Ok, so finally got to building some of this since I’ve had a bunch of time on my hands recently.
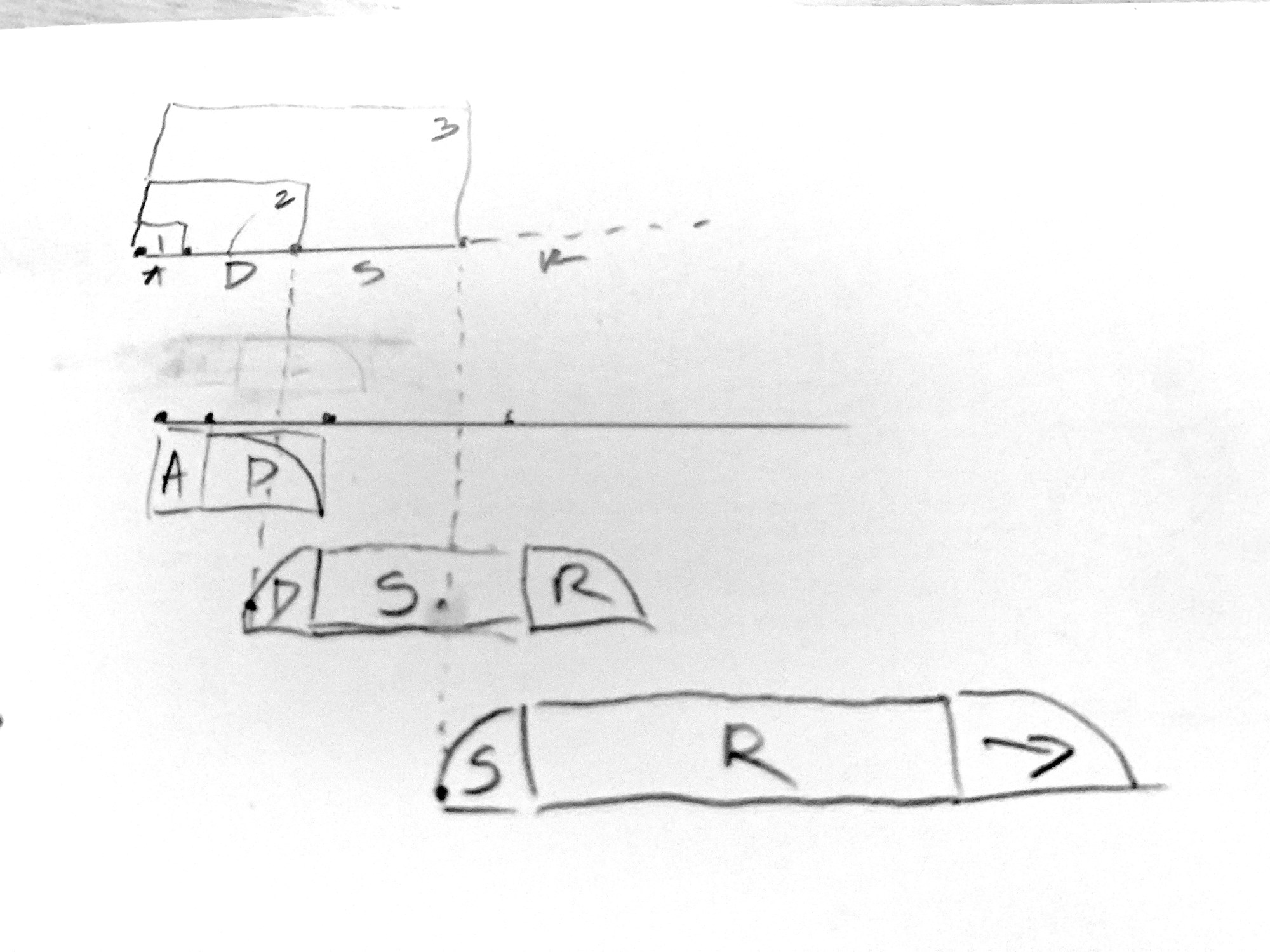
The idea is to build on the onset descriptors idea which I’ve posted elsewhere on the forum to analyze an incoming bit of audio (generally a percussion/drum attack) and then create a hybrid/layered resynthesis of it where the transient is quickly analyzed and replaced with an extracted corpus transient, while then analyzing a mid-term window of time, crossfading to an appropriate sound/layer, and finally a long-term fadeout, which again, would hopefully be hybrid.
So the generally idea is something like @a.harker’s multiconvolve~ where multiple windows of time are analyzed and stitched together as quickly as possible.
At the last plenary, after the concert, I started building something that extracted all the transients from a corpus in an effort to start with simple “transient replacement”. After some messing around and playing with settings, along with @a.harker’s suggestions, I got something that works and sounds ok, and have built a patch that does this ((not super tidy) code attached below).
code.zip (98.5 KB)
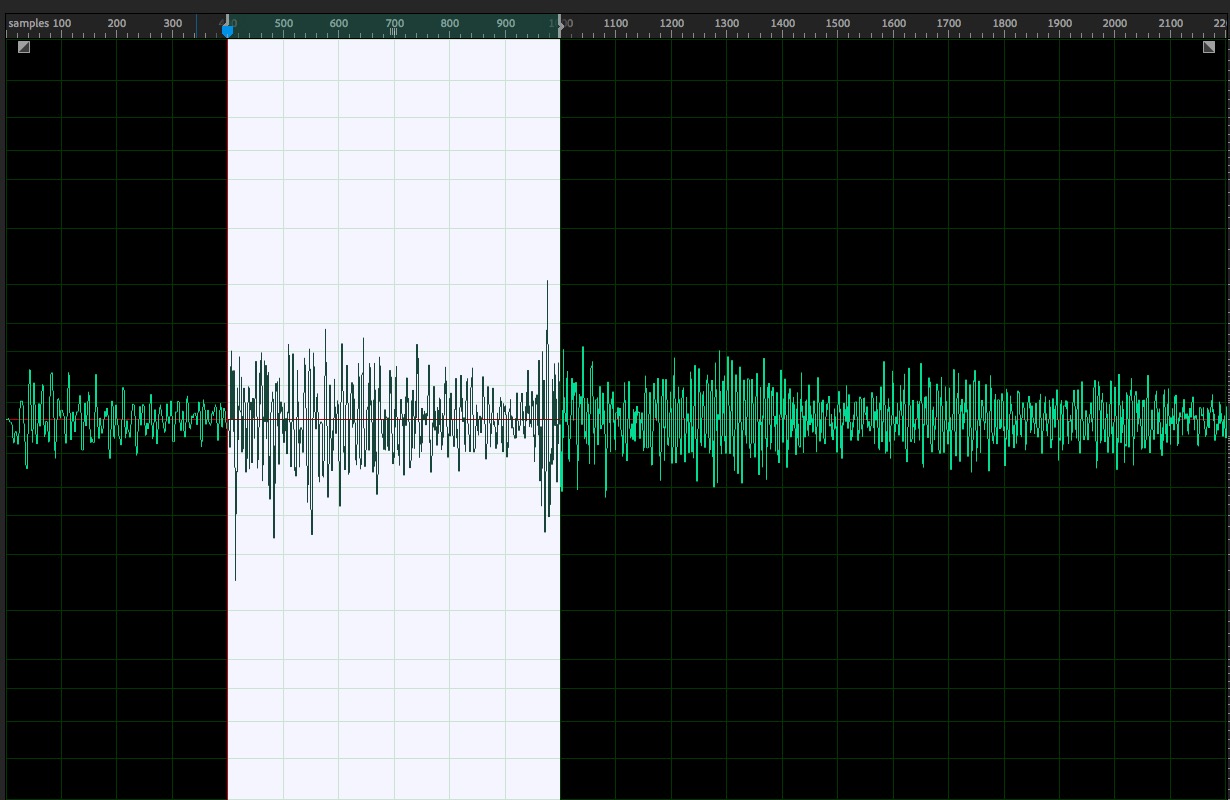
The first bit of funky business is that transient extraction (via fluid.buftransients~ at least) is not a time-based process, so even though I am slicking off the first 50ms chunk of audio before running the transient extraction on it, I’m getting back “a little window of clicks”, which represents the extracted transient. It can also end up zero-padded too, which I’ve then uzi-stripped out.
So I’ve done that, and then analyzed those little fragments for a load of stuff, which the intention of focussing on loudness, centroid, and flatness (my go-to descriptors for percussion stuff). Then I’ve run the whole thing through the corpus querying onset descriptor process which I showed in my last plenary talk.
(shit video with my laptop mic (cuz JACK is too confusing(!)))
////////////////////////////////////////////////////////////////////////////////////////////////////////////////
It sounds… ok. But it is a proof of concept so far.
I think the transients might be too “long” for now, especially if they are meant to be transients transients. This is going with @a.harker’s suggested settings of @blocksize 2048 @order 100 @clumplength 100. There’s also a bit of latency too, as I’m using a 512 sample analysis window (ca. 11ms), whereas I think in context, this would be much smaller to properly stagger and stitch the analysis.
So the first part of this is just sharing that proof of concept, while opening that up to suggestions for improvements and whatnot.
The next bit, however, is to ask what the next two “stages” should be. In my head, it makes sense for the first bit to be a super fast and as short of latency as possible “click”, and the final stage should be some kind of hybrid fluid.bufhpss~ cocktail tail where the desired sustain is put together from however many layers of pre-HPSS’d sustains as it takes.
Where I’m struggling to think is what the “middle” stage should be. And what scale of time I should be looking at, particularly if the first stage is of an unfixed and/or unknown duration. Should I just have a slightly larger analysis window and do another HPSS’d frankenstein, or should it be a vanilla AudioGuide-style stacking of samples so it’s more “realistic”?
Is there a technical term for this “middle bit”? (i.e. not the transient, and not the sustain)
////////////////////////////////////////////////////////////////////////////////////////////////////////////////
And finally, a technical question.
What would be a good way of analyzing and querying for something that will be potentially assembled from various layers an parts. As in, I want to have a database of analyzed fragments, probably as grains and slices, and each one broken up via HPSS and perhaps NMF, and then I want to be able to recreate a sample with as many layers of the available files as required (again, ala AudioGuide)? (p.s. I want it to happen in real-time…of course)
Will this be a matter of having some kind of ML-y querying, and/or is this possible with the current/available tools?