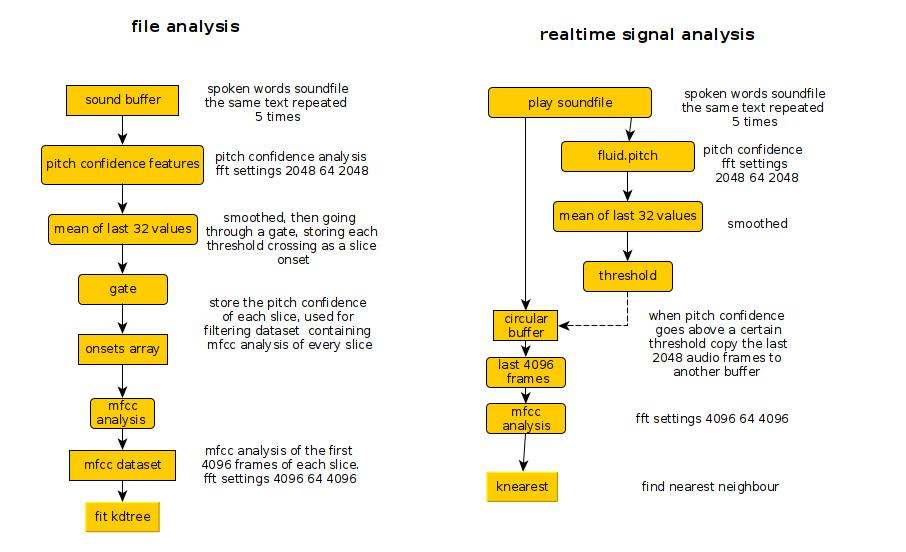
I’ve been experimenting with slicing according to pitch confidence, for later mfcc analysis of the slices, even though the results are already quite usable, I wonder how I should go about improving what I’m doing.
I’m slicing some spoken word poetry, the text has been recorded repeated 5 times then sliced and analysed, then a realtime slicing and analysis of the performer adds voices to her voice, with variations on speed / pitch / slice length.
Since I’m new to most of flucoma’s concepts, I guess I’m doing things wrong on a few levels, I have a lot of information to process each time I have to do something.
I thought I should ask here about how to be more precise, and if there are tools I could use to be more efficient in my current task.
Here’s a schematic of what I do:
This all looks very plausible. If you put some code together it might give us more to chew on!
On the right when you say “copy last 2048 audio frames”, you’re referring to the last 2048 audio samples? But just below that you say 4096 audio samples?
If you’re only looking to analyze the previous 4096 samples on a real-time audio stream, you don’t need to do a buffer copy and analysis, you can just use one of the real-time analysis objects with a window size of 4096. That might be what you’re after!
also: be wary that fluid* objects will give you values every vector size (kr in SC) so you have to sample manually every hop size (64!!! might give you some jittery stuff, so I’d probably try symmetrical and asymmetrical windows on that flux to smooth out a bit)
I was using buffer cause I did that previously in another patch , to be able to check visually what’s happening ( waveforms of slices, arrays of mfccs ) also I weight the stats. Then maybe I should try and stay simple… But this way I feel I can learn more, know more about what I’m actually doing.
As soon as I read that I prepared a patch to send. It’s a pure data patch though, I bet pd gives headaches to ‘SuperCollider Warlocks’. The patch I attached is already a tiny bit modified after reading tremplap’s commentary.
I noticed it was jittery, so I smoothed out the output of fluid.bufpitch.
What do you mean about "symmetrical & asymmetrical windows "?
I uploaded a version of the patch modified so it’s quickly testable for people on the forum willing to check it.
I previously made a similar patch with “fluid.ampslice~” that was better at getting the right slices, this one is an attempt at slicing according to syllables ( more or less… I don’t need that much precision)
The sounds will end up being played by 20 micro-controllers on 40 tiny speakers amongst the audience, the microcontrollers will get the information about with slice to play from my pc which does the analysis on the performer’s voice.
with the previous version ( ampsliced ) if I played the sample I fitted the kdtree with, it would match perfectly. And work ok-ish with the test sample.
This version ( pitch confidence threshold gate slicing ) if I played the sample I fitted the kdtree with it works ok-ish, which is why I wanted to ask here for help.
when signal is jittery, normal (symmetrical) smoothing is good for certain things… but at times, if like @rodrigo.constanzo you like fast answers, to make the direction in which you care faster than the recovery (like a compressor) is useful.
In this case, if you want to trigger as soon as confidence is high, a fast raise slow fall follower (assymetrical) might be more exciting.
Pitch ( weighted by confidence , mid )
Spectralshape ( centroid & flatness, weighted by loudness, mean with 1 derivative)
And then use PCA ( or umap ) to reduce the number of dimensions to 4 before fitting
the kdtree.
Using conditional stuff like this can be quite effective, especially as you can use conditions that are not then present further down the list (e.g. use confidence to fork a process where you then don’t use confidence to query anything).
Looks like you’ve got some stuff going already which is great. The only other thing I’d add is that where the window happens can be quite important (though less so for speech), so things like rolling realtime analysis ala Ted’s suggestion can sometimes mean you aren’t sure exactly which frame(s) you are interested in, and smoothing can become problematic. Hence the rolling buffer with fixed starting points approach that I often use where you can be certain where/what you are analyzing is what you want, then tailor everything else around that.
Indeed, I was not successful trying this method ( but I might have done something wrong )
This method gave me usable results, then with the same audio used to fit, and to classify I’m not able to find the same frames. This makes me think I could be more precise, efficient in the slicing.
I want to be as efficient as I can because we have limited time to work together with the performer, I’d like to have minimum (bad) surprises.
I’d need a pd-flucoma master to have a look at why my slices are not the same, I spend a fair amount of time trying different things, I stopped just before nosebleed.
Easier said than done.
I bump into a whole new batch of informations to digest ( thoguh I found answers in the topics here, I wish I discovered Flucoma in 2020, not 2024. 2020 was a good year to spend days and days exploring…)
But this is one of the reasons I have a hard time with max…
The real difficulty is the amount of things I did not need to know before Flucoma, (& maybe my brain cells connections ) I’m going touring for a while, when I’ back I’ll try to decompose this slicing problem so maybe one of you will notice where I’m wrong. When I read my posts on this forum I notice my questions about my issues are often not the good ones… But I’m getting more & more used to the concepts.
As @tremblap mentions, the algorithms should behave exactly the same in the buffer and realtime versions, so it is likely something is different in either your windowing/fftsettings or your realtime vs buffer onset detection.