Hello everyone I’m very new to max and flucoma, and was wondering the best way to have my mic input trigger the points on the fluid 2d corpus. [my 2d corpus has my voice recording]
For now I have managed to analyse the mic input in a similar manner and I have in a way made the mic input parameters make the highlighter move withing the 2d corpus (it’s not efficient and is stuck within one region)
1- Even though the highlighter is moving (however little) I dont hear the sounds- how do I make it work?
2- How do I ensure the highlighter moves accross the 2D corpus and is not stuck to one specific region.
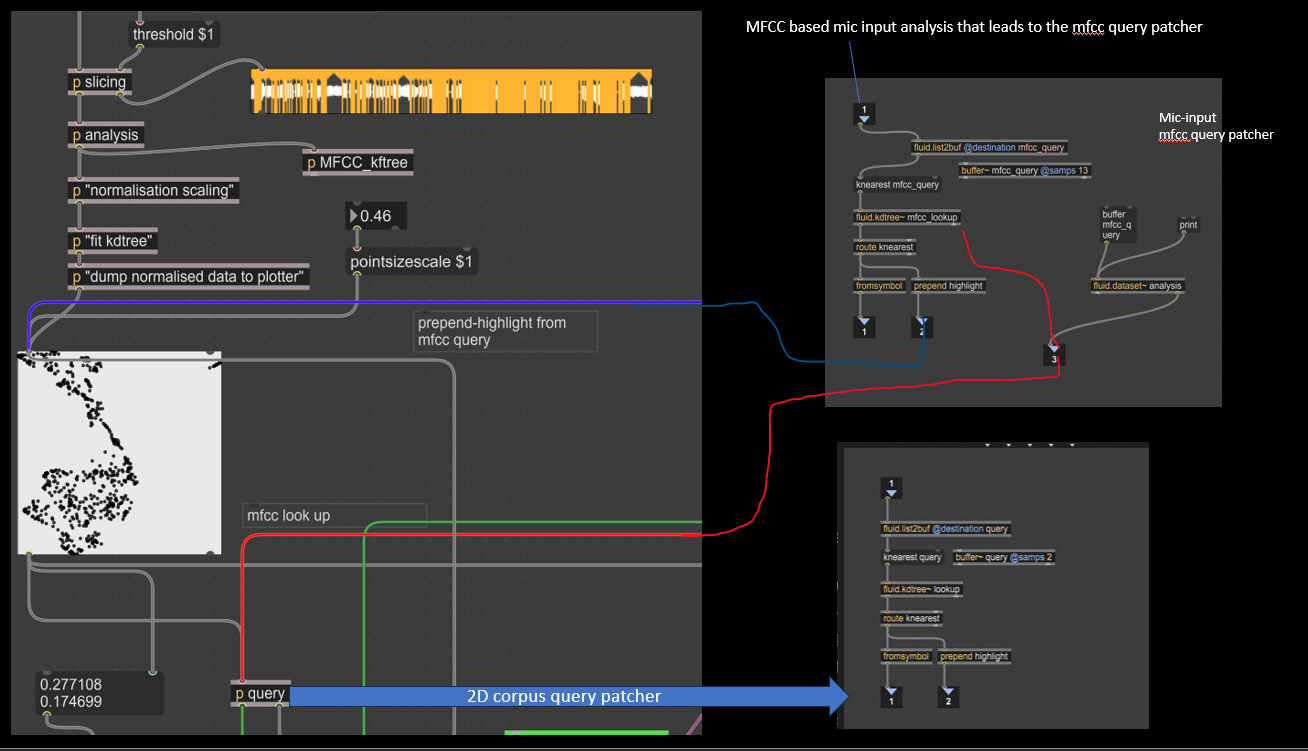
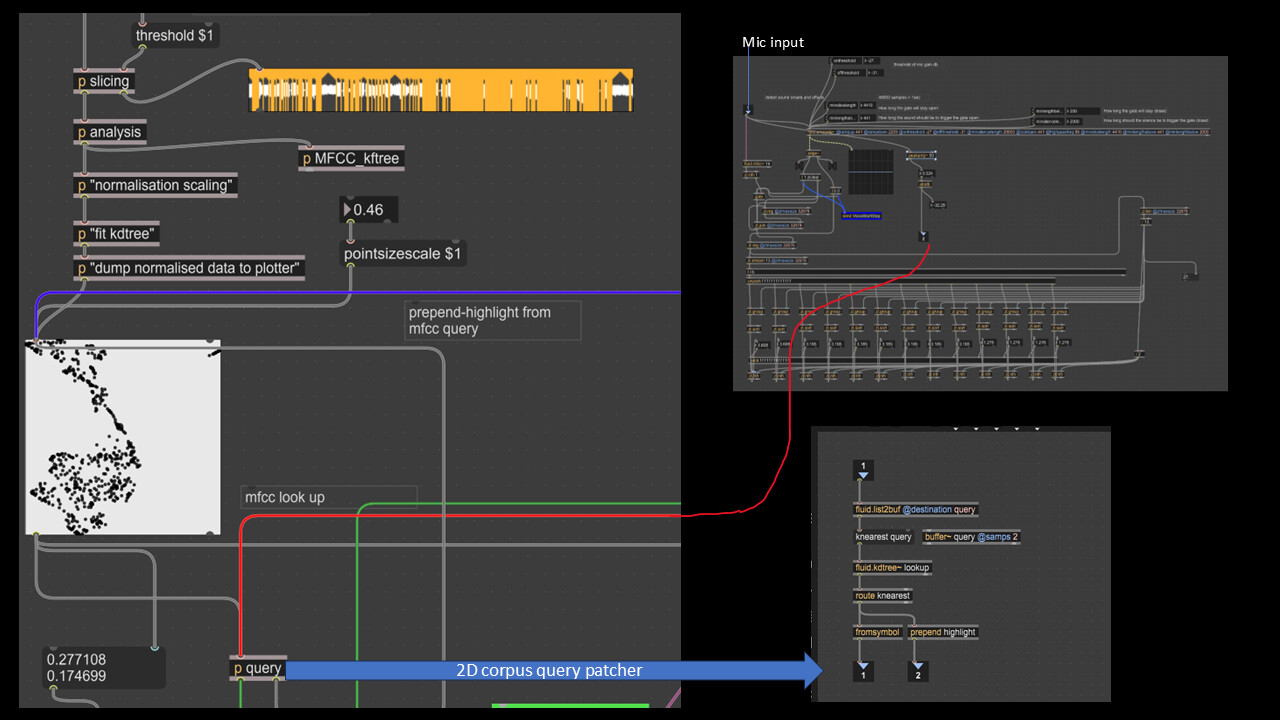
I’ve attached an image with my patches for you to better understand.
I am quite the noob in this world of max+flucoma, and I’m certain I’m doing alot of things wrong here and would appreciate any and every help possible. Thank you
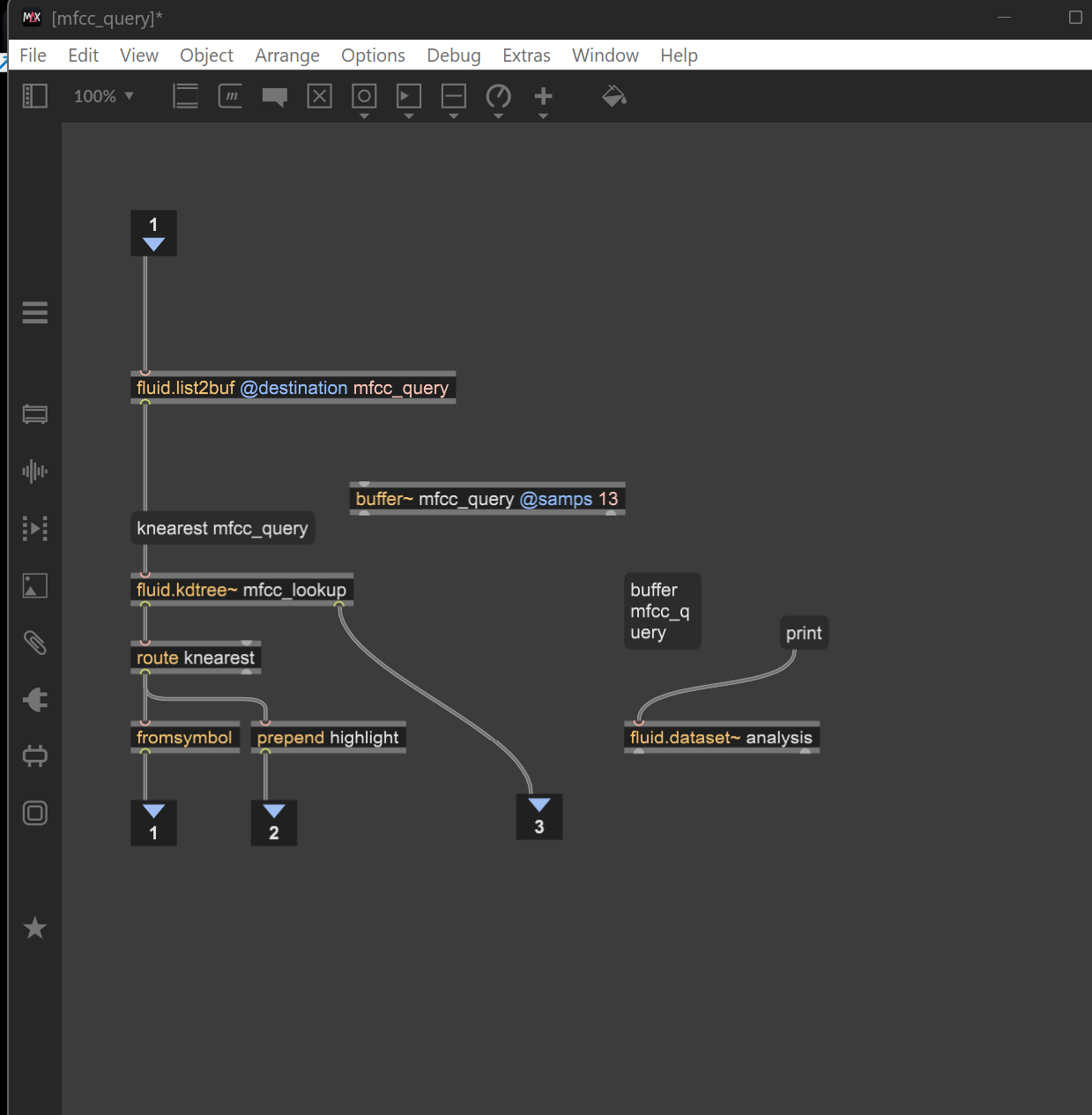
This patch looks ok to me although it is partial. I presume you are querying the original high-dimension MFCCs dataset via audio?
A good way to test is to replace your mic input by various sounds from the original dataset. If you find the right spot then it means you have that part sorted… and that your problem is not one of patching.
Once you confirm this, we can go into the next problem, which is more advanced: non-overlapping descriptor spaces. There are solutions to that ‘problem/state of affairs’, but you need to decide where and how you will compromise.
Hey @tremblap thanks for replying. I did replace the mic input with the sounds from the data set, It seems to be stuck in the same region - although maybe slightly broader but not significant. And I still couldn’t hear the matched data points that were hihlighted.
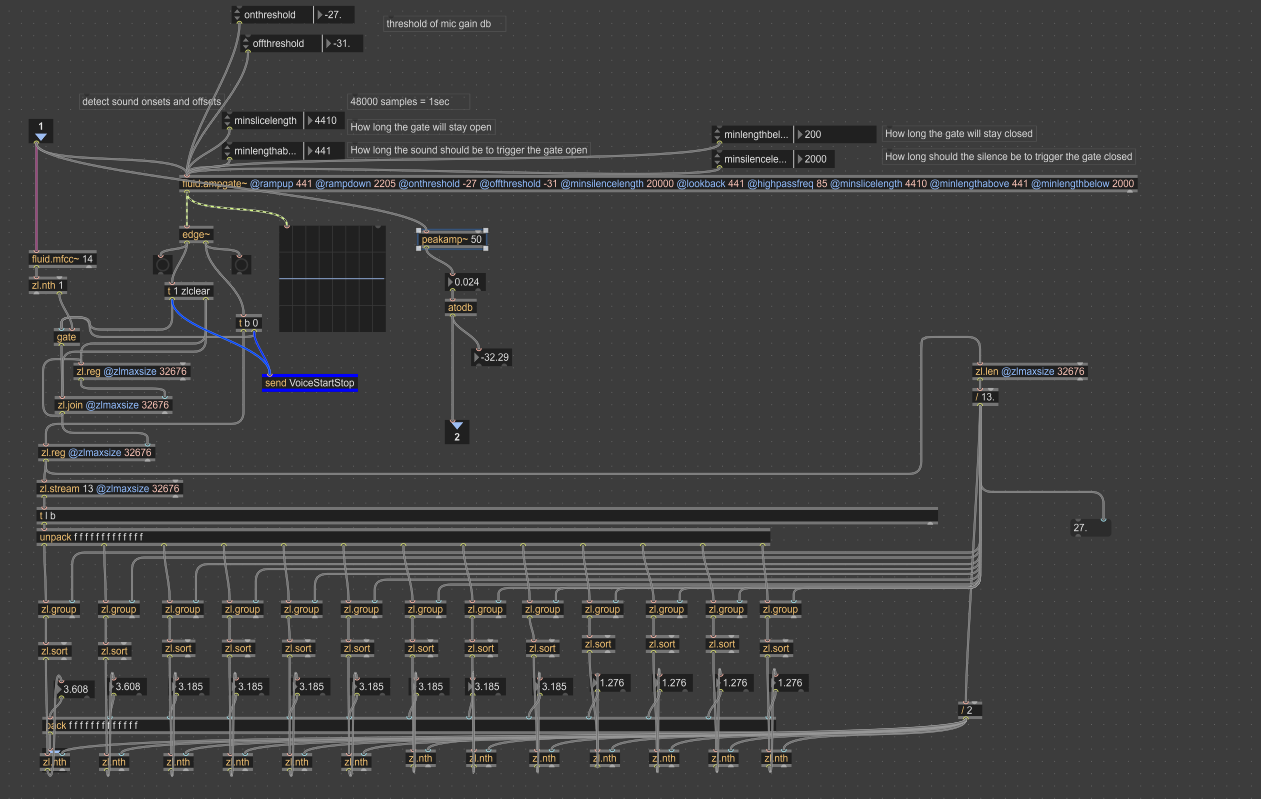
Here is the image of the mic input that is analysed. (Maybe I’m doing something wrong here)
And I also tried to then change my patching, instead of lookup from the mfcc query, I chose to get the peakamp from the mic input - that did solve the audio issues(that is now wherever the highlighter is I can here it. ) But it is still stuck in a new specific region and is very flickery , which is obvious considering the values I’m getting from the peak amp.
I don’t understand your mfcc processing in the patch… are you trying to pick the maximum mfcc value for each slice?
First, try to query with a simple frame, or a basic average, for a slice (between silences if I understand your use of ampgate)
if that, on the original material, does not bring what you expect, you have to sort that before using a live mic. it means that you are not finding the material that is already in the database…
The mfcc processing here is to help analyse short slices of realtime mic input, so the gate is trying to pick on the start and end points of when someone speaks, and then atributes do what they do . And essentially convert into a list to help query via fluidlist2buf. I’m still very new to this so not certain how to go about the ‘mic/ audio frame’ input to the mfcc-query,
How would you suggest I convert the audio frame/mic signal as an input to the fluidlist2buff for it to go through fluid kd-tree ?
this is good but will query too often… I would probably put a gate to trigger the whole process.
so you have fluid.mfccs → fluid.stats → gating → your patch just above
that way you smooth the mfccs and decide when you query. for the latter, it is very much dependant on your artistic decision. for instance:
you could query twice a second, starting as soon as the signal is above a noise floor
you could query every time the timbre changes a lot (using noveltyslice for instance)
you could query more frequently for louder signal
I’ve done all 3 in different contexts. the one thing to remember is that you always analyse the past. so another approach is a variation of #2, which is “every time you change, you analyse the next 120 ms by putting a ‘delay’ on the trigger” this is not dissimilar to what @rodrigo.constanzo and I have been discussing for years over here
An easy/instant way to test some of this stuff is to try out SP-Tools, specifically sp.corpusmatch which does what you are describing (though using perceptual descriptors rather than MFCCs).
All of it is built around FluCoMa so you can easily look under the hood to see how things are handled, including this idea of having audio input create analysis for specific audio frames.
This section of the original teaser video shows the idea:
And here’s another video doing a similar thing:
Both of these videos are using sp.descriptors~ → sp.corpusmatch → sp.sampler~ after you create an initial corpus using sp.corpuscreate.
For the MFCC analysis you can look at sp.mfcc~ for quick/realtime onset analysis, though it’s not directly mapped in sp.corpusmatch.
 Teaser Video")
