@lewardo - this is a good use case for your work in progress on this!
@weefuzzy is the wise one. I’ll read the paper tomorrow and try not to get excited
@lewardo - this is a good use case for your work in progress on this!
@weefuzzy is the wise one. I’ll read the paper tomorrow and try not to get excited
Super interested in this idea!
I tried (and pretty much failed) to do something similar with the tools we had available at the time many years ago in this thread:
https://discourse.flucoma.org/t/regression-for-time-series-controller-data/
The crux of it was some clever workarounds by @balintlaczko to get even close to something viable.
In the end it did do something, but had a really hard time doing anything “good”, and also suffered when it came to binary data (i.e. button presses).
I’ve not revisited the idea since (other than trying to do a similar thing with inter-onset timing generation last year) so curious where your explorations go.
Hello everyone – hope this is the right thread to ask – perhaps I should open a new one?
Very thrilled to test this!
I am trying to make something simple but I surely have not understood some basic stuff…
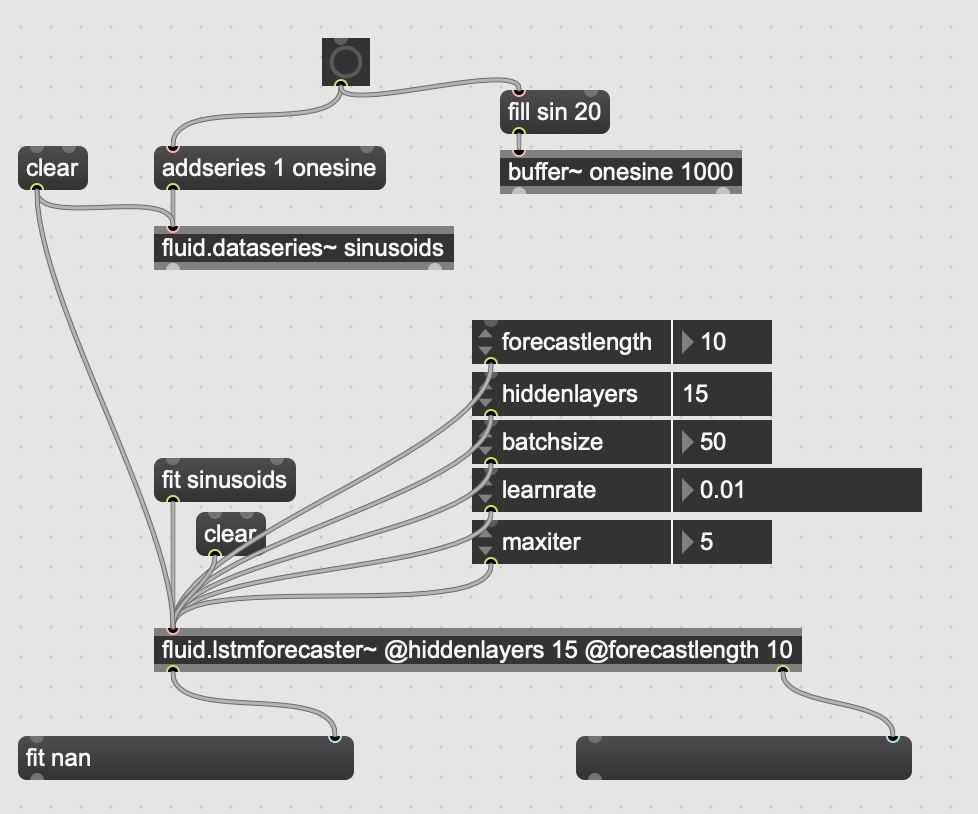
Basically, I’m just predicting a sinusoid. I’m creating a dataseries containing one single long sinusoid, and I’m trying to forecast it. Hoever, as I do “fit sinusoids”, I have “fit nan”. I’ve tried with different hidden layer configurations but it doesn’t look like it’s improving. Am I doing something wrong?
(By the way, where does one set the number of steps of backpropagation through time? Is there a hidden parameter for that?)
Thanks so much!
Hello! Thanks for reviving the interest in this very experimental branch ![]() I am recompiling a package replacement with 1.0.8 and will test and publish here tomorrow first thing
I am recompiling a package replacement with 1.0.8 and will test and publish here tomorrow first thing
Hello
So I’ve recompiled with 1.0.8 as my base. It took longer because I tried to include Windows version of the external…
So how to proceed with this:
Download the public 1.0.8 (or use the package manager)
replace the items as explained in this download:
I failed to do a windows x64 compile on my mac arm64 so that is that for now.
@danieleghisi all the examples work now, so let’s try to fix that with you, then I can try the sinewave
and thanks to @weefuzzy a x64 windows one:
fluid.libmanipulation.mxe64.zip (1.7 MB)
And I got it to work on sine waves. I cleaned up the patch and explain how it works, but after a meeting with @lewardo it was clearer how our current interface is implemented (and how it could be developped whenever I get funds to do so)
at point 3, if it stalls, I am clearing and restarting. Playing with network shape influences a lot the result, and it is fun.
lstm-sine-public.maxpat (28.1 KB)
Hello @tremblap , and thanks so much for all this trouble.
I’ve tried to follow your paths with this new release, but I’m still having some troubles:
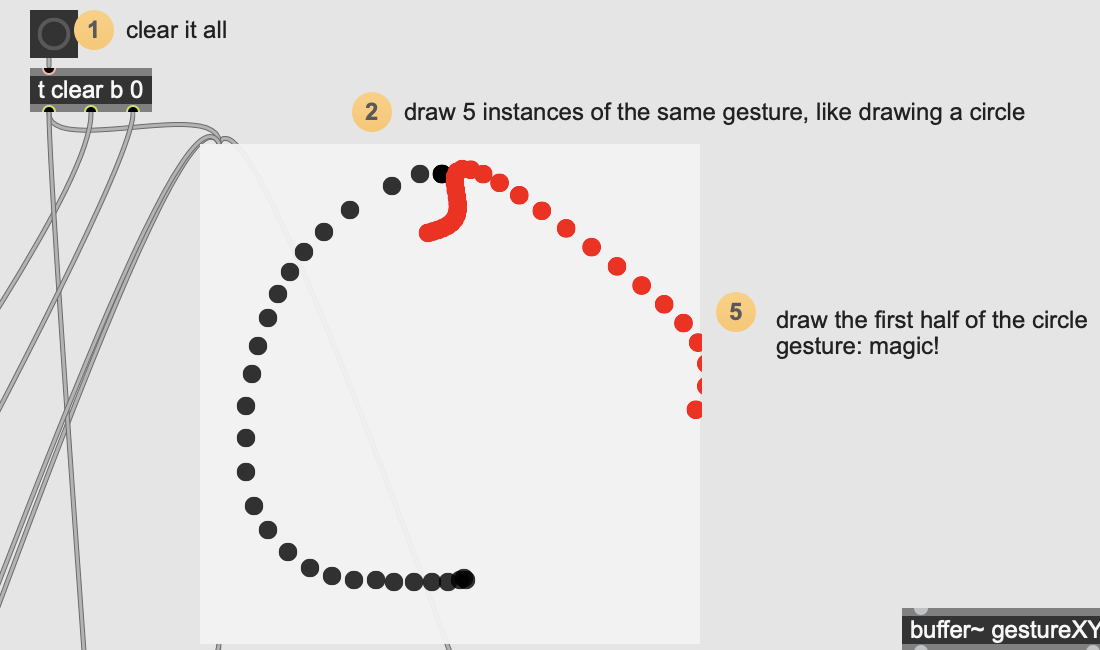
in the LSTM 3-forecaster-example (the circle one), I draw 5 counterclockwise circles, but then the forecast is kind of wrong
In your sinusoid example, I’ve followed your 1.2.3.4. path, but the result buffer is constantly empty
I’ve tried to change forecastlength from 0 to something else, but that didn’t help. Not sure what it does.
Does this work for anyone else? Perhaps it’s me…
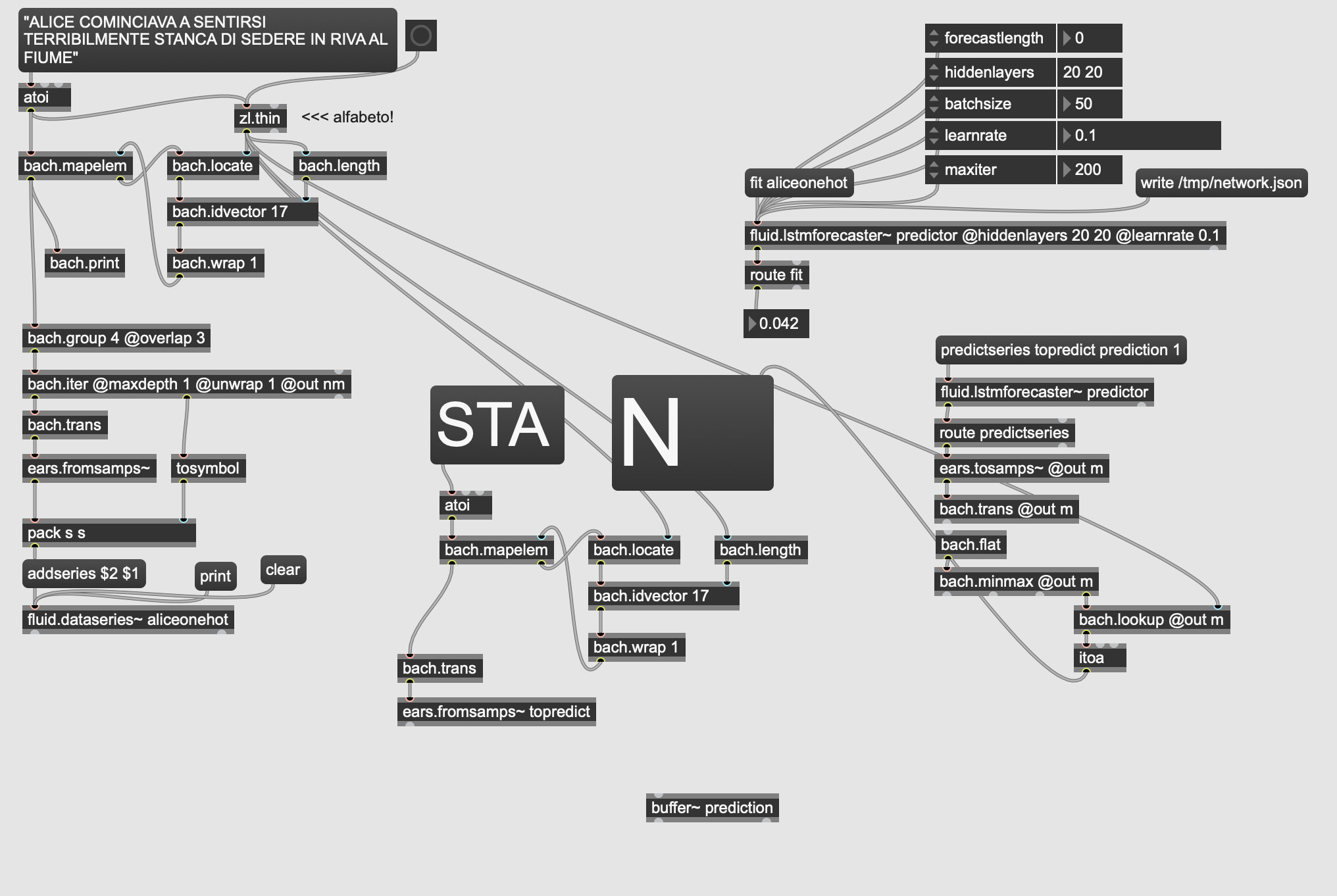
Also, I’m trying to understand how to extend this to more than sinusoids. My goal was to predict sequences of symbols from an alphabet – say, ABAAAACAAADABABABBB, etc. And, ultimately, text – and pitch sequences.
As I understand, you take a N-length buffer, and train the model to learn the N-th term from the first N-1, right? But in this case, if I understand correctly, this works differently than the mlp module.
The mlp regressor takes the dataset buffers and uses their samples as input neurons, so a buffer of N samples means N input neurons. I can tailor them, for instance, to one-hot encodings and represent letters in an alphabet (26 inputs).
How can I do the same here? Is there a multichannel buffer input?
If I input multiple channels, are they considered as each channel being an input neuron?
Thanks again,
Daniele
It’s ok - this is very early time in this interface and algorithm use. It was dismissed long ago for good reasons that will become apparent below - mostly that it makes the problem much harder, both in understanding and getting the right results (if only to get a network to behave!)
Actually, it is kind of right, considering what we feed it. On a simple feedforward network like a MLP, small dataset will be able to converge to a solution a lot easier than in networks with feedback. If you are interested in the why, I can post a video series that explains it very well. But let’s say that a training set of 5 is playing with fire, yet it almost makes sense. Try training on 1000 examples now… but nobody wants to do that training set, but that is another question - the manual labour needed to do good training sets…
that is strange… but how many times do you hit ‘fit’ aka how low do you bring your error to? For it to work, aim at 0.01 with a network structure of [15] or [8 8] although the latter was less fruitful.
Me too. In multidimensional contexts too (see below). But for now, we need to find a way to train it , which mean a way to get enough data to train it. Again, I can send a film on this, but let’s say that you usually need 10 x the parameters to train. in a network of 15 with 2d in (like this) we are talking (2 * 15 activations + 15 biases, plus the same for the recurrent long-term memory part, plus the same for the short term memory… so 135 just for the first layer… then the same for the output layer - @weefuzzy or @lewardo will correct me here but even if I underestimate, we speak 270 parameters, so we need 2700 elements in out trainingset…)
(note that the same maths apply to valid training set for MLP but maths are easier: a network of 2 in 15 hidden neurons and 2 out would have (2 x 15 + 15 and 15 * 2 + 2 = 77 parameters, so 770 as training set… but we get away with way less because we love overfitting and we don’t have feedback to mess with)
Definitely, and for that I recommend redoing (and telling me) where the DataSeries (ugly) tutorial is failing you. Indeed, DataSeries take channels as dimensions, and time as time. This is to allow time series of different lengths and is compatible with FluidBuf* features output.
I hope this helps? I am trying to put together some funding to do this interface research properly. Explaining this algo, and managing expectations, and encoding time (I’m learning about tokenisation too) is time consuming but I feel there is something there that might be fun to do systematic analysis of time series we could extract in our own datasets…
Not to derail things here, but wondering if something like this would benefit from an abstracted layer that deals with the hyperparameters and tuning options for you, then you take it from there.
Not exactly the same, but got great results with a friend using optuna to plow through a ton of MLP structures/learn/momentum/etc… and then spits out a .json I can load directly into fluid.mlpregressor~.
LSTM is obviously more complicated than an MLP, but it was super tedious to guess at a network structure, run it, then arbitrarily tweak arbitrary parameters manually.
Interface-wise, I guess as a user I’m mainly interested if it trained well and validates well. The specifics beyond that are not something I understand, so making it a “user issue” to have to tweak/test/modify/repeat ad nauseam is perhaps the wrong approach as complexity increases.
I know that @weefuzzy has wanted some higher-level things to test/validate data anyways, so perhaps something like this (automatic hyperparameter crawling) can be in the mix with that too.
the problem is that it is always a user issue… but yes we are trying to find ways to explain the moving parts so users can understand why it is their problem ![]()
Again, not to derail specifically from the LSTM, I don’t know that it’s especially useful for me (or any user) to understand all the details, facets, and nuance about gradient descent, and network topologies in order to train/use a regressor.
Unlike something like fftsettings where it’s a useful bit of nuance based on what you want, and the material etc… but in the case of most of these hyperparameter-y things, human intuition, and timescale/workflow, isn’t a good fit (for musical use in a creative coding context). I’d want to be able to give something an input/output, then have it crunch away and come back with some options, perhaps showing the tradeoffs as relevant.
If one wants to become a data scientist and work at an algorithm level, then yeah totally.
this is the same discussion we had about fft 10 years ago ![]() fft imply trade offs. data encoding and network structure imply a trade off. if you don’t own it, someone else does.
fft imply trade offs. data encoding and network structure imply a trade off. if you don’t own it, someone else does.
in all cases, I’m doing like I did 10 years ago: I’m learning and will explain in musicianly ways once I really understand what is useful and what isn’t. Feel free to park the objects until that is done, at the moment, anyone who want to try would need to get their hands dirty.
![]()
I mean, I’m sure there’s tradeoffs and nuance if you wanted to manually set your neuron weights but it would be absurd to work at that level, so you use an algorithm to sort that out for you. I’m just suggesting one level above that.
And indeed, we can keep arguing the same fight ad infinitum! I just want to a remain a techno-fluent music maker, rather than a musically-inclined data scientist.
that is strange… but how many times do you hit ‘fit’ aka how low do you bring your error to? For it to work, aim at 0.01 with a network structure of [15] or [8 8] although the latter was less fruitful.
No no – my error is much higher, around 1.
I’ve tried to switch to Max 9, install the package from scratch, substitute the files as per the instructions, but still I have the very same issue, so that wasn’t an installation problem.
I’ve made a video (on Max 8, but the same thing happens on Max 9):
https://www.dropbox.com/scl/fi/k9fhzv29j0f5zoh0ntmyf/forPA_LSTMflucoma.mov?rlkey=ipnk6c39g1lpaqovm7tzgrkmg&dl=0
Does this patch work for other people? Is it just me?
(@rodrigo.constanzo if you have a tiny moment can you just try it out and tell me if on your machine it works properly? I wouldn’t know what I’m doing wrong…)
Me too. In multidimensional contexts too (see below). But for now, we need to find a way to train it , which mean a way to get enough data to train it.
That may not be a problem – perhaps I may train the networks on the whole Alice in the Wonderland + Throught the Looking Glass, and I’m sure that should be more than enough. I had done this previously in python, and the results were ok.
Similarly, I may use lots of existing note sequences to train the network, producing the dataset isn’t an issue at this stage.
Definitely, and for that I recommend redoing (and telling me) where the DataSeries (ugly) tutorial is failing you.
Uhm, perhaps I’m missing something obvious. Do you mean this one?
https://learn.flucoma.org/learn/time/
As far as I can tell, it doesn’t deal with channels.
Or do you mean the [fluid.dataseries~] object?
As far as I can tell, [fluid.dataseries~] has no help file, so I wouldn’t really know where to start with it…
Sorry, perhaps there’s a tutorial out there that I’ve just missed…
—> CORRECTION: of course! It’s the 1-introducingFluidDataSeries one in the additional material. Sorry for the hassle. I’ll look into it. Still I’d be curious to know why the sinusoid example doesn’t work on my machine…
@tremblap I can confirm that the 1-introducingFluidDataSeries patch is amazing! ![]() sorry I missed it.
sorry I missed it.
Now I’ll try to find a way to make the LSTM work at all… I’ll try to play around with attributes…
… but it works!!! ![]()
That’s fantastic. A RNN object in Max, that’s awesome.
I don’t know why the sinusoidal example didn’t, but this one does seem to work!
Three further questions
I wanted 3 steps of memory, so I’ve filled the dataseries with sequences of 4 steps.
Is this correct? It seems to work.
E.g. to reproduce the Lewis Carroll text there will be sequences corresponding to
ALIC
LICE
ICE
etc.
the final number in the “predictseries” message is the number of predictions, correct? If I set it to more than 1, will it compute the predictions autoregressively? Which means:
will it compute, say,
C from ALI
then it will use LIC to compute, say, E, and so on.
Am I correct in interpreting that the output will work like this?
…and perhaps more delicate…
I’ll be shooting the course in june/july and the post-production will take probably until september.
Do you have plans to include these objects in a forthcoming official release, even if experimentally? Do you any idea of when this will happen?
Just to understand whether this may be a good route… (
Thanks again!
Daniele
2 good news and 1 bad one:
examples of pending questions:
so, if you are excited about this, let’s build that grant together. for me, we need to do it right, so we need iterative design… and commissioned artists to fight the interface and learning and assumptions to make it as good as FluCoMa, if not better: as good as Bach ![]()
Now, if you have a use now, I will maintain what is here for the next year and might be able to add a few things, and all of that might happen if someone feels like coding all this for free is a possibility. I’ve tried to bribe the main 2 contributors and I am learning the depth of our c++ to try to get there as fast as I can.
another set of questions that is now in my head… and quite everywhere in the lit… time encoding, context, tokenisation
again, how to think about time, its segmentation, its encoding, how to enable creative coders to do all that, how to teach it in a musicianly way, etc
so much to do, so little time…
- definitely for now - this is the way it works. By default 0 gives you the same amount of your input and any other number will just feed the network as you described
I’m no longer very sure, I’ve understood though.
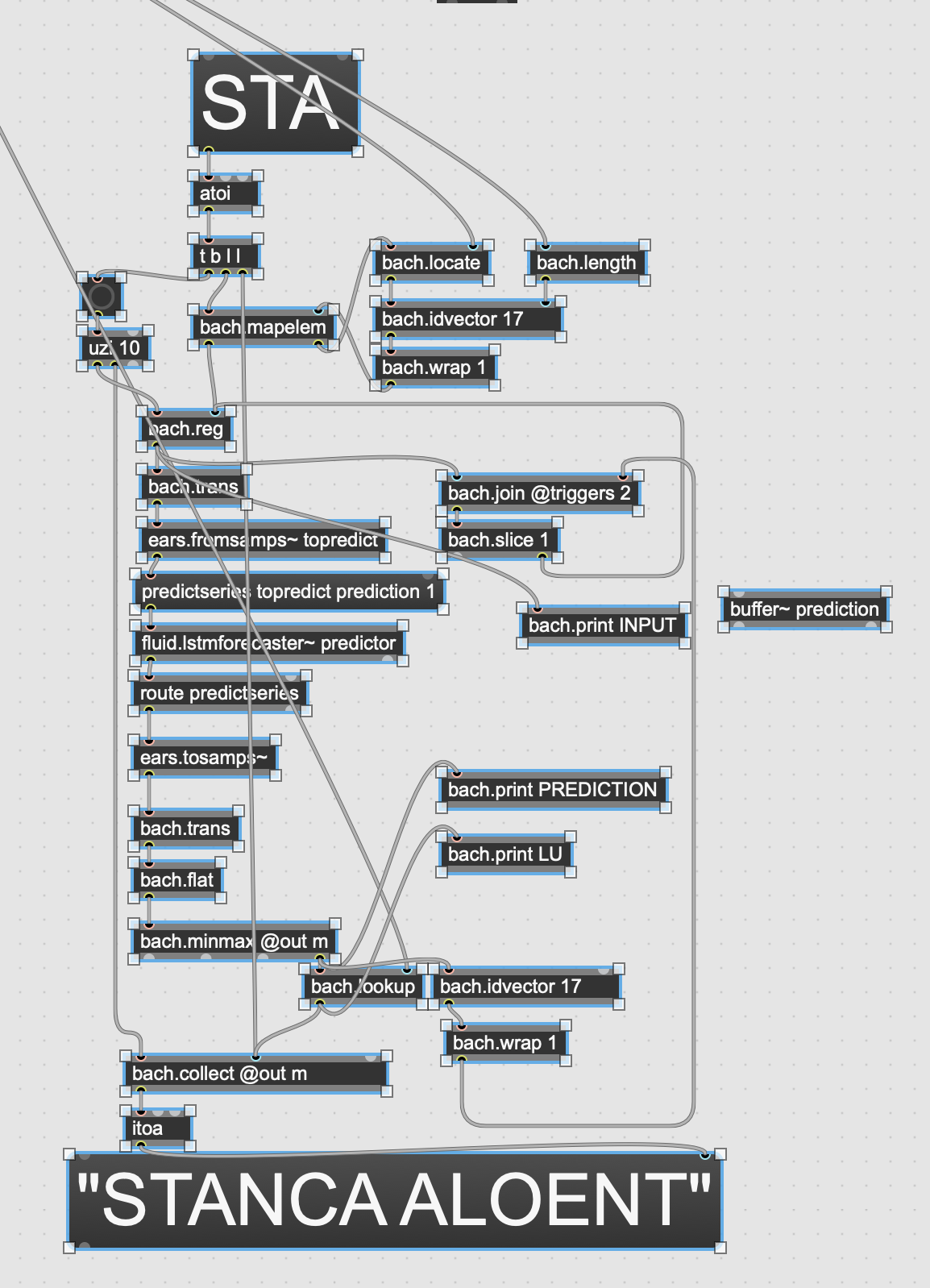
My @forecastlength is left to 0 – what does this attribute do?
I’ve tried [predictseries topredict prediction 10] and I don’t have 10 meaningful samples to continue, I have
NCNTNTNTTT
These look like 10 different possibilities for the same continuation after “STAN”.
On the other hand if I code the autoregressive behavior manually, then I get something meaningful such as “STANCA ALOENT…”.
My guess is therefore that the number of extractions isn’t extracted by taking into account each new extraction, but of course I can be wrong.
- definitely not. we are talking years here I think, to get many things right that are so rough now it is not funny
That’s the worst piece of news! ![]()
Can I suggest to get them in in the meantime as “hidden” undocumented objects? ![]()
to make it as good as FluCoMa, if not better: as good as Bach
ooooh, don’t make me blush! bach is full of undocumented little corners ![]()
Jokes aside, of course if this takes years, I completely understand – and that’s a thing I’ll have to keep into account.
I’ll talk with the guys that produce the course. You see, I think they want the course to be available for the next N years, so I want it to be solid, I can’t change anything later on. So if this isn’t something you plan to release soon, I will have a hard choice to make.
I’m really torn because I was dealing with Markov model and LSTM is a good example of how sequential prediction could be made more flexible.
But I don’t think there’s any other RNN object out there in Max, am I right?
Thanks again for everything!
Daniele