Not entirely sure what to call this, but I got the idea today that it would be interesting to do the short term matching I’m presently doing/planning (e.g. 256 sample analysis/matching window) while still retaining a semblance of morphology of the samples being matched.
The way I’ve done this up to this point is to use additional descriptors/metadata to bias the query where I can match the initial window, but then use something else to choose “sample length” or other such variables.
This works super well, but essentially gives me only two modalities. Either vanilla mosaicking where I query/match grain-per-grain and get a granular sound, or the short-to-long matching where I use a tiny window to play back an entire single file.
I’m now thinking about doing something that’s a bit in between both. That is, doing something mosaic-like but retaining as much morphology as possible from the sample being played. So what I’m thinking is a sloppy/“fuzzy” version of with AudioGuide does with its frame-by-frame matching, where I would match the 256 samples to 256 samples, then have an increasing radius being applied to subsequent searches if the next bit of my realtime input is “close enough” to the next bit of the chosen sample, then carry on playing it, and carrying on in this way, such that it would be kind of like mosaicking but prioritizing continuity over accuracy.
That’s also where I thought novelty might fit in, in that rather than using an increasingly permissive matching criteria as time progresses, I can use parallel novelty segmenting so that I keep playing the initially matched sample until a change in novelty is found in one or both of the processes (e.g. there’s a novelty slice in my incoming audio cuz I changed my playing and there’s also a novelty slice in the sample because it gets really loud all of the sudden).
So this second idea is more like “carry on until things go diverge greatly” vs “carry on matching, but increasingly sloppily” of the first idea.
Has anyone done anything like this?
Hello! I’m not certain I understand what you are trying to do, after re-reading a few times. The only thing that keeps popping to my mind is a sort of thing that I defined before, and I think what @hbrown is also doing, which is to bake in your descriptor a short term trend… so the first X are instant values and the next X are a time window of the ‘context’ and that helps train the system of what you expect it to do… is that what you refer to?
Well, there’s the aspect of analyzing/determining multiple time frames (which I still haven’t implemented in a meaningful way, as I’m scared/worried of slewing sudden changes in material, which I quite like), but what I’m mainly talking about is the playback side of things.
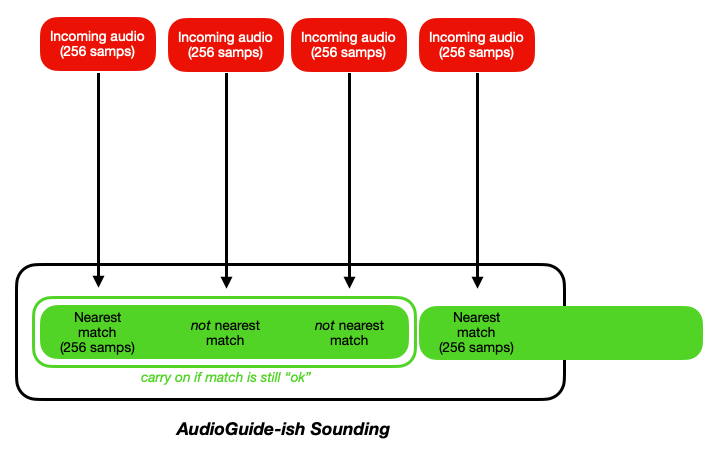
Here’s a quick diagram that hopefully explains things better.
Generic mosaicking is something like this:
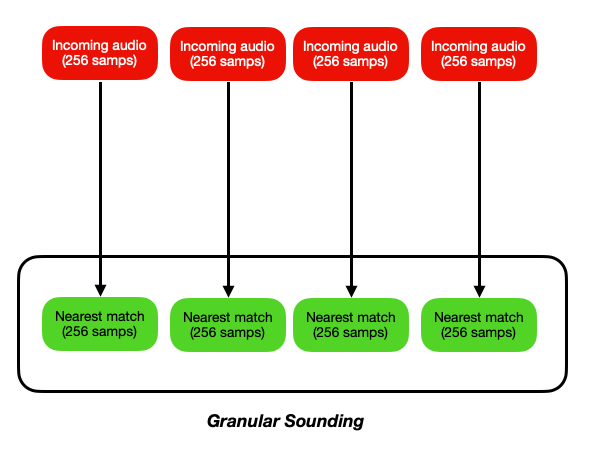
Where each grain is matching each grain, and you may use multiple time frames to determine what the nearest match is (ala @hbrown’s stuff).
But regardless of what you do, this will always sound “granular”, since it’s literally grains end-to-end.
What I’m thinking/proposing is something like this:
Where it still does a per-grain matching, but perhaps gets more permissive as it goes on, and still carries on playing the initial sound if it remotely like the (fresh) incoming analysis grains. What determines whether to carry on or not is to be determined (permissive window, novelty, multiple time scales, etc…), but the general idea would be to have playback that is not a stream of individual grains, but rather playing back as large of chunks as is possible (with an analysis windows worth of lag of course).
The hope is that this would allow for some mosaicking-type behavior, but with less of a granular sound, or at least less of a “stream of perfectly spaced grains” sound.
ok a good way to try that ‘quickly’ would be to check for a given number of nearest match distance and allow that to be larger as you go further… trying that first could be good I think. so let’s say your left most input is A (then B,C,D) and your leftmost output is 1 (then 2,3,4)
A matches 1, starts playing, checks the distance between A and 1 (lets call this π for fun)
B is measured to 2 (what follows 1) and if distance is smaller than (π + tolerance) keep on playing (in effect playing 2 but without the granular process)
C is measured to 3 (what follows 2) and if distance is smaller than (π + more tolerance) keep on playing
etc…
does that make sense? for now it might be slow but try it with kdtree as it gives you all the distances
1 Like
Yup, that sounds like the kind of thing.
I think I would start from being completely permissive and then dial it back from there, just to see how that fares.
How does threading work for this like that? Like changing the @radius for every query?
The playback side of things will be a little faffy as I guess I have to trigger the complete sample, then have the ability to interrupt it at any point (with a fade I guess), as well as keeping track of whatever sample finishes naturally while the re-matching process is taking place. Then there’s a question of potential overlap/polyphony, but that’s a whole other can of worms (particularly if I want to start incorporating the subtractive descriptor stuff in AudioGuide too…).
I don’t know, but for now you’re again optimising too early, my friend  I would guess that since it is just a condition on the ending (it changes nothing on the tree itself AFAIK) so you shouldn’t notice it.
I would guess that since it is just a condition on the ending (it changes nothing on the tree itself AFAIK) so you shouldn’t notice it.
Actually not that hard, use a simple poly~ with 2 voices and crossfade when you want to kill the current voice. for now you can just let play and hear both at the same time for fun and chorusing 
There isn’t any threading on these objects yet (besides the regular Max threads), so it makes no odds 
I find it helps to throw around technical jargon!