Hello,
Sorry if I’m overlooking something obvious. My experience is that the tapin/tapout attribute affect all objects with the same name, instead than being object-bound.
Is there a way to avoid it?
This is cumbersome, for two reasons
-
the first is that, at least in Max, having an attribute of an object box change “magically” when you change an attribute of some other object is counterintuitive. And when I put in my patch something like
I can’t be sure which configuration it is used.
-
the second, and honestly more important, is that tapin/tapout are essential to take advantage of different portions of a network, but one typically wants to use different portions of a network in different places in the patch. The example of an autoencoder is paradigmatic: you want to train and perhaps run the whole network (@tapin 0, @tapout -1) but then you want to only use the encoder to see where the training data ends up (@tapin 0, tapout N), and then again you want to use the decoder to sample the latent space (@tapout N, @tapin -1). If these are all the same object, it’s a mess. That’s why I loved that you could give a name to your models, so that you can have different boxes in different portions of the patch. But this doesn’t work, unless their attributes are local – or at least some of them are…
Am I overlooking something obvious?
Is there a way to do it?
Thanks so much!!!
Daniele
1 Like
Indeed all named objects share the same attributes… n’est-ce pas @weefuzzy
one solution is to dump and load in differently named objects. that is sad, but a solution via dicts that would work well in your use case I think.
am I clear enough? I can explain more verbose…
1 Like
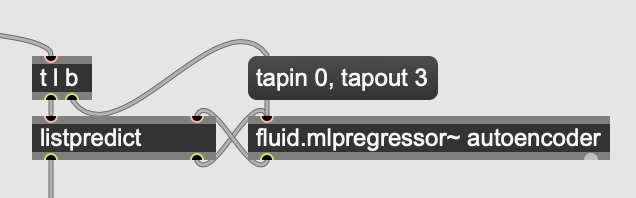
Now I’m doing something like this
But I wonder why all named objects should share the same attributes, this looks pretty strange for Max at least to me. (Maybe I’m the exception, of course.) If they didn’t one could simply do this:
(Sorry, listpredict is an abstraction that encapsulates all the complexity of buffer interaction, I needed to use the regressor from lists to lists.)
it’s ok, I guessed. as for the why, I know it was a compromise that was the less worse. there are a lot of attributes that need to be shared anyway so I think that was that. @weefuzzy might remember the exact details, since he made a miracle of implementation and I remember we discussed that interface design quite a lot…
Because they all reference the same underlying object instance, and all that object’s state includes those attributes rather than just the model state. Which is just the way they were made when we introduced the ability to have named objects. It’s true of some of jit.matrix’s attributes as well (such as dim) but not others (like adapt). No idea how we’d do the same thing easily.
To me, this suggests that @tapin/out shouldn’t really be attributes but optional arguments to the transform functions. IIRC, we couldn’t handle optional arguments when we first had these objects.
So, the least-awful thing patchwise, is probably just to use a dict to make a clone.
2 Likes
Oh yes, this would make absolute sense – they don’t really belong to the object, but to the method you call,
Of course, I can imagine that being malleable with a layer of abstraction calls for compromises, and you are probably right that jitter has some of it too, now that you mention it.
In any case, having them as optional parameters would be awesome, but even as it is, it’s fine – I was just caught by surprise by the behavior.
Thanks to all of you!
Unrelated to the main thread, but just to say that I use this feature all the time (e.g. load into an arbitrary named network (e.g. fluid.mlpregressor~ whatever) then have the instances of it elsewhere in the patch inherit the settings/attributes of that main one, without me having to explicitly send/set them everywhere.
Indeed, @tapin/@tapout do seem like they would benefit from being a different case.
1 Like