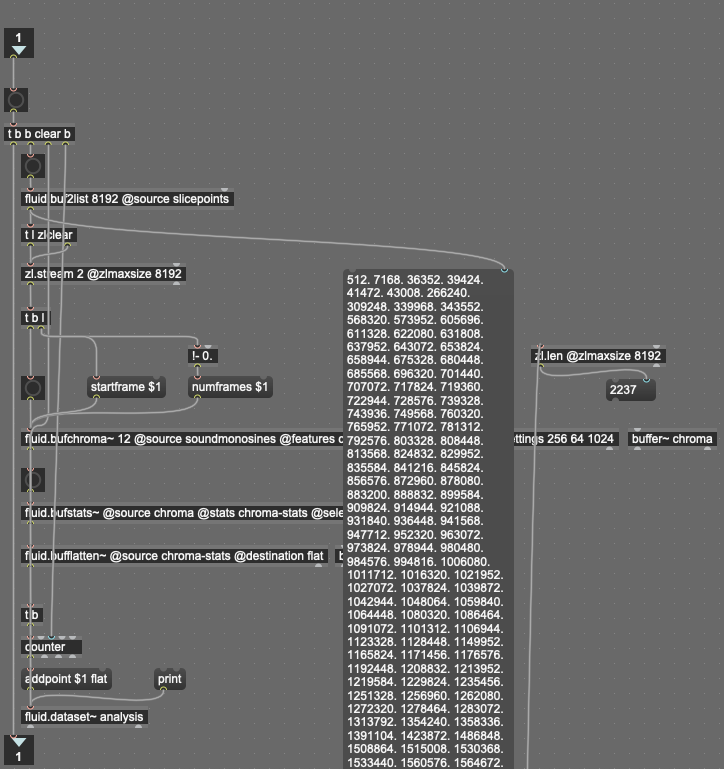
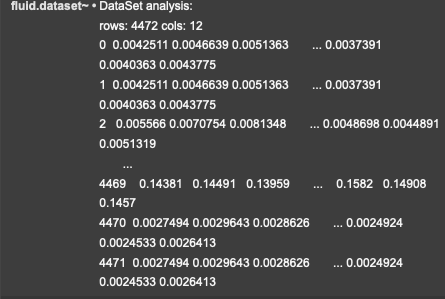
My initial idea is to create a sample folder containing exclusively samples with strong tonal characteristics. However in contrast to the Sound-Into-Sound work, since the idea is to build this framework for more general use, these characteristics are probably the only spec I base my sample-folder on.
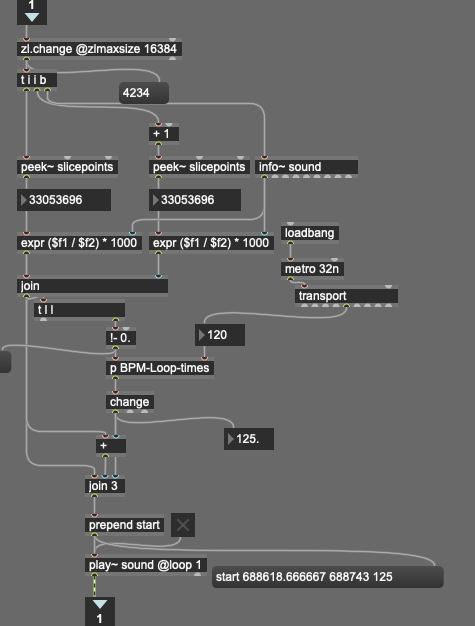
With this context in mind we arrive to the main question; How would I match my incoming audio to its harmonic matches in the corpus? With this I mean that, let’s say I have a synth-pad coming in at 150Hz. How can I match different entries than the closest? So if the nearest neighbour is 150Hz. That’s fine, but if my nearest neighbour is 139 Hz, I’d rather match with entries of 75Hz, 200Hz or 300Hz if there are any.
Ofcourse, when diving into this matter, more questions arise, like what should be the max deviation before looking for harmonic matches instead of the same frequency matches. And, would you design this query-flow in series or in parallel?
I’m curious if anyone already has experience with similar approaches, i’d like to discuss ideas.
Cheers,
Lars