As before, posting this here as I don’t know if this is a meatspace error or an algorithm error, but when working on an update to SP-Tools that will play nice with arbitrary sample rates, I’ve run into a weird issue where some descriptors report radically different values at different sample rates.
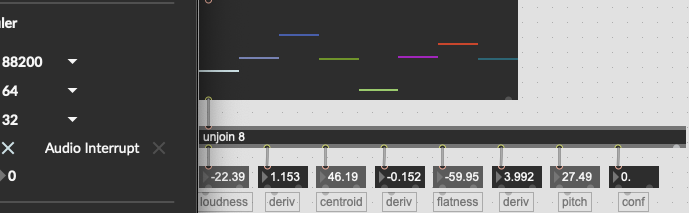
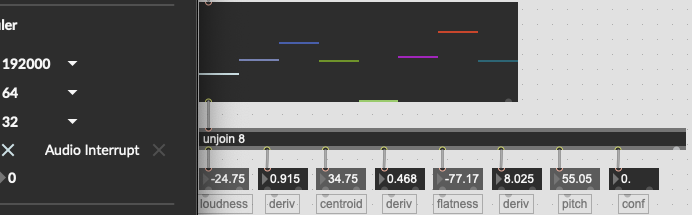
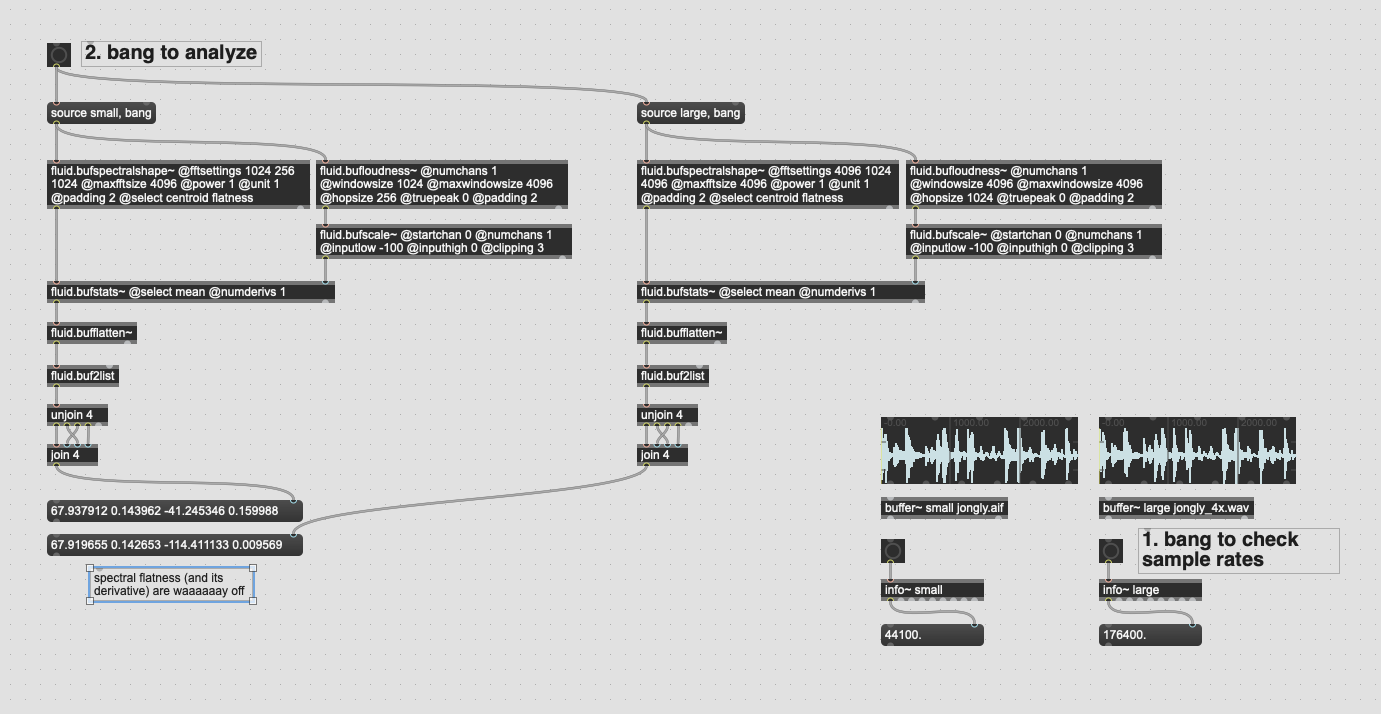
In order to test things I’ve resampled jonly.aif to 176.4k such that I should be able to run the respective analysis with 4x the @fftsize and @window / @hop size and expect (largely) the same results.
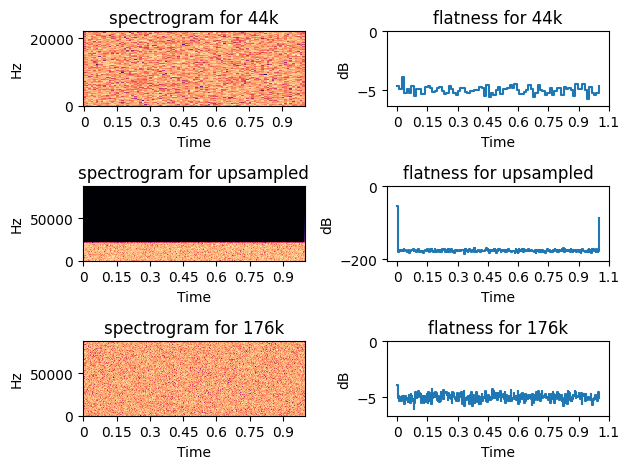
This is more-or-less the case for most of the descriptors, but spectral flatness in particular, is massively off.
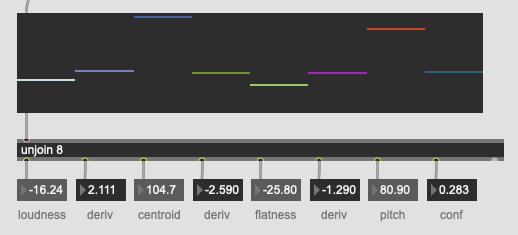
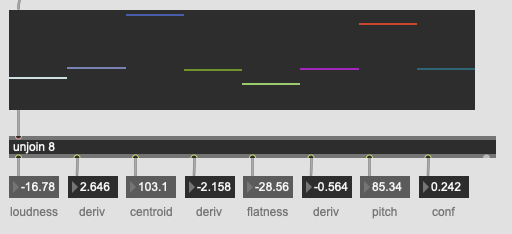
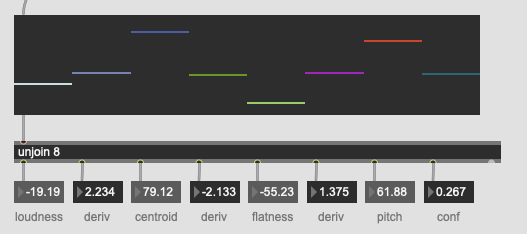
For jongly.aif @ 44.1k / @fftsettings 1024 256 1024 I get the following as centroid, derivative of centroid, flatness, and derivative of flatness:
67.937912 0.143962 -41.245346 0.159988
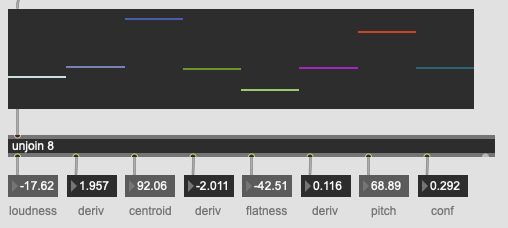
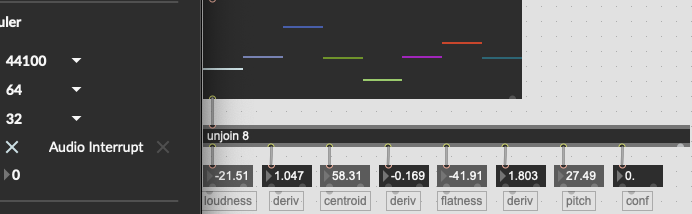
For jongly.aif @ 176.4k / @fftsettings 4096 1024 4096 I get:
67.919655 0.142653 -114.411133 0.009569
The centroid isn’t exactly the same, but I can chock that up to less than optimal upsampling (I used Audacity in a pinch), but the flatness is ballparks off, as its derivative.
Here’s an example patch: (along with the 4x jongly)
----------begin_max5_patcher----------
1696.3oc2a0sahqCD9Z5SgEWcNRcirG+ShOW0KOuCGspxELsoaHIJITZ2Uae
1O1NAJsM.NKNzcKR7SLlLd9luY7LSB+3hISuo3Qc8Tz+f9OzjI+3hISbCYGX
R2wSltT83rLUsaZSWpqqU2pmdY620nerwM9C5p5zh7MimN2MZwM2+EAayf4q
VllmoabmI3kAKV0rYTR2nkplY2kle60U5YMsquDFKBeIhJ412Xw1WAHBi9Z2
uo8zz7Tot8GLcJ5q1u4mWbg8kK8TCmUrboNu4cZXcoYoToxPKxTM4FX.8Wp7
4nzlZzbcU5CplzGz+MRUoQqUtGOgJVrXy4IKMWOqXUdytJ+tvDzKLQ5Elv6G
lHfCeDDo8Mhf5.MpEmBHXPhP2nxuE0Tflcmd12P0pkkYZTkpwvm7UkwGTkWT
j2Tm9cm0DvQ3ChD1ImqV5l7z+Um8ftIclZ5AvIRrCZ3wNfBvfiVI1gPYOmKT
ybmSR.AO3EvSkqxd565dba3IenfivhFRGlPRHNDJjPyMqZZ5MZAW7xxpxrja
zUWqyU2jo2Ug7vE4PQRLpUL.RB.bBkKgDip5Bt.aec+QUrltesHK6K1oHNRR
jBNGgiHLPvonuPHrHFgPnTyfXrjKj8gVz.EasGDgm3Bj.bdjbmGIIhwItatd
sQkdG3beQZNh0ity38p6rgp6h3dTdlgOHkXZh.hAljCLpAQvQ7yptuJe+ZuX
.aWvGp1ar4.OVHoBNiBIRJX2Qwicbu7MOCIZrHaU57naVsvtAbiN+49fk3A.
Kv.gEpYGCPBTbBiDKkBJwD2.6IpLJHAjkV2zGLjDl3B8yNH7HNvwXBlJHBP.
FbHFNNN3VriBNT2nZpeFcUsNyr1QK0pbzUFszkXVMhzGDIG.DMXlB0LHWJHl
rKjIfMtoAbRhiRRRjxXKCxffV9yGEyYS1r02oJ0FjawhlZinM5VMhgkBDACr
1Ock4Da+ZS1FcCTVrVWgHnqVkm1XeuTMet4mhfslfYlDepJRmuMa4dSJj1yV
Z3QzCFHjHBjXPeJDSDFiPrMwl1T+jePVhYpLqEvvgqLZgg4hcbW6GqsfaZdo
Y0Tr1jT.F2c3co2dmcdyxRKKsHO8fIcWVoqMFDSIJE4Werzx4jvXAjLbjwEv
.2bJkaAcqEHl2iEf6R2jx+Xr.YEqlaonO+ZbecZ97h06P6Mmz2M1cEktibtK
W0TsRWpUeyZZ15S3MyGFSbuWleKtOVL+8kuacwppYZTlp5V8ktRgl9qvSA4H
tIGg6pNjfSFq9LbDzodoJK60nyt5d73k3+VUWdtUcagPzXyhwUHDUJ.zWXjH
vPZYB6Xba8G8AGvHVGDmbVqCZs5A8hhpk8kdKoey9l76s4Fqq1VouyAaZuXf
3P09SYssBwQ8IRWm1LllCnolPnpFafhC7g1TUGETQLDTw4XMXTQ11Qjeu.k8
4GQhELLNpOnJPNJaHIhXdarB5XEqXucJhPG+NEsQM4ck4MpsGZOoojlun3Yz
q7k2EEXCHoAoGFTJ1aC56Xw9v329A6yz7vVPXqqdGZgtuH+1rmtl8XjI5QeX
GOLIbskkvZCNv4C.6Be6DYLxdb9wgw4uKV3Gnuex3652oje7d9uZ+pcu5Igw
weiw7SgeuCq576iToK5qk4ApHqN5QmKODeVb4GZOxojvzi7j+DaQNjDlVjm7
opC4DVfZuSxezcH2Td43Ux3miNjKYgoC4Ie5ZPtqYe.uqI4m29iCCJr1.MK6
s+3uqyGel6V9Nncbf.aJ+SSuv2x42auvsdFmVqvYiIp2emvgHBwvX.gjvYwT
Ne3bb2bc51atk5bKM63u1vz1o2tS2laUNzKhbtt1Duw0L7clj8BWh12cykuR
xdAhOtjDAPRtMZOpnfj.HJtvGIIe0jJpL6.5pZ7LH539EM4jDM.9XKkr..vu
QA1iV9l0SfTS60E973a7FFR+R5MKmPYK8RzvXvfs2NUGWzVeYxo5lB9HIRHh
x4iW4FE+zkDwGIAgPRfORhDBIQ8QRzSkQP7029j0IebvXwgfQ3SrRVx4JpLa
ThY3gfiSBRRD9vP1lpwIIKIyKQEh3Swduy8ox6oDu14N.Rh3E7EDIQ8xPE.6
jOaiXu3JmrJ4CeHDIk6RQ6Xg1cbFZHjD3ijHgPRDejDDBIg8QR3dpOTUVt4O
KkULVgXJQ+9BW73jKcGll2dnqqzSqzOjtY9thkmppLk51XpycUU6M0vic+Kq
ltrvDYOeUZWtnF0yHRW4+1a.h5xt+yFttDbwOu3+AR8+pjC
-----------end_max5_patcher-----------
jongly_4x.wav.zip (874.7 KB)
I’m on version 1.0.5+sha.9db1bdd.core.sha.001df55a on Max 8.5.3.
So is there something weird in the math/code, or am I overlooking something here?
p.s. I only had a quick look at the other spectral moments and they looked alright, but it’s possible others are off too. I just have spectral flatness as one of my “main” descriptor types, so I see it at the bottom of my patches.