So some of the things that I’ve wanted to do, which has been tricky.
concatenating datasets and labelsets
be able to split/iterate datasets by labelsets
be able to split/iterate labelsets by datasets
(being able to use labelsets in datasetquery)
datasetquery is quite terse, but perhaps beyond the scope of this thread
I want to say there’s more that I’ve run into over the years, but this is what comes to mind right away.
I do remember wanting to edit datasets in-place (destructively), though that was in the context of wanting to filter out queries dynamically (per query), which would still end up jamming up on needing to re-fit for every query anyways, so that desire is bigger than just wanting to edit in-place.
Maybe, maybe not, insofar as it could form a low-level building block of useful abstractions.
In the case where the IDs aren’t meaningful, this wouldn’t be too hard – just generate new IDs (although the lack of ordering presents some trouble if you ever want to know which data point is which after the fact). Where the IDs are meaningful, then one needs a policy for what to do about clashes. If you’re concatenating both data and labels, you probably want a way of doing it at the same time, to preserve association between data and label.
I read the first as 'get me the dataset with everything for label X. I’m vaguer on the second: give me all the label / ID pairs where the ID is in the dataset?
A generic cheat for this, which could be a useful low-level helper, is to be able to convert a labelset to a 1D dataset with 0…n-1 mapped to the labels (and back again, given the mapping of index to labels). I guess the usefulness of being able to use labels in DSQ beyond just filtering a dataset by label is in being able to use conditions to build up some more complex stuff.
What I’ll probably do, as bandwidth allows, is make a little repo to start trying out and sharing abstractions for some of this and we can see what we like.
Would be useful to find out what the equivalent pain points are for the SC and PD users too. I expect them to be similar but not identical (due to the lack of dicts in PD, and the mediation of the server in SC).
Yeah I suppose that’s true. I do remember back to early bufcompose which, far less complex, had a similar “utility” role at the start, and had quite awkward syntax, which was then made a lot more generally useful, without sacrificing depth/power.
I guess the underlying SQL(?) syntax is plug-and-play, and if you are familiar with it, can do a bunch. It’s just not a very user-space-y kind of syntax. (I’ve never once used fluid.datasetquery~ without having the helpfile intensely open for like 15-20min)
Either way, I’m all down for wrappers though!
Yeah that’s the idea. Given the use case of outlier rejection, say I have a dataset/labelset that has a bunch of classes in there. I’d want to be able to break apart each dataset, remove outliers from it and the corresponding labelset, then put them all back together again to feed into the classifier.
In this case there shouldn’t be any ID clashes as they have all originated from the same original space, but perhaps some kind of merge/override-type thing that mirrors whatever dict and others do would suffice there?
That being said, I have used this a bunch where I have completely independent datasets which I want to concatenate (with new IDs), in which case new IDs are just generated that line up with however many entries are needed. I want to say the old abstraction you posted on here years back (that I still have buried somewhere in a few patches) does something along the lines of that.
I can’t think of a meaningful use case there, but was mainly thinking of filtering out labels based on IDs(?) from a dataset. Though the IDs would likely be the same if created at the same time.
I guess I just wanted to avoid having something where its easy enough to do a process in one direction, but not the other (kind of like datasetquery and labelsets).
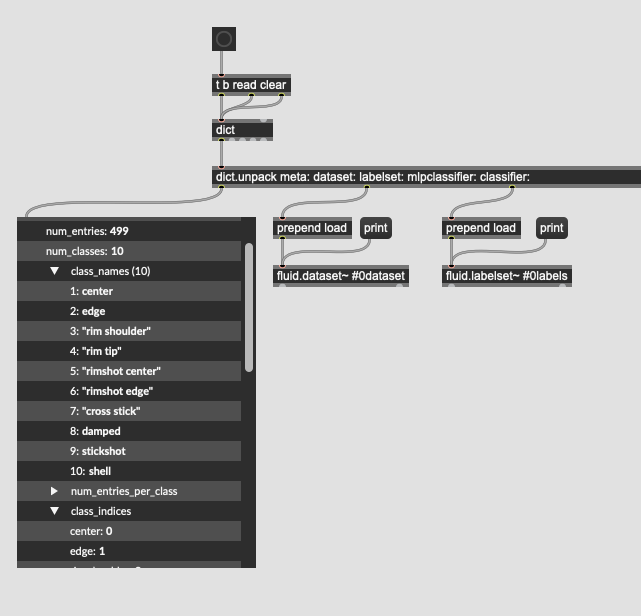
Indeed. A semi-workaround I’ve done for a different problem is to create an integer index for each label such that I can address the class by a symbol (label) or int (index) interchangeably. In the files I sent you if you look at the left-most dict you can see the thing:
I guess this would require keeping a separate LUT, but it would be pretty small all things considered, and if it’s an abstraction, it wouldn’t matter one way or another.
Now what that would mean in terms of formulating a query, I guess being able to use symbols in the search string, then the abstraction would internally parse the index versions and go from there. (e.g. filter 0 == "cross stick")
I’ll be glad to pull some weight on the SC side of things. Once there’s a consensus of what the functions are I could whip something up.
I think the SC side of things is simpler because our dict interface is so much saner.
FWIW, perhaps related… when making this I found that loading massive dicts from the server to the language is much slower than writing them to disk from the server, then loading them back to the language as a string and doing some parsing…
I can well believe that disk becomes quicker than UDP after not-much-data. Yes, having things like select and reject on hand in sclang makes doing some of this stuff language side much simpler.