(not really code sharing, but more a “New Idea”, but which relates to TB2, so I guess this is the place it’s supposed to go?)
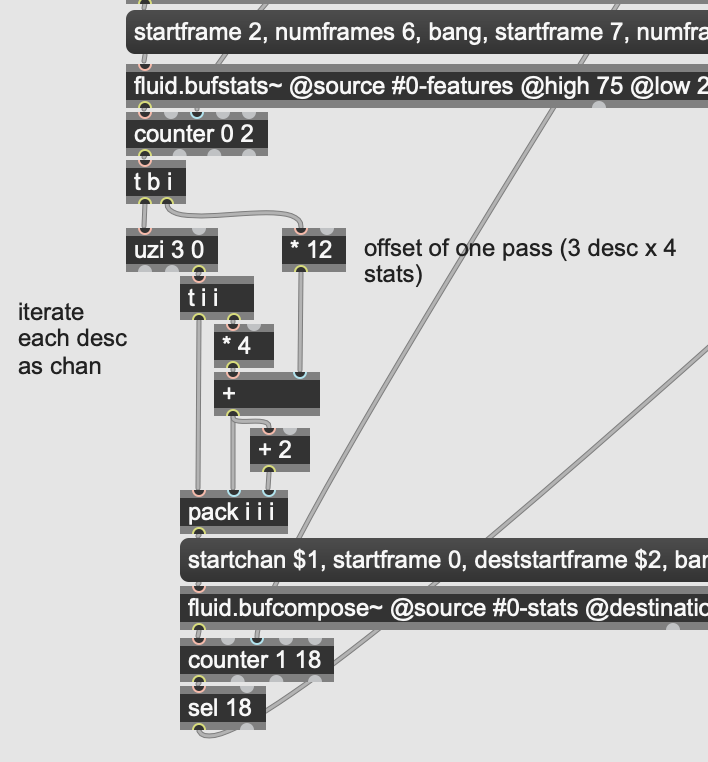
So when PA was sharing his APT reconstructor, at one point he takes all the bits from all the buffers and spills them all out into a single buffer.
The code for this, although not complex, is faffy, error prone (potentially), will have to happen super often, and doesn’t really matter in terms of how it happens:
This having to manage uzis, counters, and arithmetic stuff is going to be a PITA because one number off here or there, and you’re throwing away potentially several dimensions of your dataspace, and same goes for resetting your counters. It’s a massive potential point of failure/corruption for absolutely no benefit. There is nothing to be gained from “rolling your own” data iterator in this context.
In speaking with PA, it was clear that the order or orientation of the data in “The Long Flat” doesn’t matter (as long as it’s consistent), so it strikes me that this is something that can just be standardized, ala Max’s right-to-left/top-to-bottom thing.
So you take fluid.bufcompose~ and feed it (say with a “flatten” message) a string of arbitrary buffers (of arbitrary length and channels), and as long as fluid.bufcompose~ was consistent in terms of how it handled multi-dimensional (channel) data, it doesn’t matter how the data is packed in, and this can save tons of work and errors/problems.
that’ll teach me to share stuff… 
nope. every case is different. remember @leafcutterjohn’s nmf use? It was made possible (and super fun) because interface was souple. Same here: if we take for granted you’ll put stats, or even descriptors, here, then we load the dice.
That said, we might make a few abstractions to help - but again, interface is problematic (imagine, potentially 7 stats x 4 derivatives x XXX descriptors x YYY time slices is what you have the choice in… no way to make an interface that is not biased and allow you to explore that…)
Yeah, if you’re after specific things only, then you can peek~ everything you need, but if you’re just “flattening” everything in all the buffers, then it doesn’t matter what goes in and how.
Or actually, even riffing off what you’ve said, you could give a flatten message @startframe and @numframes arguments, but requiring no @deststartframe since it would be arbitrary (even if it’s consistent).
And in @leafcutterjohn’s example, the order of things mattered for the visual rendering, whereas in this more data-heavy approach, the data can be in literally any order (as long as it’s consistent).
Morning @rodrigo.constanzo – in the patchers folder of the TB2 alpha 0 should already be an abstraction that does part of what I think you’re talking about, fluid.buf.flatten (i.e. it flattens a multichannel buffer to a single, long channel).
Something like this will need to get sucked back to C++ IAC, because it’s really not something you’d want to do language-side in SuperCollider, if it meant lots of round trips between server and language with all your data.
Whether that should go into bufcompose, I’m less sure. Maybe this is its own object.
Oh yeah, I had forgotten about the flatten thing. I was mainly thing of when you have “ragged”(?) buffers with varying amounts of channels/lengths, that those could just unfold in a predictable way (all chan1 before chan2, or all buffer1 before buffer2 etc…), that would simplify things.