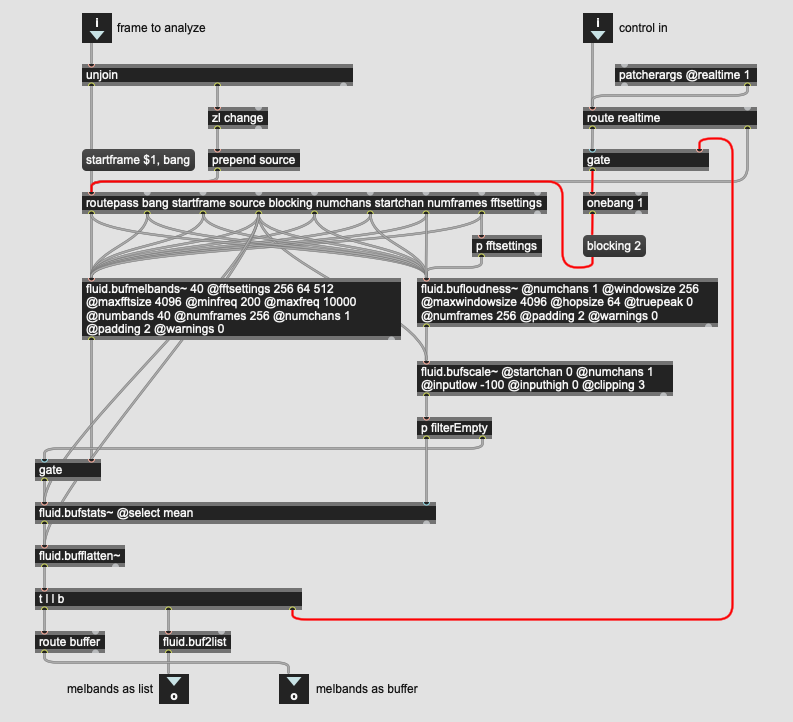
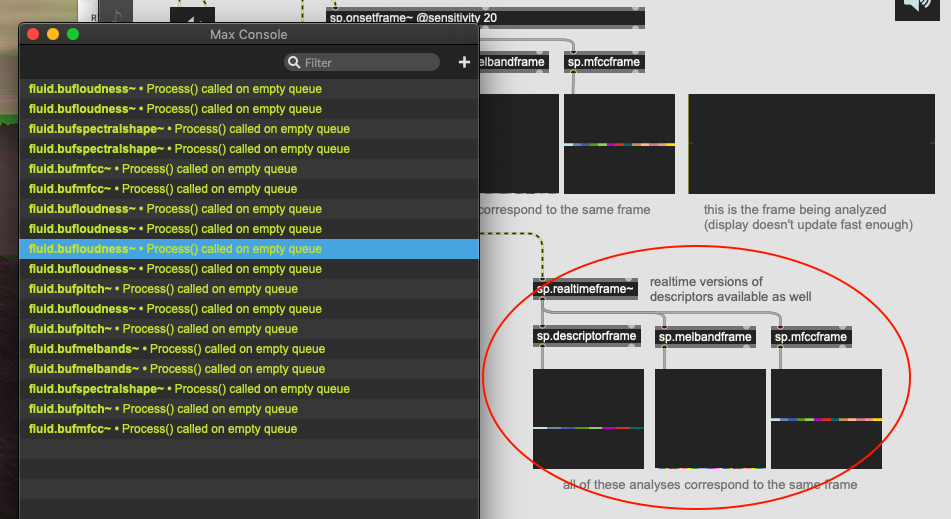
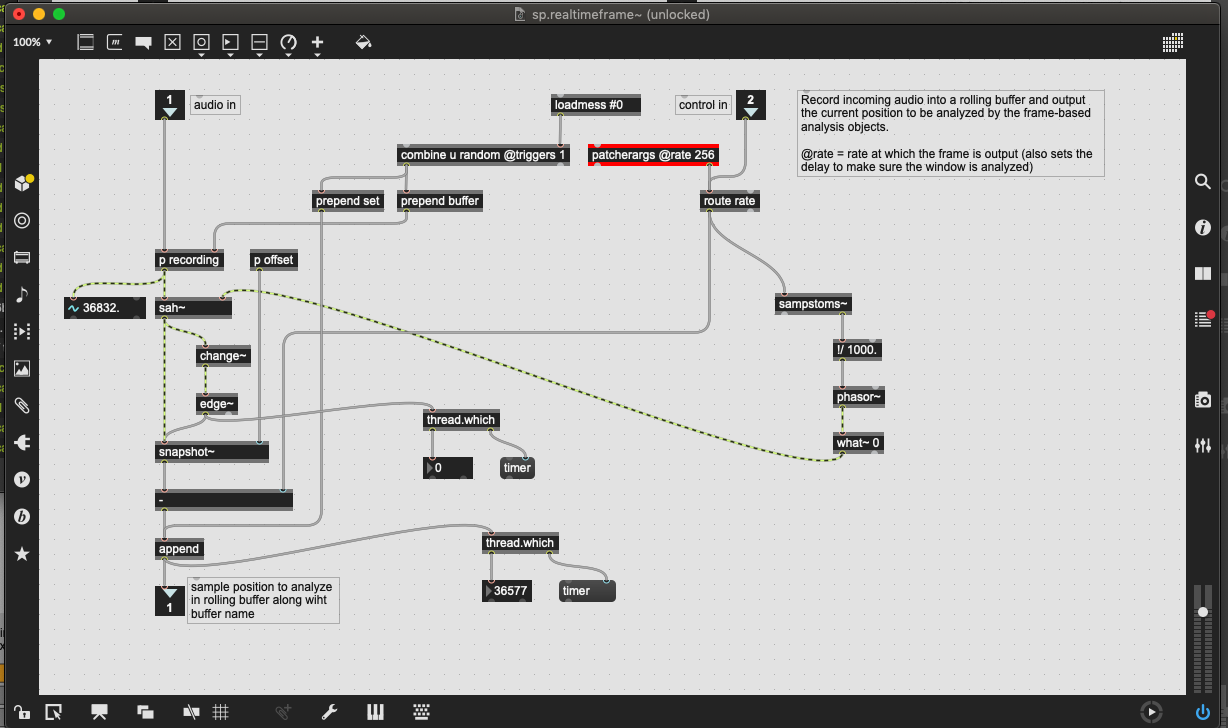
Not sure if this is a bug or not, but I’m getting a Process() called on empty queue (yellow) error message from my patches very rarely. It seems to be coming from descriptors objects fluid.bufspectralshape~/fluid.bufpitch~/etc…
I’ve set @warnings 0, but that doesn’t seem to curb anything.
Not sure if this matters or is relevant, but it only seems to happen in my overview patch which has loads of tabs and high CPU usage. I don’t see this error message in any of the individual help/abstractions.
It’s tons of bits from all the help files in a big/single patch. As I said, I don’t get these messages in any individual patch, and in the overview patch there seems to be no correlation with anything happening. The message just pops up randomly every now and again. I’m trying to delete bits to see if I can narrow it down, but it’s intermittent.
My bump was just speculation that it may have to do with CPU load since I only see it in that patch.
What would be helpful to know what Process() is, and what an empty queue is the context of the error message, as neither of those things are super indicative to what’s happening or creating the error.
If I double-click them, to do jump to their respective objects (fluid.bufpitch~, etc…), but again, without knowing what the error means, I don’t really know what could be causing it.
Oh, I don’t know if this is random/unrelated, but it seems to only send the error message when I “do something”. And by that I mean, change tabs in the patch, or switch to a different app (alt-tabbing).
If I have the patch open, with audio running and doing stuff, I don’t seem to get the error.
Is it possible that there’s some weird threading error/bug going on? (everything is @blocking 2 btw (well, more specifically everything starts off in default @blocking and then after processing a single frame (to populate/size buffers) it changes to @blocking 2))
Yes, likely to be Something To Do With Threads. The error message is one that oughtn’t really happen, hence its crypticness. When running in blocking 0, the object parameters get copied onto a queue for each bang (which calls a function process), and it shouldn’t be possible to get into a state where it does that call without first having enqueued something.
I’d need a closer look at how you do your triggering / blocking mode change to make a more informed comment (plus info about your overdrive / scheduler in audio interrupt settings). IAC, would suggest that if you’re doing an initial run in non-immediate mode to size buffers and then letting rip, starting in blocking 1 would possibly be a better idea.
Essentially everything starts in @blocking 0 then after initially creating/sizing buffers, it all gets banged into @blocking 2.
There’s a slight variation in one of the abstractions that also sends a autosize 0 to fluid.list2buf as well, to put that in “@blocking 2”. This one is a bit messier/bigger, but here’s a screenshot of that, again with the relevant bit highlighted:
This gives me a tiny bit of latency for the first hit, but it’s not really a big deal and it saves having to name/manage 10000 buffers.
I’m running with overdrive on and interrupt off (my standard setup).
Hmm, this is the first I hear of this. I’ll give this a quick try now and see if that changes anything, though it’s hard to assess since it’s intermittent.
Is it just better/safer to have @blocking 1 as a precursor to getting re-banged with @blocking 2 or is it just best practice in general?
Ok, cheers. I can sort of see how there’s potential for thread related surprises here. If both inlets are being fed from the scheduler thread, and the flucoma objects are in non-immediate mode then there’s an implcit defer on the bang that triggers the processing and thus on the bang that eventually opens the gate, but not on the change to blocking 2.
I’m positive that it’s not because you were literally in the room when a bunch of us hacked through hopes and desires for how threading options would work, albeit (a) some years ago and (b) it was a protracted, technical and perhaps even quite boring conversation
Personally I don’t think defaulting to non-blocking (i.e. using worker threads) was the best idea, because it adds conceptual complexity. As a rule of thumb, I’d say that blocking 0 is primarily (only?) useful for doing heavy processes on moderately large chunks of data (stuff like NMF, Sines, Transients, where moderately large is a admittedly variable concept).
For your MO of working on pretty small slices with temporal consistency in mind (which is what blocking 2 is meant to help with), then the overhead of making and launching a new thread in blocking 0 isn’t doing anything useful, and is introducing a new layer of asynchrony to reason about (which is hard). Also, it will introduce new overhead from moving data between threads, which will make this first run more sloppy than it needs to be. So, yes, for this purpose, I would recommend blocking 1 as the starting point: this will defer, but at least successive flucoma call will be on the same thread. I would also consider deferring the call to blocking 2.
Hehe, I vaguely remember the “grown ups” having a heavy/technical discussion, but I didn’t file away “always start in @blocking 1” like I did the “always use @blocking 2” thing.
Yeah, good to know. And with that being said, I do see how it makes more sense to have @blocking 1 be the default, but I guess that ship has sailed at this point with existing patches/code/time/etc…
On initial test, this appears to be working fine. I’m alt-tabbing between apps like a maniac and Max is none the wiser!
Hmm, it seems that with an initial @blocking 1 and defer’d @blocking 2, I still sometimes get the error message.
It seems to happen now in circumstances where I don’t do the loop to @blocking 2, but instead it stays in @blocking 1 the whole time. (I do this for longer/non-realtime analysis bits like creating a corpus).
Could be unrelated, but just had a crash while playing in the patch that was throwing up the error. I can’t parse much of the crash report, but I did see NRTThreadingAdaptor mentioned a couple times.
I’ve also narrowed down the problem to some “realtime” analysis I’m doing, but I can’t see what’s different since the core abstraction is literally the same.
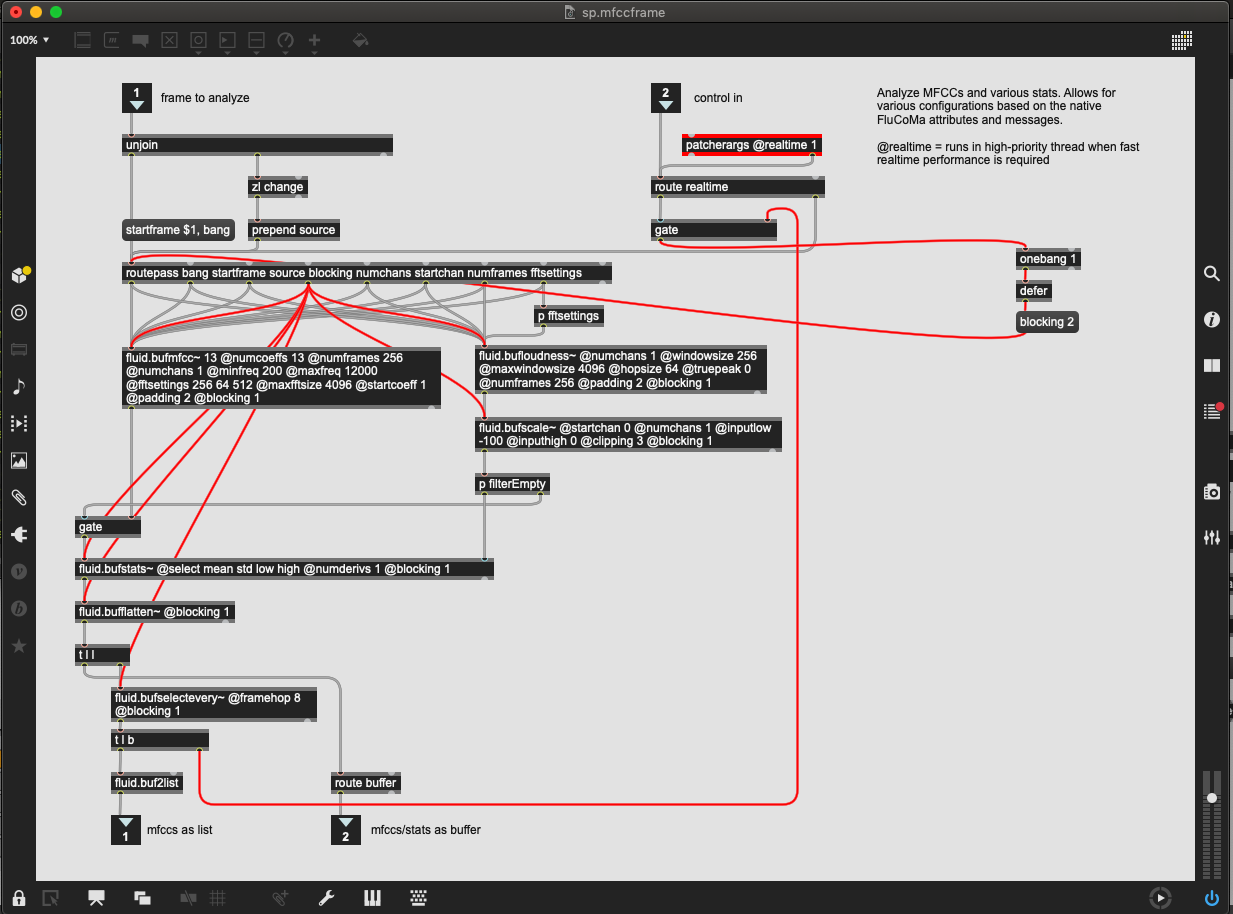
The sp.xxxframe abstractions are literally the same as I posted above, which have since been updated to be @blocking 1 by default, and changing to @blocking 2 with a defer, like so:
I tried switching the phasor~ to a vanilla metro, but that literally crashes Max (and I think is what lead to the fluid.bufpitch~ crash above).
Should the first “tick” of this phasor/clock be defer’d to feed into the @blocking 1 downstream and then switch back to the high-priority thread or is there some other leaky thread stuff going on here?
edit: this defer the first phasor tick thing makes no difference.
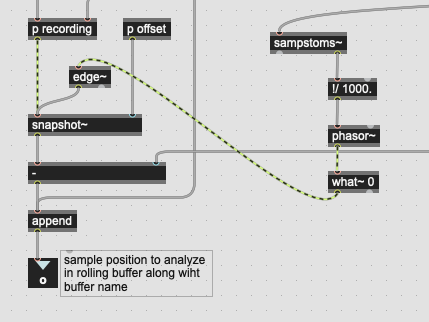
I’ve since streamlined this to just having the position go directly into snapshot~ rather than the (redundant) sah~ → snapshot~, but still get the scheduling error messages.