Hello,
I’m interested in doing something similar to the tutorial here:
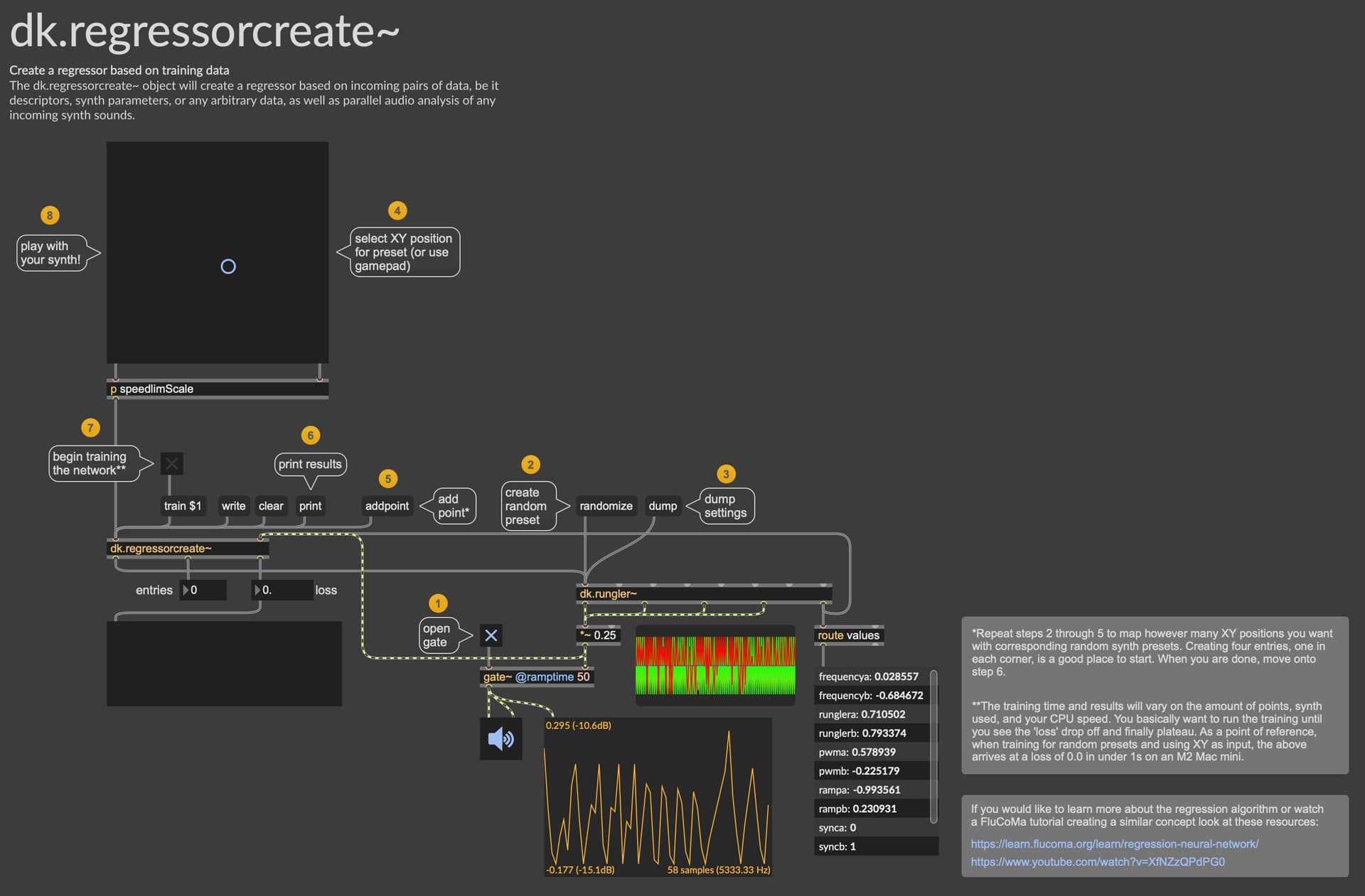
https://learn.flucoma.org/learn/regression-neural-network/
But with the addition of incorporating elements of reinforcement learning, where the user can push the model to different parts of the parameter space in response to their feedback (ex. “I like this” or "I don’t).
As far as I can tell from the documentation, there’s no built-in support for this, but does anyone have any ideas for starting places to look into doing so? I’ve explored using both the MLPClassifier and Regression models, but I’m not sure if they’re quite as customizable as if I were doing this in, say, PyTorch.
I usually like to use SuperCollider, if that helps.
Thanks!
1 Like
Hi @anteater ,
When in the process do you want to specify if you like something or not? The way the tutorial is designed, the user does specify what sounds they want to use (and therefore not using sounds they don’t like). Maybe you can describe the envisioned process a bit more and we can think about it!?
T
What I’m imagining is something like:
- (in beginning, neural network is untrained, and parameter space is random), user makes some sound with their instrument as input, and sound is outputted
- user indicates if they liked or didn’t like this particular mapping
- This decision pushes the parameter space in that direction and the network is trained in this direction.
I suppose what I’m trying to eliminate is the user actually having to adjust the various parameters themselves. As in, rather than like in the tutorial where the user adjusts the 10 sliders, and adds this point to the training set if they like it, the model itself is doing the adjusting/pushing the parameters in that direction on its own. This is (to my knowledge, although I’m certainly no expert), very doable in various reinforcement leaning paradigms with something like PyTorch, but I’m not as sure here.
In short, I’m trying to eliminate the user exploring the parameters themselves, if that makes sense. Thanks!
Sounds interesting. Maybe the synth parameters are being modulated randomly or jumping to randomized settings and the user indicates when one of the settings is desirable. Then with that knowledge the model can train to create a space from those settings.
Kind of reminds me of some of this: https://www.youtube.com/watch?v=jMZP_UF8gg0
Does that sound like it’s getting at what you’re thinking?
t
1 Like
Yes, that is a similar workflow in terms of having the user explore complex spaces, find sounds they like, and train to reduce dimmensionality and map, say, input sounds directly to those sounds. The only difference I can see between these two is that I’m looking to ideally remove the “playing with sliders” part and have the model slowly hone in on different spaces on its on. Moving to random settings is a great idea, and I will try that.
The one downside is in the approach you suggest the “negative” feedback isn’t directly effecting the training of the model. Another way I was thinking was to perhaps consider it a classification rather than a regression problem , where class 0 is “good” and class 1 is “bad”.
Is it possible to get the final layer of outputs from the MLPClassifier or anything else before the classification head? If so, I would be interested in trying to use those activations as pure controls for say, effects or synthesizer controls.
Thanks for all the help!
At some point there will need to be some data collected from which the model can learn the user’s preferences. Doesn’t need to include the user moving sliders, but some process of labeling is inevitable. Figuring out how to make that efficient and easy and valuable is a good pursuit!
That’s just the MLPRegressor ! Same MLP under the hood, just the last part is different. You can train the MLPRegressor like the classifier by using one-hot-encoding.
1 Like
Not directly related, but something I’ve been working on for a package I’m developing is to have each synthesis algorithm include its own definitions for parameter names, amount, ranges, and (variable) randomization:
Such that the regressor is trained off of “dump” from the synth which includes the relevant parameters. That way you can just send randomize or (randomize 10 to randomize with only 10% strength from the current state) and then add points without needing to worry about packing lists, scaling parameters, etc…
It still requires intervention of the user to do this loop adding, whereas having it dump things out at you and you can “swipe right” or “swipe left” to build up the regressor could be a cool way to do it.
I don’t know that I, personally, would trust that kind of spur-of-the-moment decision making but it would ease having to generate the individual points one by one.
Where I typically find more friction is generating the controller-side of things, especially if it’s a multi-dimensional (e.g. motion controller) thing as I’d want to have all the synth presets done at once, then go back and separately assign corresponding controller positions for each.
3 Likes