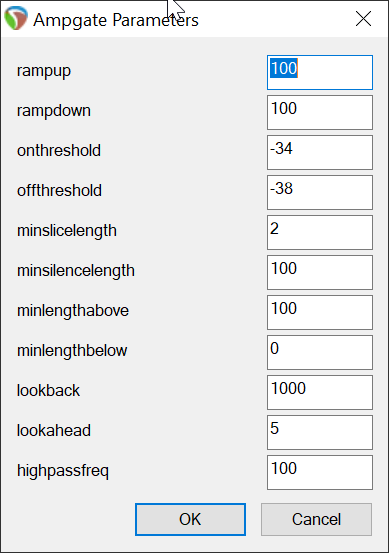
Ok, so I’ve been plugging away at this this week and have the offline analysis sorted, and today I finished the real-time version.
Other than the faff of creating all the buffers and double-checking all my @source and @features destinations, the offline part was fine enough.
The real-time version was trickier. In order to make things fast, and (hopefully) meaningful, I increase the amount of descriptors/stats I’m using with each step.
So at the moment the idea is that playback will begin after 512 samples have passed (from the onset).
The first analysis window is 0-64 and analyzes for the mean of loudness, mean of centroid, and max (90%) of rolloff.
Concurrently, another analysis window of 0-256 happens and analyzes for mean of loudness, mean of first deriv, median of pitch, mean and 1st deriv of centroid, flatness, and rolloff.
I then wait 256 more samples and analyze samples 0-768 and analyze all of the above, including standard deviation of all but pitch.
I wrestled with this a bunch since I wanted to keep each step fast (in terms of analysis time). At the moment, on my laptop which is a fair bit faster than my desktop) the 0-64 window takes around 0.14ms (average), 0-256 takes a jump up to 0.67ms, and 0.768 takes a big jump up to 1.5ms. On my studio computer the short window is about the same, but the other to push up where the 0-768 takes around 3ms average.
I was massaging thing to see if I could bring it down even more, but I want to just get something working and then improve from there. Plus, with new tools coming out, I may end up with a different approach anyways.
////////////////////////////////////////////////////////////////////////////////////////////////////
Now comes the equally confusing step of querying bits to play back, and then stitching them together. Thanks to some help from @jamesbradbury I have an idea of how to handle the (tight) playback in fl.land~, but before it gets to that I’m going to try to see about getting “better” matching by querying multiple time frames to get a single result. At the moment that would give me an overall latency of 768, but it’d be interesting to see how/if that works. (I’ve not built this yet)
Where it gets a bit puzzly is how to best query this stuff and how to send it to play back.
So 0-64 (lets call this A for now), I can query for, and start playing back as soon as 512 samples have passed. I can also query, via a second parallel entrymatcher, the nearest match for 0-256 (B).
Even if processing and querying were instant, I’d need some kind of overlap between the two, so A will actually playback something like 128 samples, with B start off with a fade in and playing a bit long as well.
For 0-768 I would do the same, with a 3rd entrymatcher (to avoid potential crosstalk), just a bit later.
Because the analysis and querying happen in the land of (Max) slop, there’s some wiggle room everywhere, with overlaps needed for blending purposes anyways.
My initial sketch of the fl.land~-based playback presumed that I would know the results of the first couple fragments when triggering the chained process. I’m thinking now that that shouldn’t be the case, but that I should instead trigger each segment of time (A, B, C) completely independently, since waiting for each subsequent step would add an increasing (and unknown) amount of latency.
Whether that means just staying in Max-slop land and eating that extra bit of slop, or waiting an addition ca. 0.67-1ms latency between segments A and B being analyzed so they could be triggered at the same time (i.e. happen exactly 64 samples apart) is something I can test.
////////////////////////////////////////////////////////////////////////////////////////////////////////////
Once I work out this stuff, I’ll experiment with mapping the smaller analysis windows on larger blocks of audio. (e.g. analyzing realtime input of 0-64 and then using that to query for 0-512 in terms of playback, etc…).