Something I’ve been thinking about for years now, but haven’t had the knowledge (or tools) to do something about, has been using some kind of machine learning to model/predict controller/gestural data.
To give a more concrete example, I want to be able to take some gamepad controller data (with both analog/continuous and button/discrete inputs), and feed that into an algorithm in a time series, and then ask for “more” of that to be generated.
Generally speaking, I was imagining this wrapped into a “time scrubbing” metaphor where I can be recording gestural data into a buffer~, and rewind/play it back sampler/looper-style, but then being able to scrub into the “the future” by transparently switching over to some algorithmic/predictive versions that would follow on from that training data.
From where my knowledge is now, this seems like regression. Where, rather than filling in the gaps of continuous (and/or discrete?) values, I would be filling in a “future gap”.
Am I in the right ballpark there?
Where this gets really confusing for me is, what that would mean in terms of code.
In having a simple think about this I pictured having some kind of regressor (say fluid.mlpregressor~) and giving it an input which is just a clock signal. Either from a count~ or cpuclock or whatever, while at the same time generating the kind of controller data that I’m after.
So to use a simple example, at time0, my x/y controller would be bottom left, at time50 my x/y controller would be in the center, and at time100 my x/y controller would be at top right.
Where this starts to seem a bit crazy is that, particularly if I want some good resolution, I will easily have thousands if not tens of thousands points I’d be training (say 1 point per ms).
So that seems a bit crazy in that that’s a huge amount of data to set up and train on (or maybe not? don’t know).
The other thing is that the structure of that seems weird to me. Like, having a multidimensional controller stream, but only feeding a time series as an input. So basically creating a 1->15 network (or something similar).
Lastly, is the idea that if I have something trained like this, I can then feed it a control stream that consists only of a time value, and it would recreate/predict what I wanted? And quite importantly, if I send in a time series that’s greater (or smaller) than what the input of the regressor was trained on.
Am I on the right track?
Would a NN or some other regressor type be well suited to this?
Will it be able to handle ms/fast inputs as well as querying?

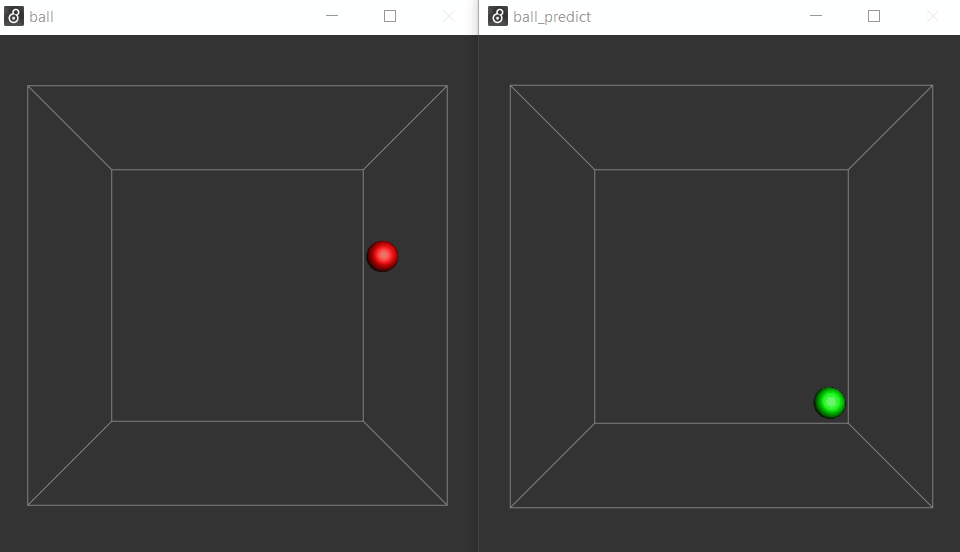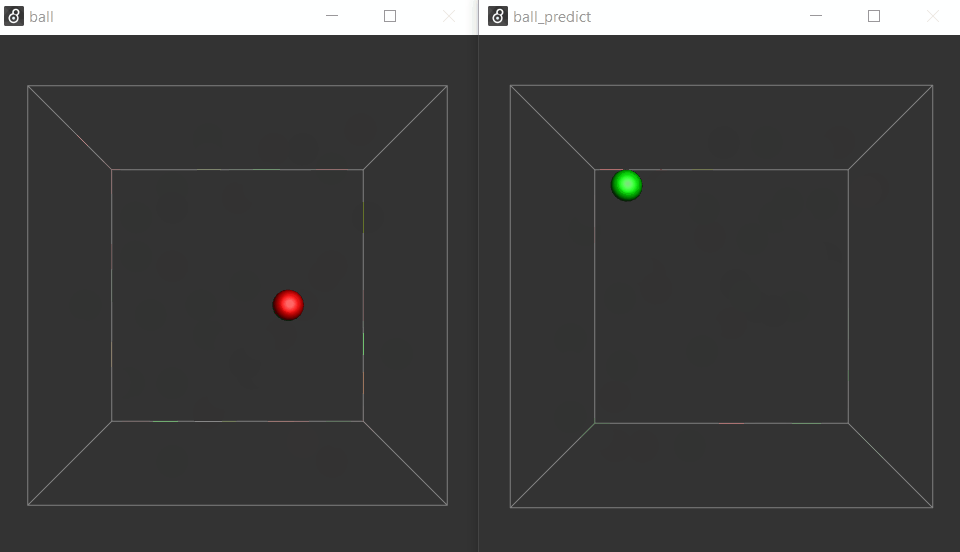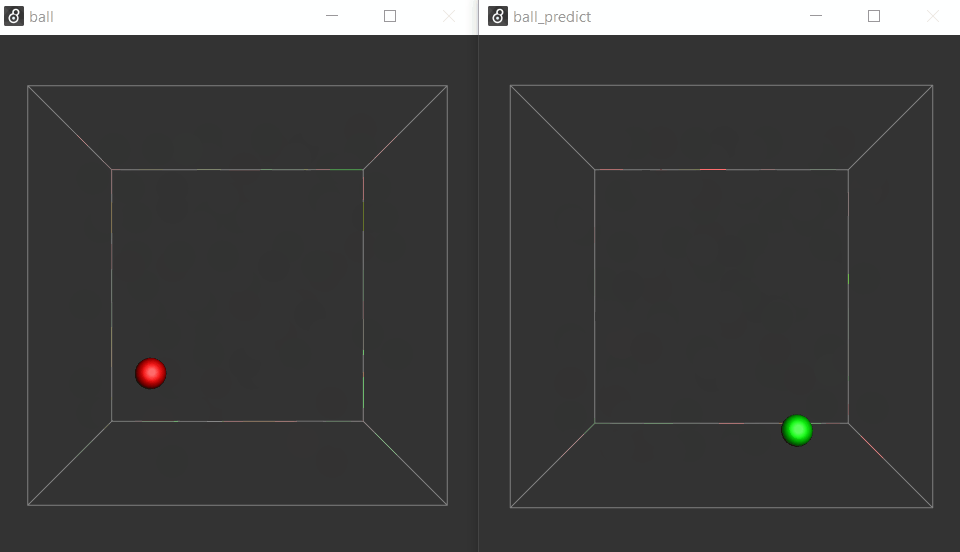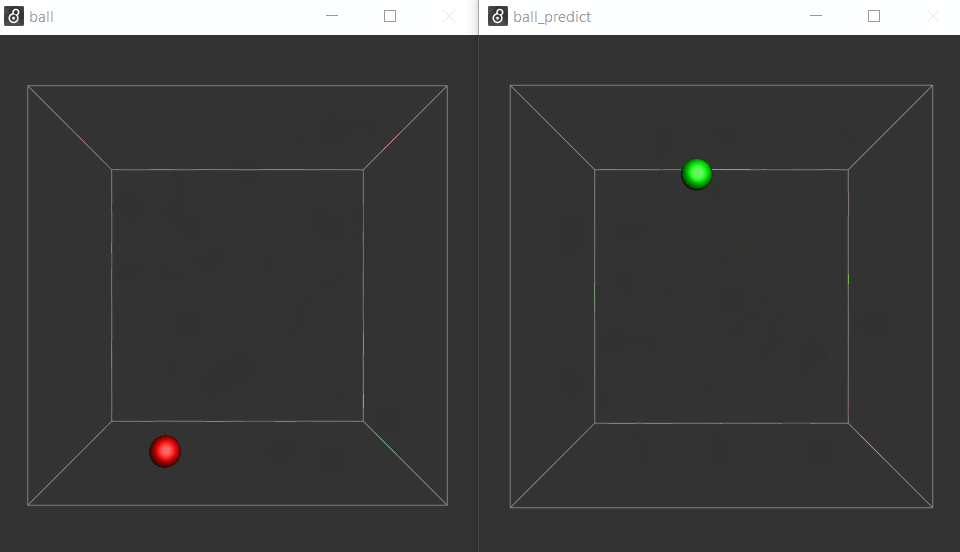

 (in case you want to break the loop with a [gate]).
(in case you want to break the loop with a [gate]).