Hey all, sorry for the little radio silence!
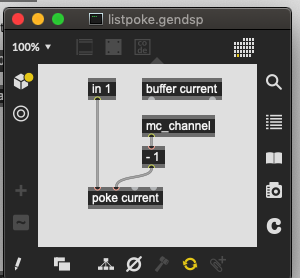
@tremblap: yes, sorry, the bl.gest.record~ abstraction uses mc. The mc.sig~ -> mc.gen~ listpoke is just my way to put the incoming list into a buffer. You can try a workaround with fluid.list2buf or making a poly~ with the sig~ -> gen~ – although in that case a simple poke~ will be enough.
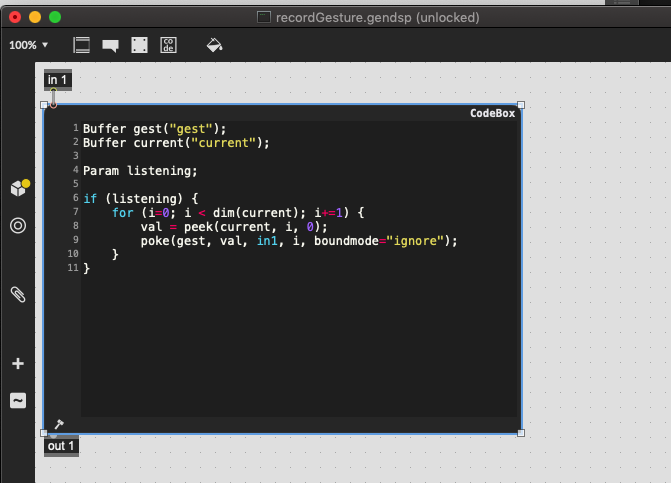
The other mc.gen recordGesture basically pokes each sample in the buffer we just poked the incoming list into into different channels of the same index in the buffer we store the full recording at. (So it’s kind of the inverse of fluid.bufflatten~ and then storing that multichannel sample in the recording.)
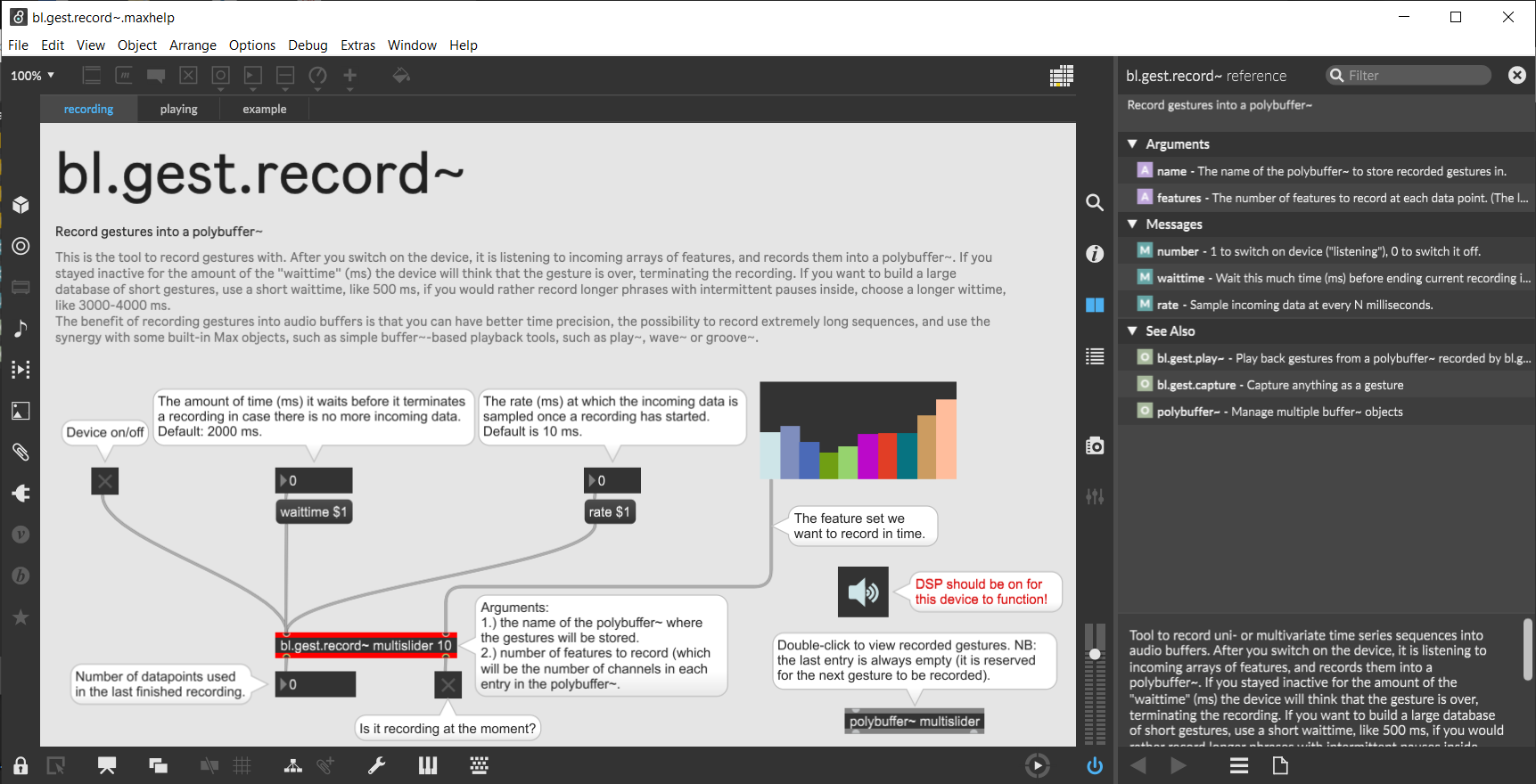
But generally bl.gest.record~ is more intended to have a convenience device that just continuously listens to your input, and if there is any new data, it records that into a new slot in a polybuffer~. The waittime parameter defines after how much idle will it decide to finish (and crop) the current recording. So the idea is that you just keep on doing stuff, and it will record your “gestures” when you do something, and then you can have all your recordings at one place (the polybuffer~).
It is not overly tested though, I only needed it for one project, so I hope you won’t get bugs… (I already fixed some before I posted the example project, haha…)
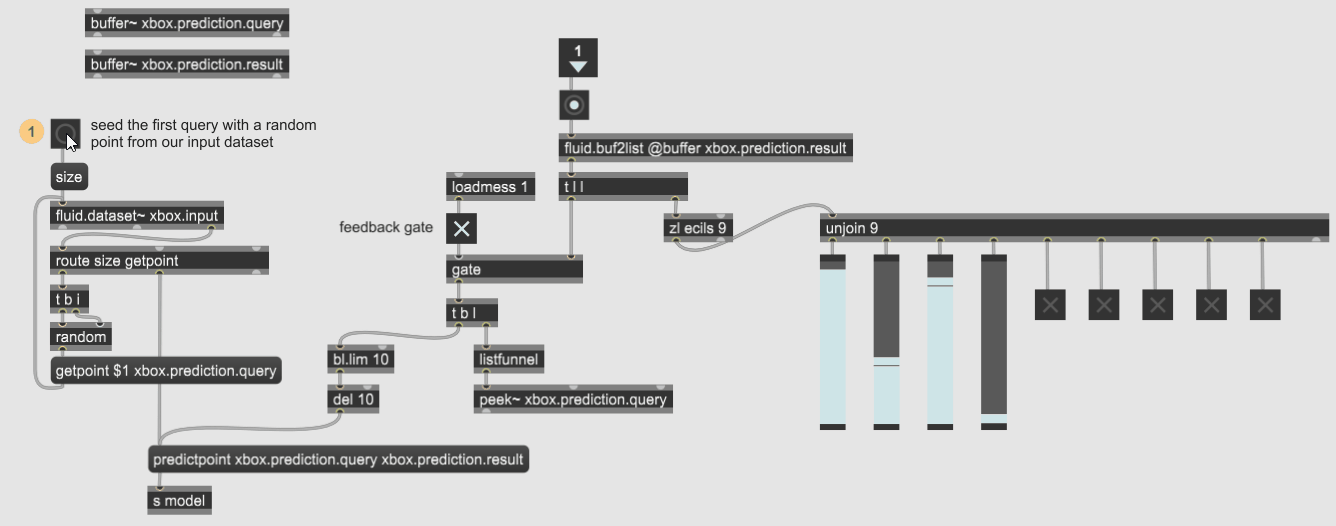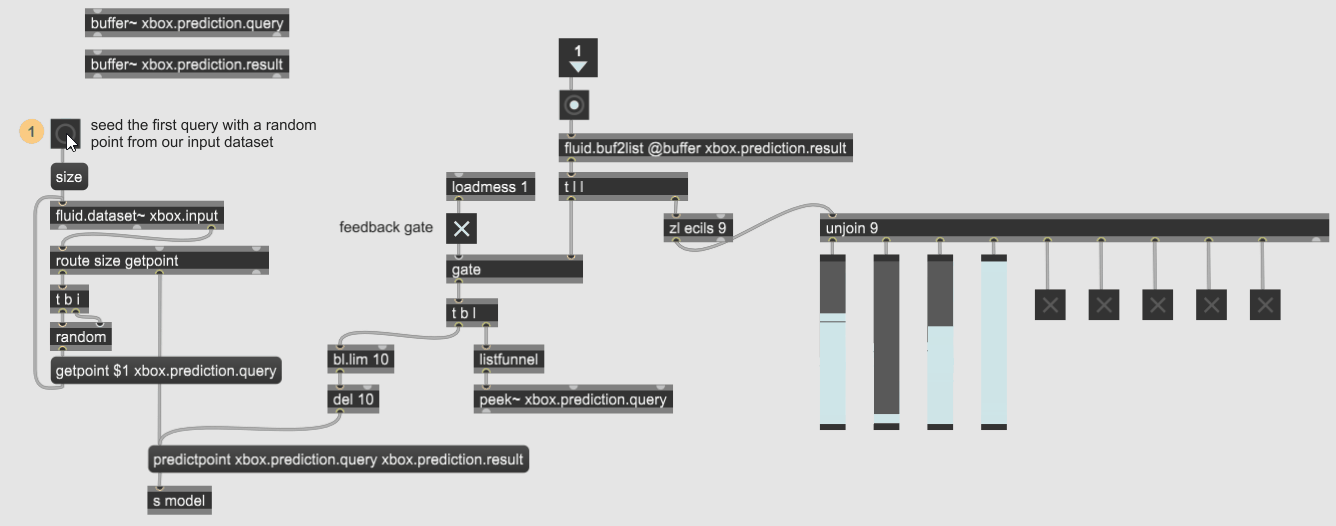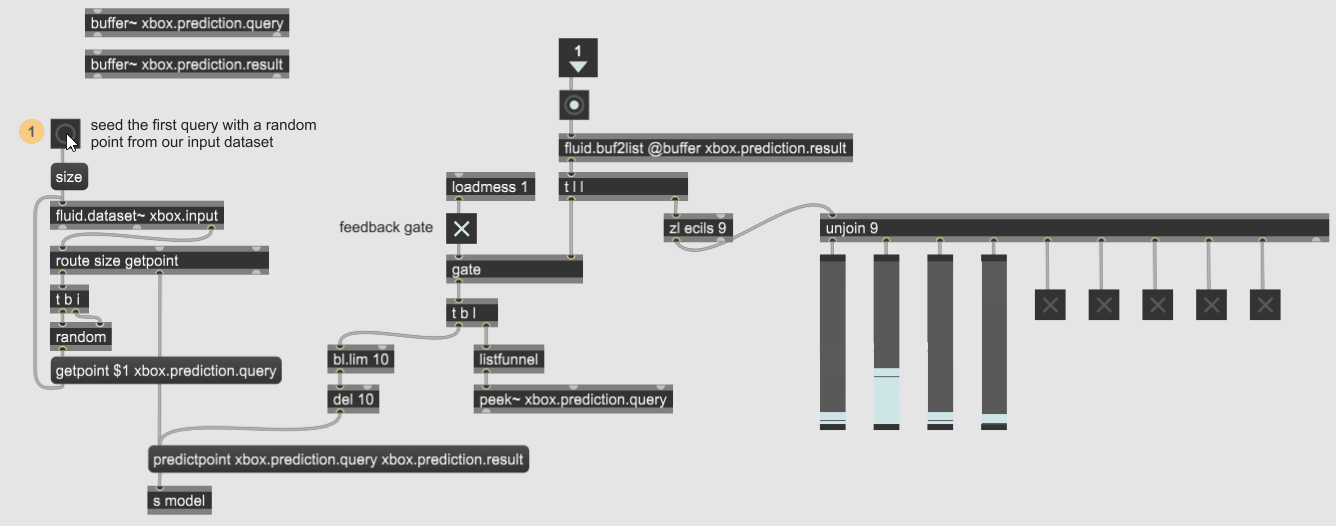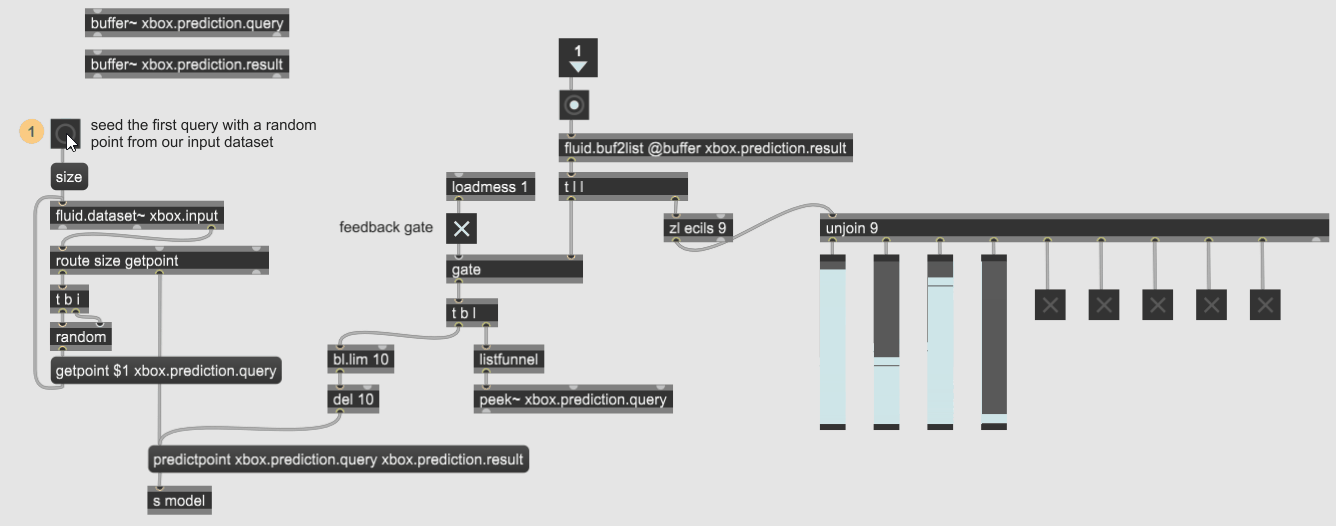
Here is a screenshot of the help patch if it helps:
As for the training problems, @rodrigo.constanzo would you mind posting a file with your recorded data in some form? It is easier for me to see what the problem is if I try it myself.
A small user feedback from me: I think it would be cool to also be able to address activation functions with symbols, like @activation relu. It’s not a big deal, just thought it could be clearer/more comfortable to some.
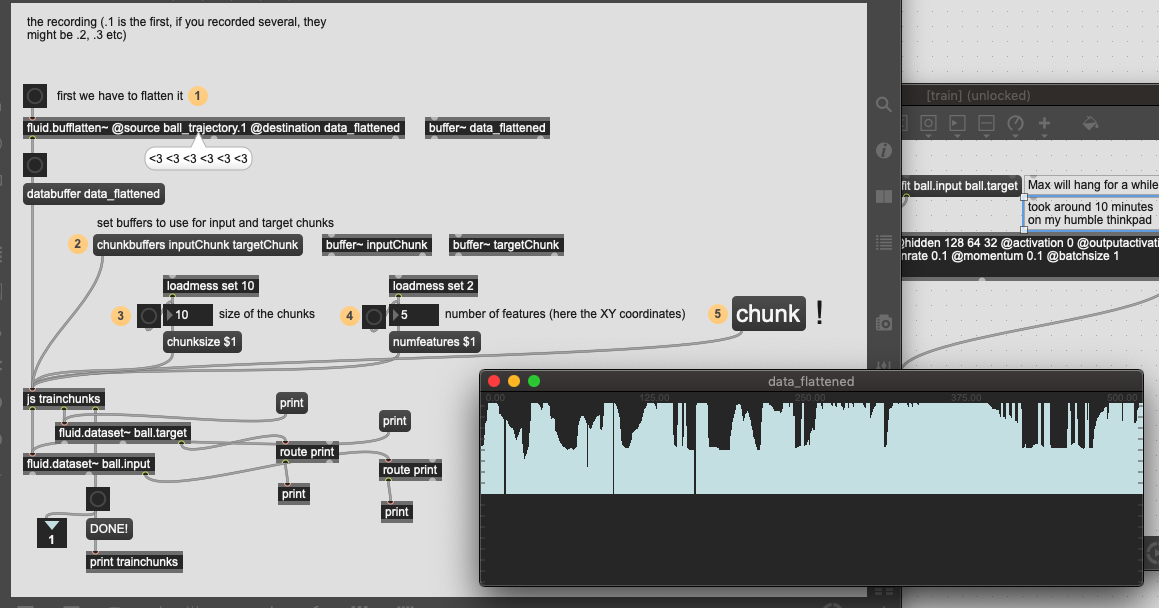
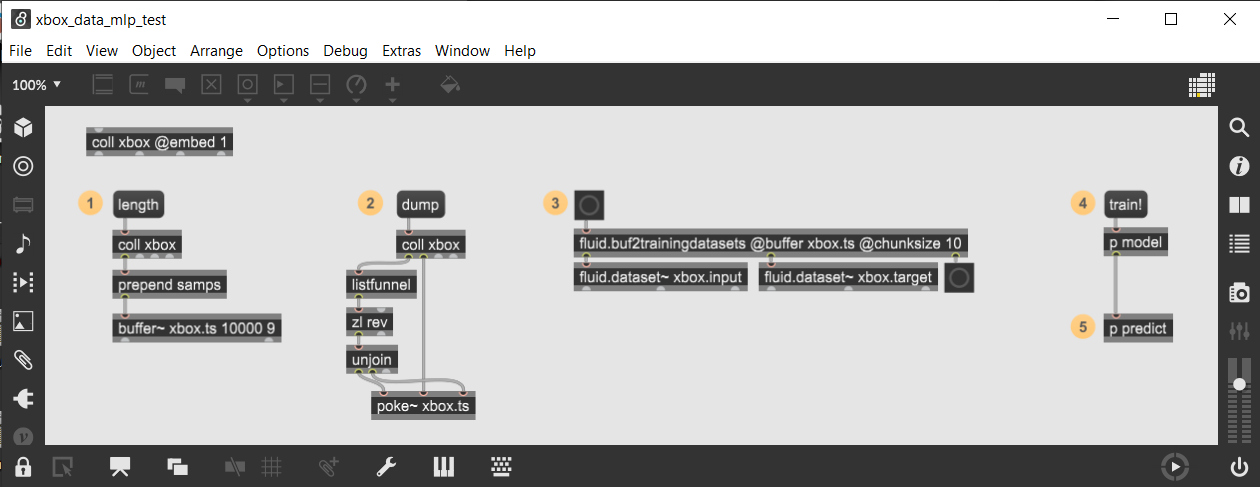
And @rodrigo.constanzo, you might wanna try to swap the chunking part of the patch with this, which is more streamlined, + doesn’t produce unnecessary trailing-zero-entries in the datasets.
This whole conversation also made me think of implementing a similar, but LSTM pipeline in tensorflow.js, so it can be hosted in a node.script (and in an abstraction ultimately). I generally don’t trust Node inside Max, but maybe they have fixed the performance issues since I used it last time. Then we could cross-compare the timeseries predictions of fluid.mlpregressor~and a stack of LSTM nets. No promises about the when though, but hopefully soon!
 Maybe the reference could be clearer about this (it does not mention “identity” + lists them in the wrong order – assuming that some user like me implies the order from the description).
Maybe the reference could be clearer about this (it does not mention “identity” + lists them in the wrong order – assuming that some user like me implies the order from the description).