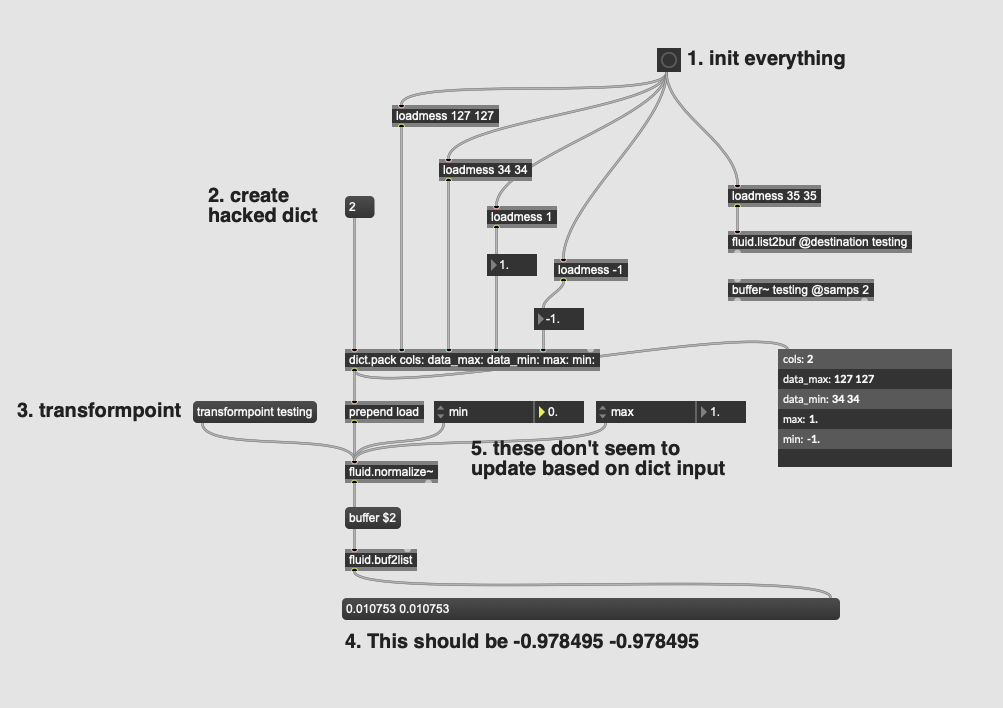
I would think that the dict values for min and max to be used when normalizing, but it appears they are ignored completely.
In this specific case it doesn’t matter too much as I can just set the attribute versions in fluid.normalize~ to @min -1 and @max 1, but it does not bode well when normalizing to a different output range than the default 0. and 1..
I may also have cases where I’m wanting to adjust the output range dynamically based on what @activation I am using in fluid.mlpregressor~.
Hmm, weirder still, the dump output of fluid.normalize~ reports the correct values based on the input even though the attruis (and resultant processing) do not:
It seems like load isn’t internally declaring the state to have been fit or something like that. In fluid.standardize~load-ing in a dict means that any processing happens just fine (on a dataset at least, I’ve not tried it on a buffer~ via transformpoint).
I did narrow down some steps where it behaves as it seems like it should:
Steps for weirdness:
follow instructions as they are on in the patch
manually change the min value via the attrui
dump output doesn’t reflect any change
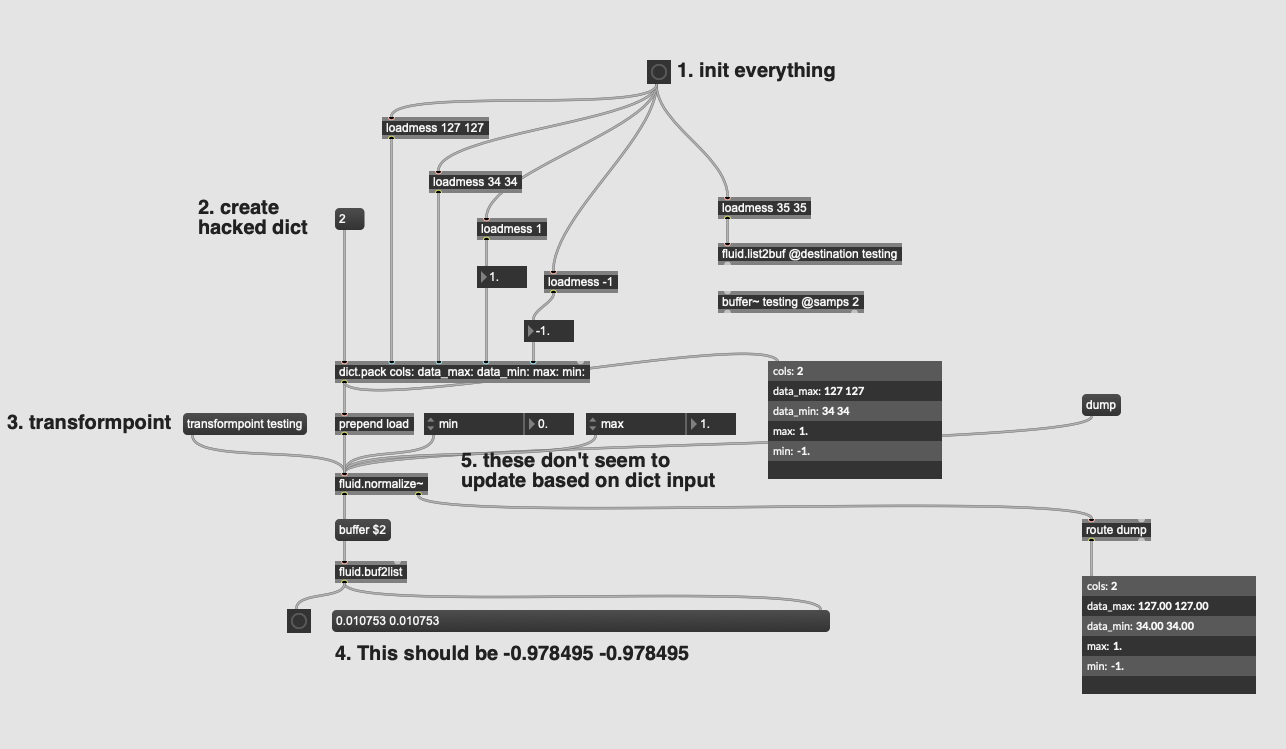
transformpoint again - the correct values are output
dump output reflects correct change
This leads me to believe that the dict is in fact being load-ed, but crucially not being defined as having been “fit”. And that for some reason load-ing values only partially triggers this, whereas manually editing via attrui and thenfittransform-ing does it reflect correctly.
actually, as usual, it is a lot more complicated than it seems… at the moment we have a strange behaviour of enabling the scale of the output (min and max) to be changed without refitting. To correct the current bug, I need to stop that behaviour. It is of no real cost, but it just means that the output range will be set at fitting time…
Let’s try that for now and see how it breaks the world in the nightly?