A little addendum here.
When making what I thought was a bug report thread I discovered that fluid.kdtree~ just take a really really long time to fit larger fluid.dataset~s.
I managed to fit a 1mil point fluid.kdtree~ and the converging is still happening. The closest matching so far:
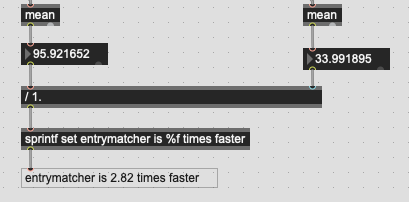
As I noticed in the 200k version above, the duration is super erratic for the kdtree. I guess this is a function of how that tree-based distance matching works in that some may just be closer to stuff (?) so it takes less time, where other things may take longer to match.
The bad news is that it’s still really slow.
This fit took over 20min of pinwheeling to compute, so the corresponding fluid.datasetquery~ version of this would be super unpleasant to test, but coming in at 20min+ per-fit, we’re looking at around 36000 times slower than entrymatcher if you need to filter or touch the data in any way.