I’ve updated the interface so it loads right from JSON
I’ve removed the T in the printing to avoid confusion
but the fun stuff: a recurrent neural network and 3 objects! The usual Classifier and Regressor with their classic example, and a forecaster - predicting the future!
Now we chose LSTM as a RNN. Feel free to watch any of these.
I’ll look at it in more detail, but a screencapture/walkthrough would be helpful for these as it seems like things/presses are expected between numbered steps (i.e. just following the steps on their own does nothing in the lstm examples).
LSTMclassifier steps 1 to 8 as described works here. fit until happy low number, obviously. Might have saved in query mode but that would give some read “no data fitted” which you didn’t report.
LSTMregressor steps 1 to 10 works here too, and so is LSTMforecaster steps 1 to 5 (6 and 7 are optional)
Yeah there was an error that was preventing from the first one of working. Then it wasn’t clear if I was meant to press/log/save something after each step.
With a clearer head this morning I (think I) got things to “work” but I don’t think correctly.
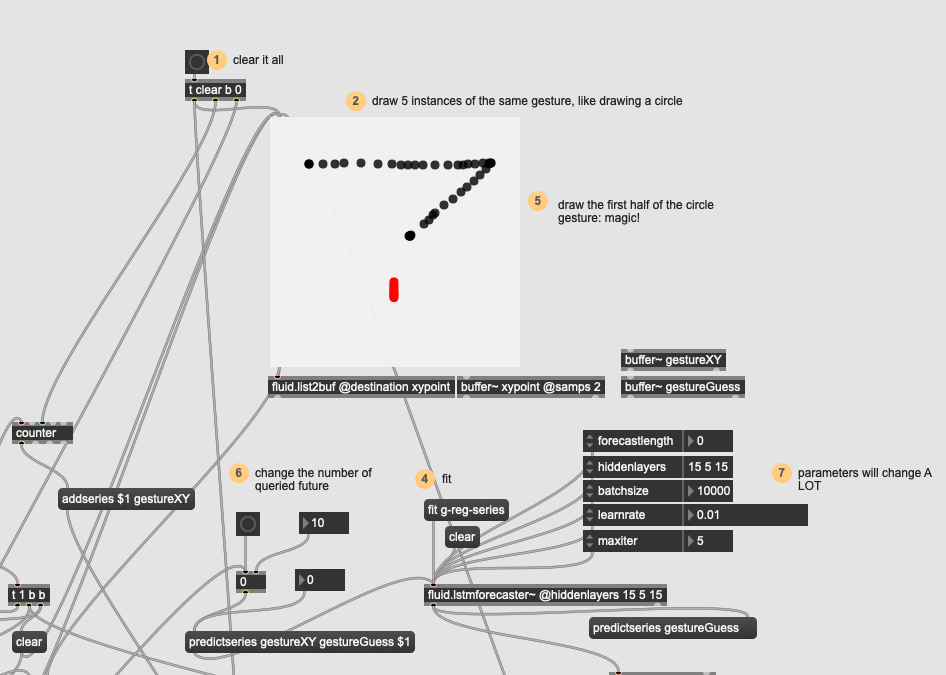
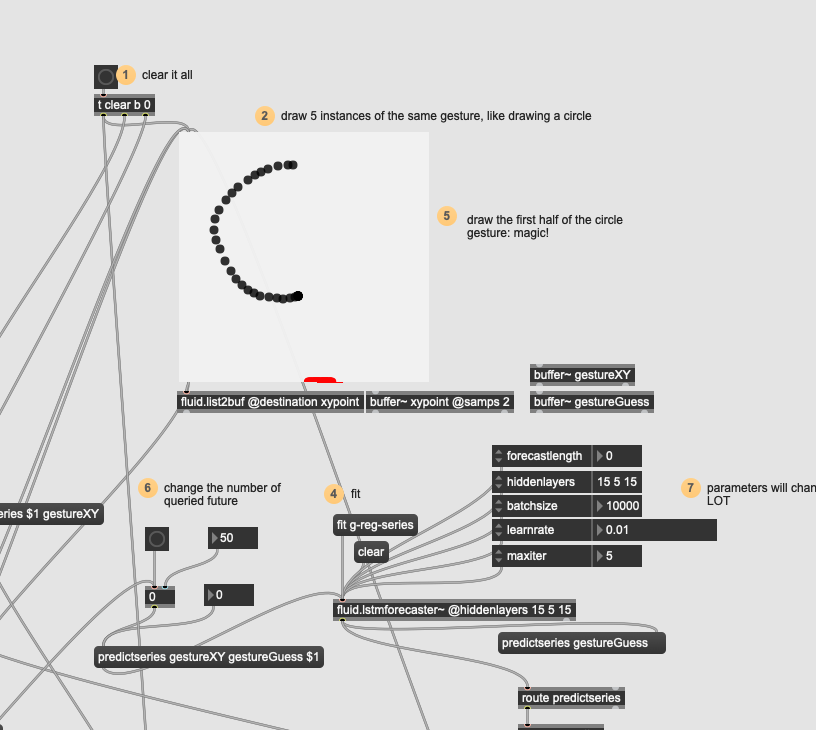
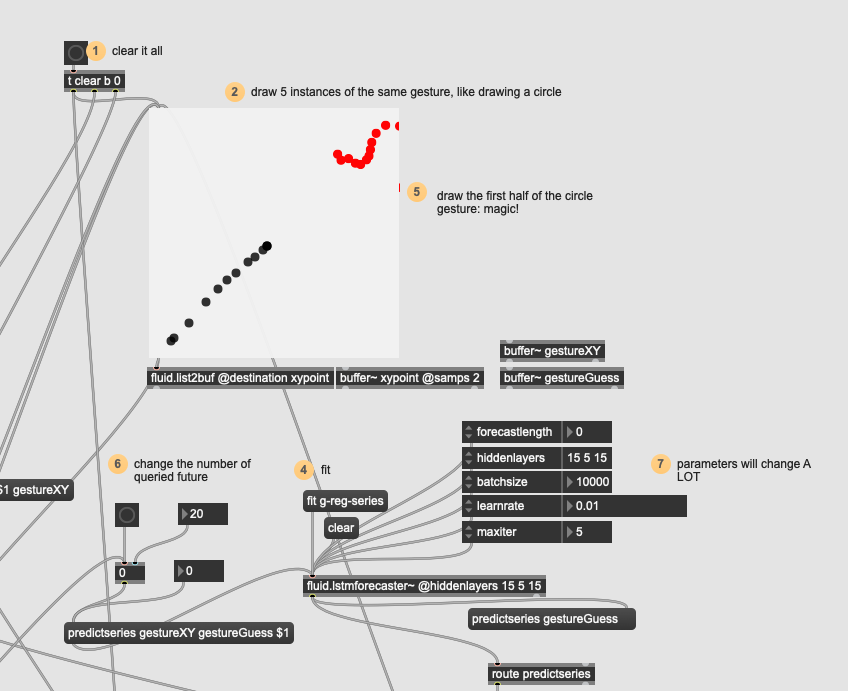
I can’t get the forecaster patch to make something other than a straight line (when training it on a “Z”):
Ok, tried with something really simple (straight line), trying to do the same amount of points/orientation/pacing and made sure the fit got really low (0.03) and this is about the best results I can get:
ah welcome to the wonderful world of RNNs This is why people who really know about this didn’t want to include them for us - they are INCREDIBLY finicky to tune. @weefuzzy would say it is irritating, @james would quote him saying it is handwavy, @balintlaczko might have wisdom, @lewardo too… @Chriskiefer is wise too. @groma too.
but listen to the videos - huge datasets, huge training time, huge machines.
so play with it and if we find it is useless, we just kill that branch and not include them. I almost didn’t make it public for that reason…
now I need others to play with them. i have a few ideas to poke at them too but it is a slow process.
In this case it’s more about not being certain that I’m doing the correct thing at all. The “line” version at least is in the ballpark of a line whereas the other two shapes aren’t doing anything at all.
And obviously the answer to everything is "It Depends"™, but does huge datasets here mean drawing circles 50 (50k, 50M?) times, and does huge training time mean 5min (vs clicking “fit” 5 times) or 5h etc…
The loss in that line example is super low, but it appears that the output is sinusoidal at almost all times (for this diagonal shape at least).
edit:
I guess to add, having “heavy” algorithms in the mix is nice, if they enable different/useful functionality. IMO not everything needs to be limited to things that can fit/build in like 30s. I am not bothered about having things train for an hour, or overnight, if it can do something cool. So if that kind of thing is the scale of stuff, knowing that, and knowing how to implement/tweak that is handy.
I am interested in experimenting with the dtw~ algorithm. Although, I am somewhat worried by the brute force search strategy. I have a large dataset which may involve a serie of 20.000 descriptors of 12 dimension, and I would like to find in this dataset the best match with a smaller serie of about 20 descriptors. Do you think that the dtw~ is a reasonable solution for this kind of problem?
Moreover, I am currently running the flucoma 1.0.7 version in Max and I was wondering whether the build that is posted here (max-v3.zip) is compatible with the flucoma version I am currently running.
I can build another version - let’s see what is @lewardo’s horizon for the fast-dtw and if not within the next week or two, I’ll compile the current LSTM+DTW+FluidDataSeries tip with tip of 1.0.7
ok just for you, I’ve compiled 1.0.7 with all the dataseries stuff inside. It is unsigned code and untested, for MacOS. Please let me know if anything goes wrong.
Thank you @tremblap for this! I’ve tried the examples in SC and all seems to be running well. I am now trying to wrap my head around how difficult it would be to implement a prediction system for outputing continuous (control-rate) control data similar to e.g. Charles Martin’s IMPS written in Python (works fine with sending OSC to other applications, but a “native” SC version would be tempting): https://arxiv.org/pdf/1904.05009