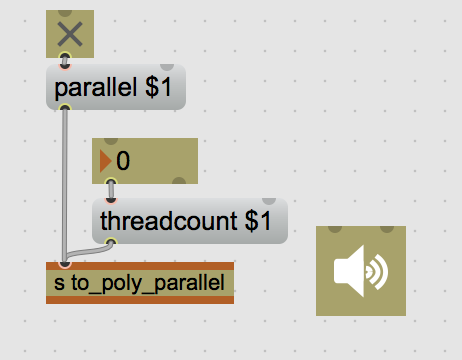
As my batch processing becomes more and more heavy while analyzing many descriptors on large sound sets, I’m looking into the option of encapsulating some of the code into a poly~ and run poly~ instances in parallel mode.
The surprising outcome of a test is counter-intuitive.
I tried several values of threadcount (always toggle dac off/on after changing settings). The fastest result is when parallel is set to off. Any combo of using the parallel option leads to longer overall calculation times. Anybody on this list being familiar with this?
And I think the results will be along the lines of what you’ve found. I (re)watched this the other day and @a.harker gets into why this can sometimes be the case:
(in short, the “cost” of making things parallel can often be more than the process itself takes)
Yes, as Rod has pointed out there may be an additional cast to spawning extra threads. There is finite CPU to use and if the maximum is already being used on 1 thread its unlikely that you’ll get a speedup by spawning additional processes. That said, I have seen significant speedups (anywhere from 25 to 150 perecent) by using a pool of threads and handing work to them in other environments. At one point I envisaged ReaCoMa doing this but found the complexity wasn’t worth it. Is your patch just n copies of a patch inside a poly~ pointed towards different sources and destinations?
I think he’s just running a batch process on many files, so a single process, running over and over.
I could be wrong, but I think that’s exactly the kind of problem that this wouldn’t be good for, since analyzing each individual file probably doesn’t take too long, there will just be many many of them, and the cost of spawning and synchronizing a thread is probably more than the process itself.
Way back around the first plenary (or maybe second) there was some talk of a ‘pie-in-the-sky’ solution of having the FluCoMa mac pro setup as a server that people involved in the project can sent processes to in order to let them render in a more powerful environment. That can obviously get complicated in terms of moving loads of samples around, but it’s another possible approach.
@tremblap also mentioned a cool idea of having a “robot” that keeps an ongoing version of your samples analyzed at all times (kind of like what most DAWs do with their render files). If you add new files, or specify a new analysis algorithm, it would then update what needs updating, so at all points you have some “analysis files” to work with.
Hah, funnily enough I made a very rough version of this when CLI was first released. It 100% won’t work now because so much has changed but all the Python code is legit.
Hmm, it could be interesting to have some kind of analysis specification syntax or header file-type thing, where you can say what you want (that spans objects/algorithms/time-scales) and then point it at a directory.
Kind of like a mix between @weefuzzy’s (or is it @tremblap’s?) automatic analysis thing and a server/CLI thing.
It could just run every kind of descriptor and keep them in seperate json files and then when you went to stats them or whatever then its your job. It’s a hard problem because where do you draw the line for configuration ¯_(ツ)_/¯
I guess I was thinking something like specifying the descriptors/settings/stats in some kind of syntax and then it would run “only” that. But it could be quite comprehensive, and then use the subquery-ing stuff to assemble the bits you need at any given point, which is kind of what you’re suggesting anyways.
In early 2000 I experimented with some sound batch processing and turned my max patch into a standalone application. I then copied this app 4 times and ran the four at the same time, each one getting a fourth of my entire sound collection to treat. As individual applications they tend to run on different processors. I will probably make a test with my current batch process next week.
@tutschku, if you’re doing non-realtime processing with our stuff, poly~'s threading won’t be of any benefit, because it’s creating DSP threads for audio objects. Our things run either on
the Max main thread (@blocking 1 )
their own custom threads (@blocking 0)
the schedulder (@blocking 2, if overrdrive is on).
(I guess, in @blocking 2 having ‘scheduler in audio interuppt’ enabled and running a parallel poly~ might put the processing on to the poly~ threads. But I don’t see any upside to doing this)
If you want to squeeze more out of your cores in Max with our objects, then using @blocking 0 and having a number of parallel chains (no more than you have available cores, I’d reckon) might help (so, yes to poly~ if it helps here, but you don’t need @parallel)
In general, though, adding more threads isn’t a guarantee of a positive performance change.
Yeah. SC has a multicore version and the vanilla version where you can run multiple servers. The multicore version can really only run 1.5x the number of processes as the single core. But with multiple servers, you can run N times as many processes, with N being your number of cores.
That is true for real-time processes (and as you know limits the exchange of shared data/buffer/etc via files)… but what @weefuzzy said earlier is that for the OP of doing batch processing, since our objects already spawn their own threads, a ‘single core’ SC should have the same result with N processing paths than 4 independent servers, with the benefit of being able to share datasets/buffers/etc…
Thanks for those details. I went with my old method and turned the patch into an application. Now I’m running 4 instances of it in parallel and it takes pretty much exactly 25% of the total previous time.
Unless I’m mistaken, running separate “top level patches” in Max does the same thing. Would just save you creating a new app each time you make a tweak to the algorithm.
Then I would need to change all my namespace (sends, receives and buffer names), as those are shared across top level patches. I tried with #0, but ran into some other issues.
I’m building the most exhaustive database possible with pretty much all known descriptors, mfcc, melbands and their derivatives on large quantities of sounds. This will facilitate quick switching between them when comparing the dataset inputs.
to reiterate the point @weefuzzy made: our buffer objects spawn their own thread, and do one task at a time, so having 4 jobs in parallel in the same patch (4 bufnmf for instance) is the same as having them on 4 different patchers at top level…
Having a poly~ to do that is just good to keep the upscaling easy to explore (changing the number of instances) but would have no difference than to load X abstractions sideways in a single patch.