Been a while since I do a straight sharing example but here’s something I’ve been working on.
spectral envelope.zip (4.0 MB)
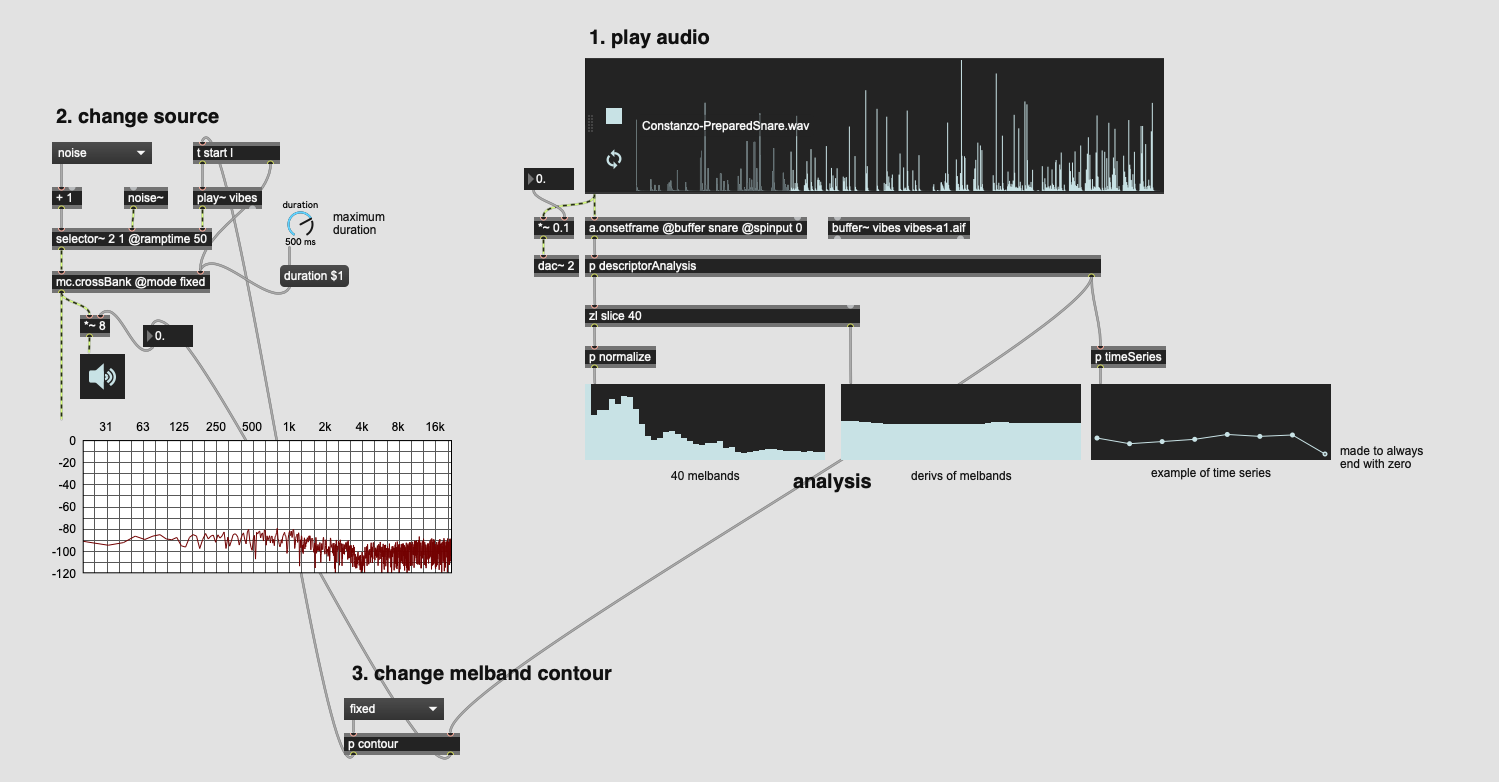
The idea is to take the approach outlined in the spectral compensation thread (where you apply the spectral contour (via melband+cross~) to sample playback) but extend it to have a temporal component.
For a bit I was playing with a bank of cross~s such that I could do pseudo-LPG or even pseudo-HPG by changing the ramp time for the gain of each individual cross~ output. My thinking was that I could use clustering to define oldschool “mute groups” where one sample from a (clustered) “group” would be muted by the subsequent sample, but instead of just killing the audio immediately ala @steal 1, it would instead apply a dynamic contour to the fadeout to create a more “natural” / “organic” sound.
In my tested this sounds pretty good, but it’s a bit tricky to encapsulate everything properly so it behaves that way.
I also wanted to take the spectral compensation a bit further by using the melband analysis to apply a time-variant (cross~) filter to a corpus-based sampler. The problem was, like it always was for me, that I didn’t really have many frames of analysis to work with in the first place. 256 samples with a hop of 64 (7 frames) is all I have to work with.
Rather than mapping out the contour of each individual melband over that time series and then stretching it out (via something like DTW(?)), I decided to do something a bit simpler/dumber by just using the derivative of the mean for each melband, and then scaling that as a relative duration for that specific band.
My thinking is if a band has a negative derivative, it means (?!) that that melband’s gain is decreasing over the course of the analysis. Similarly if the derivative is positive, it would do the same.
So this patch does that. It takes an analysis window and gets the mean and derivative of mean for 40 melbands and uses it to set the initial gain for each band, and a unique decay time for each band.
It sounds pretty good so far, even just on noise/vibes like in the example above.
In a proper patch it would also do the compensation/correction for the source vs input too, but one step at a time.
I think I’ll also try just taking the time series for each melband and converting that to direct gain stages (making sure it always fades out, for my purposes).
But for now, I wanted to share the WIP.