Hello
As you have read for many years, for all the projects and a decade before, I’m obsessed about playing a corpus with the bass. I am sorry if I repeat myself I now understand how impossible a generalized solution is, so I am embracing the quirks ![]()
So here goes an explanation. it is a draft of something that should maybe published on non-overlapping spaces on learn.
Previously, we spoke about that problem in various ways… here goes 2 basic examples in 2 d to show the problem.
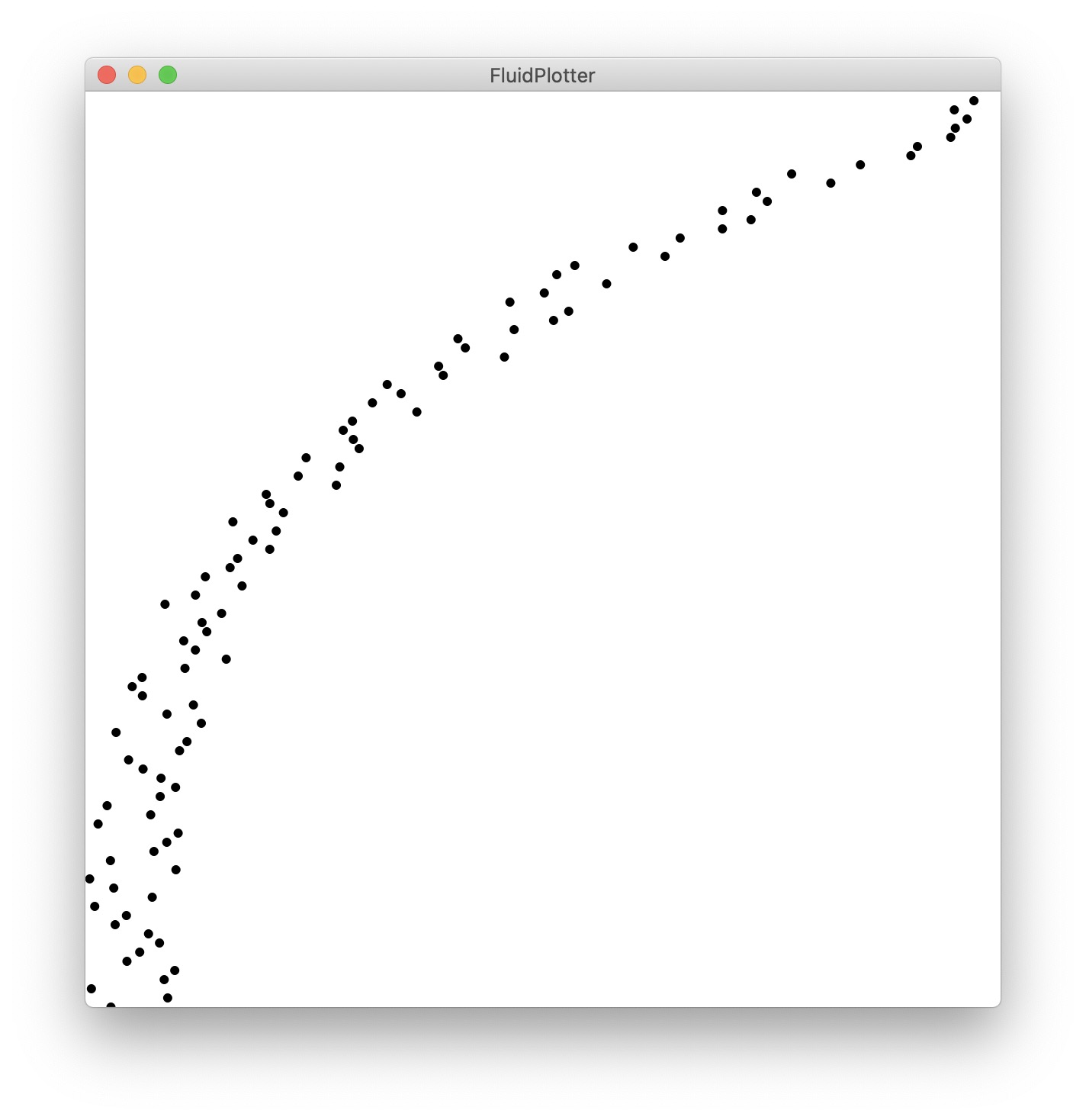

Let’s imagine the axes are pitch and loudness, to simplify (13 dim mfccs will have even more pronounced problems). We can see that both corpora are not well sampled. Now you might have a huge database where everything is covered, but most times we have pockets like this, and some sort of links between dimensions, and the sampling coverage. More on that later.
For now, let’s see them in the same graph:
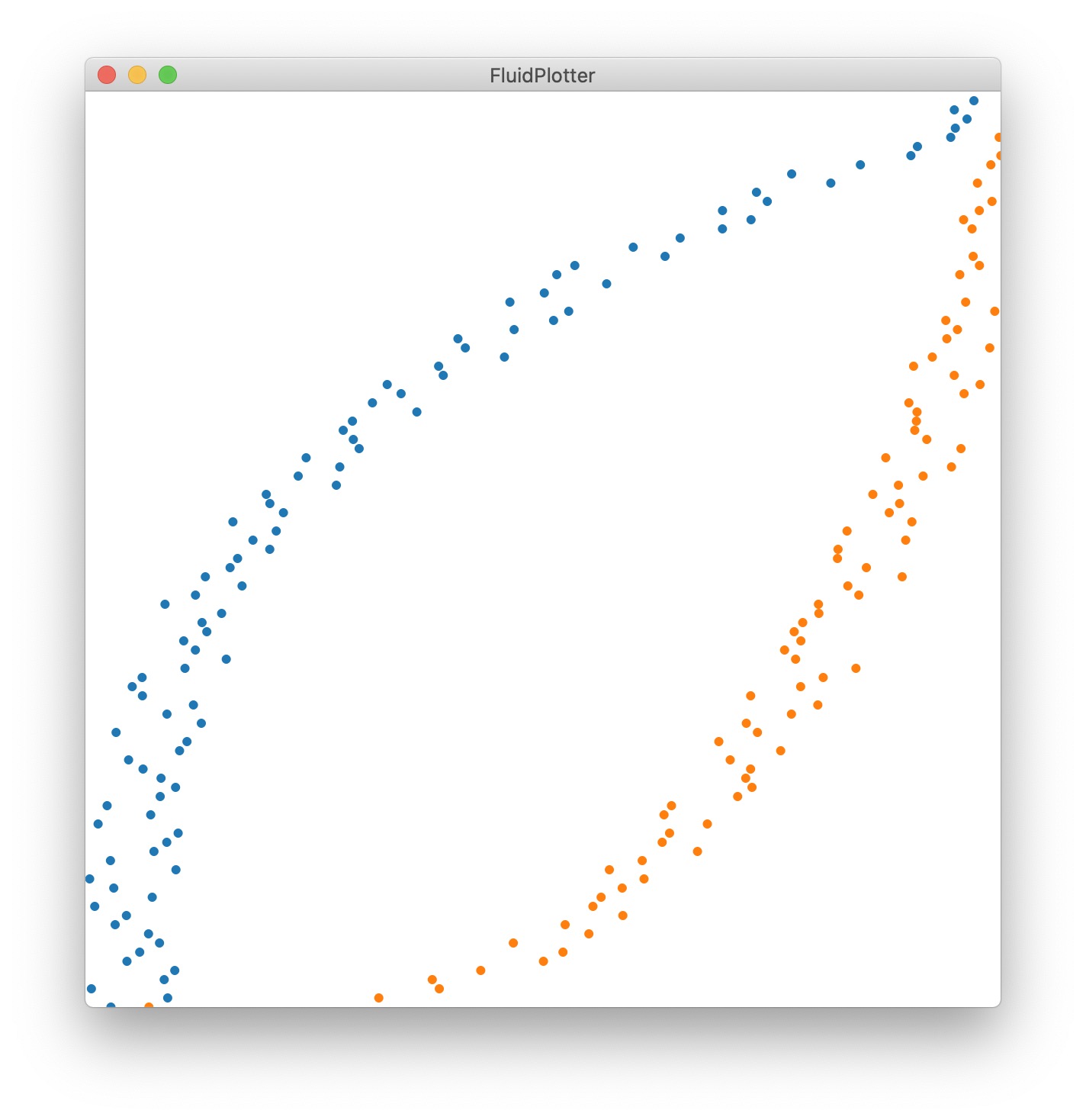
Now, you can imagine that if you look for the nearest distance in orange of a blue point in the middle, you’ll struggle to have musically significant neighbour…
no issue, some might say, just normalize! or even, just robust-scale, taking the 10-90 range of both… it helps a bit, but here is what they look like, each robust-scaled individually, same scale of plotting:


and together:
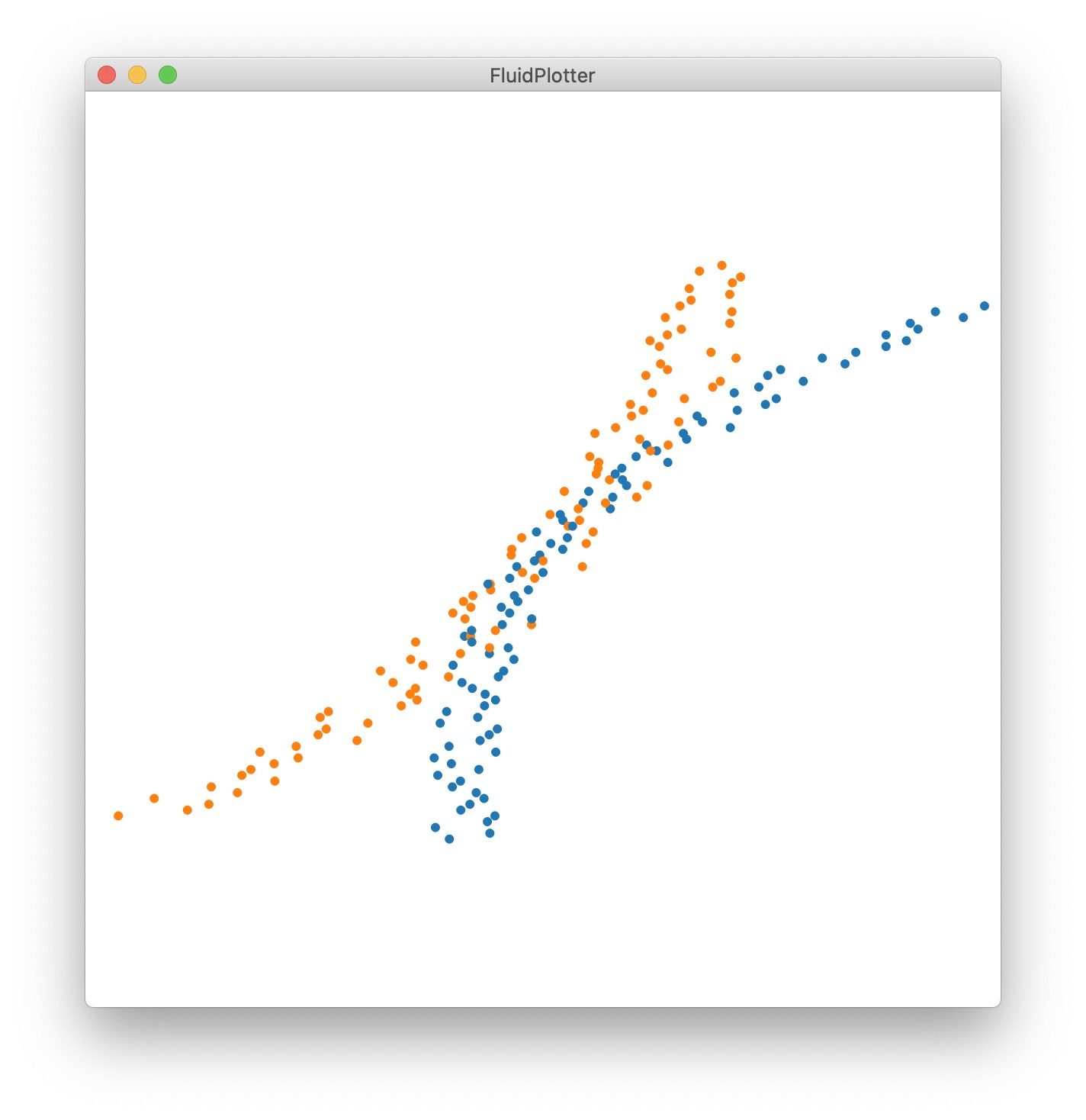
now, we have the opposite issue: the extremes are further and the middle might be more sensible…
one might say that we should normalise together, but that will make the original problem even more problematic: imagine the pitch range of the bass, and of the violin… the overlap is a very small subset of the space…
In an old instrument (2009-10), I tried 2 approaches using a modified version of CataRT. The full range together, and a simple normalization. I was hoping that robustScaling would be more interesting… so I coded it. It worked somehow but radically better… but what made it really more interesting was that I subverted our tools to smooth and adapt the robustScaling of the bass in real-time, giving the machine some sort of way to attempt to match my playing range as it evolves and interact with the musaiking. This is what I used in the set with @weefuzzy at Oto, I hope it should be on YouTube soon. The code is dirty but I can share if anyone is interested.
With this idea of machine-learning-the-space-and-doing-ad-hoc-mapping-I-learn-and-polute-as-I-play, and coming back to the idea of dimensions independence, the next step is to use PCA with whitening. The problem is already obvious that the spaces are going to be overlapped in range but maybe not in direction/relevance/dimensions but I’ll make another post about it. Just because I like pretty colours, here are the same datasets as above, PCA’d and whitened
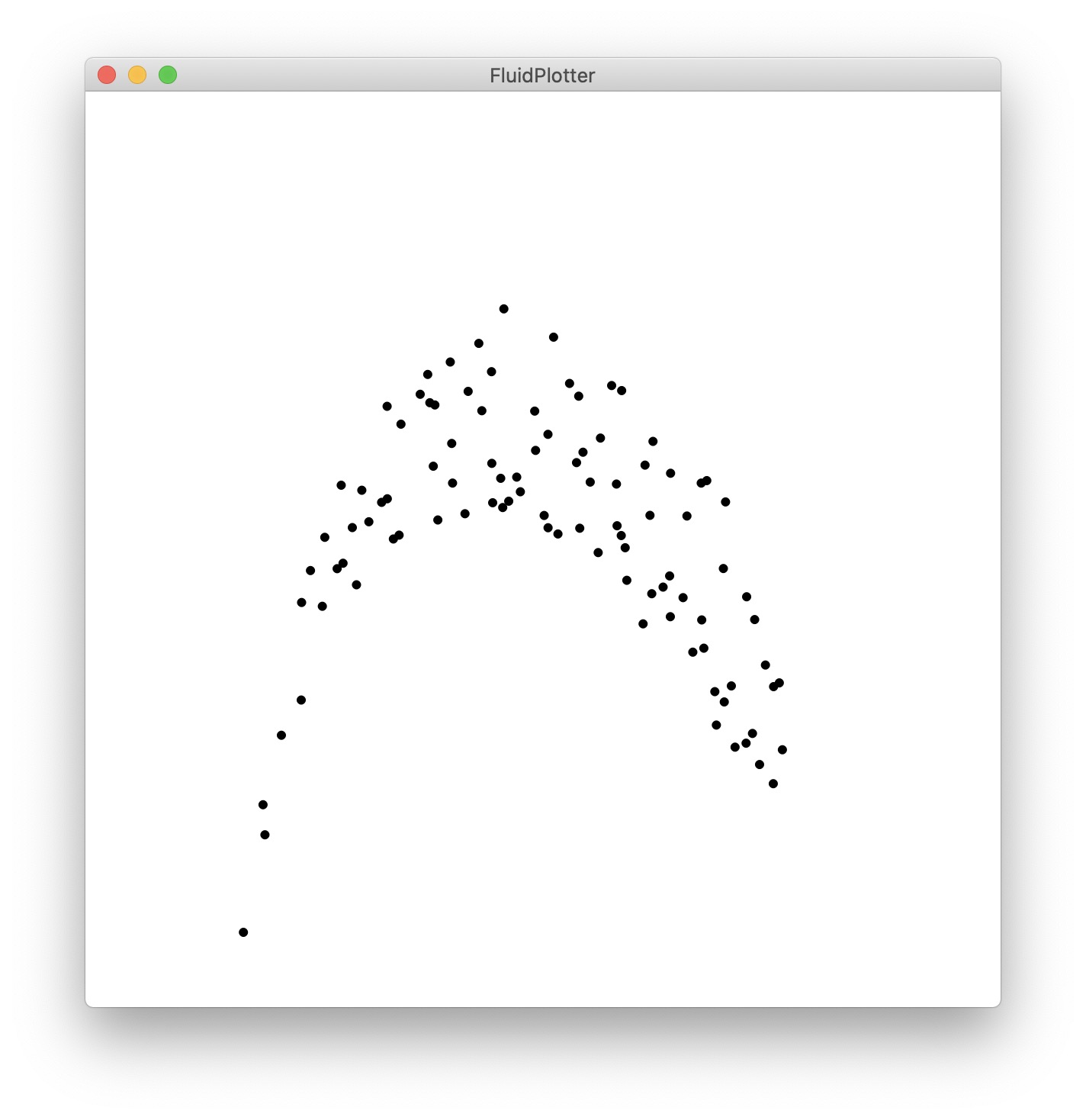

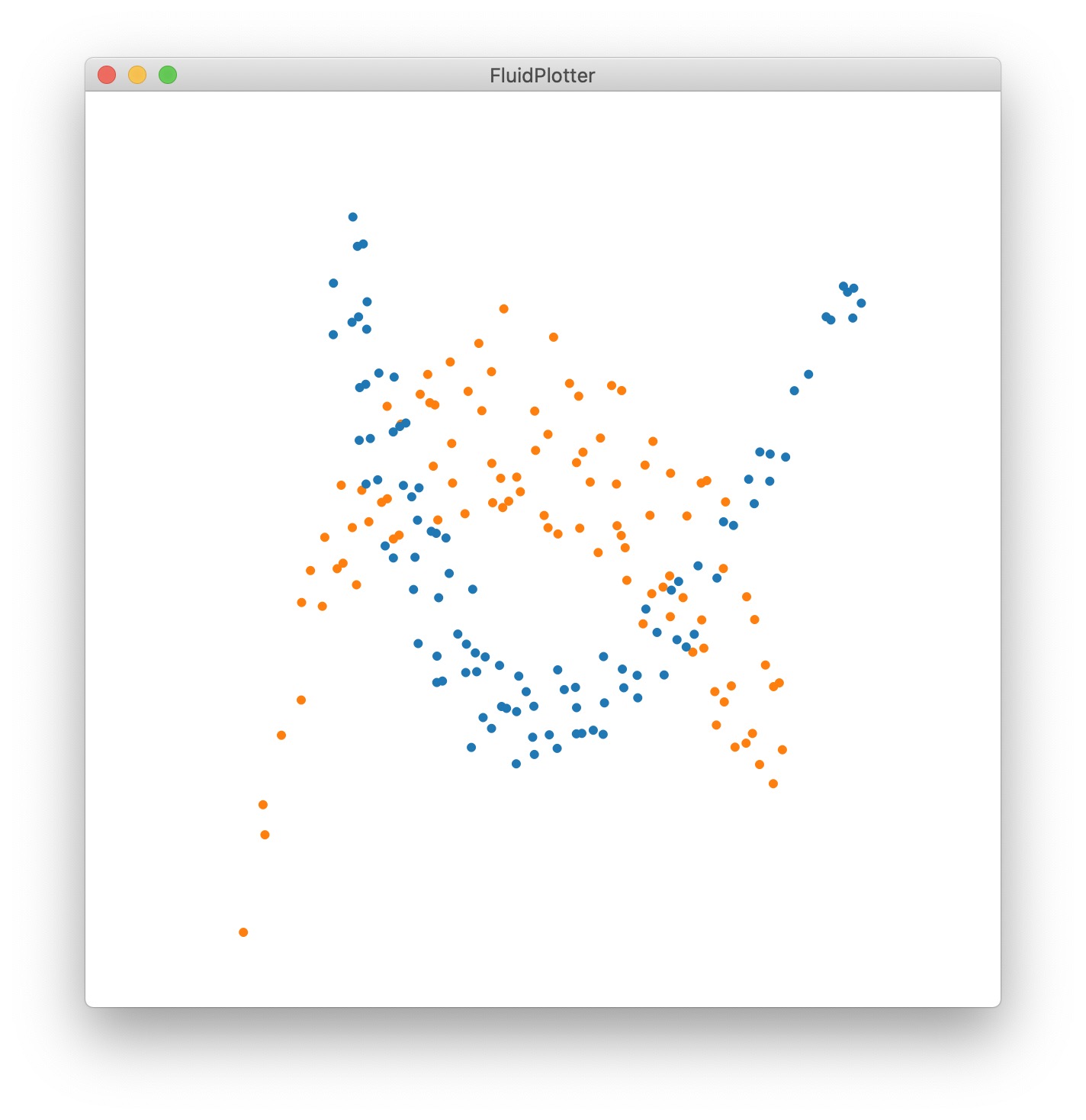
(although 2D to 2D is not super we can see that the dreaded flip happens… @weefuzzy will be able to confirm that if/when we sort this issue it will be more consistent but again, my gut feeling is that it will be unpredictable… but musicking with it will tell me soon ![]() )
)
In case you wonder, I also tried manual mapping of latent spaces, in a previous post from last year. And I currently have a timbral classifier that I map to techniques, a sort of symbolic process, which is working ok - I’ll share in due time.

