So I’ve revisited this based on the last geekout session.
From what @a.harker and I believe @weefuzzy have commented on elsewhere, the way the data is structured in fluid.dataset~ stuff isn’t “ideal” for small datasets, but should theoretically scale up better, particularly once a fluid.kdtree~ has been fit.
I also wanted to do a more apples-to-apples comparison than the numbers I had above, as I was comparing separate patches with different functionalities and setups etc…
Here are my findings, with some test code below.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
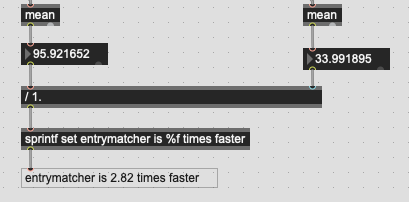
At first I wanted to test pure matching speed at different sizes, with a single nearest neighbor (trying to be as consistent between the approaches as possible). I’m generating a 10k point fluid.dataset~ with 8 dimensions, along with a corresponding entrymatcher 10000 8. Both are filled with the same exact data.
I chose 10k as a starting off point since it’s bigger than the 3k above in which entrymatcher was faster, so I wanted to “scale things up” by a factor of three to get the ball rolling.
I’m also comparing the mean of the output and testing hundreds of random points to get a decent average over time.
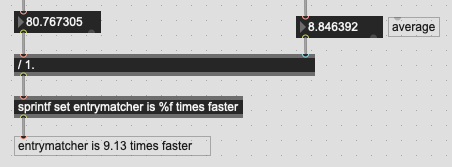
This is what I get for that (10k points, 8d):
This is in line with the numbers in my previous posts with regards to raw matching. My “bells and whistles” patch also does extra analysis, lookups, etc… so this is point-for-point the raw matching speed on the same exact dataset with the same exact test point.
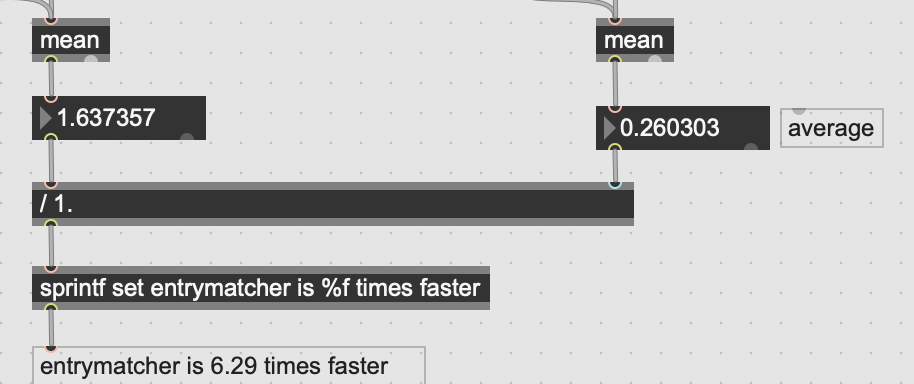
Scaled up to 32k I get this:

It’s starting to converge slightly, but still significantly slower.
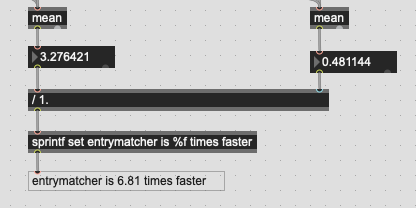
Big jump up to 100k:

Again, an improvement, but still slow. There is convergence though, so that gives me hope. I think around here I’m also at a decent “big corpus” real-world number, and 15ms is definitely on the slow side (for real-time percussion stuff).
Things above this point get interesting. I initially tried jumping right up to 500k but that patch kept hanging. After a bit of troubleshooting I discovered that I could not fit a fluid.kdtree~ with that many entries in it. I’ll make a separate bug thread for this with some hang/crash reports.
So I dialled things back to 200k:
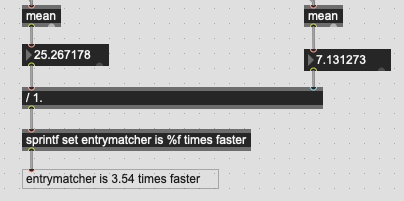
This is the best result yet, in terms of raw matching speed difference. The fit did take quite a while here (more on this below), but I suspect if I kept going this way and started getting into @spluta sized 1mil+ fluid.dataset~s, that a fluid.kdtree~ might start to be as fast as or perhaps at some point even faster than entrymatcher.
I should also note that even though the average is 25ms, the actual time was jumping around like crazy.
I was curious where this “changeover” would start to happen, but I’m unable to fit a fluid.kdtree~ big enough to find out. The trajectory is such that based on the decreasing difference between the two approaches, it would presumably happen.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Now, I wanted to compare apples-to-apples. What the above tests/comparisons leave out is the fact that entrymatcher can vary the querying/weights/etc… per query. So I went back and tested things with the fluid.dataset~ + fluid.kdtree~ process also incorporating fluid.datasetquery~, which means that fluid.kdtree~ needs to get fit, per query. With the patch from my previous post, with a smaller corpus (3k points), this was considerably slower, but I wanted to see if/where this would start to balance out and converge based on the above tests.
For the sake of consistency I tested the same size datasets (10k, 32k, 100k, 200k) and only added a fluid.datasetquery~ + re-fit per query.
10k points:

Right out of the gate we’re orders of magnitude slower. I ran a ton of points here just to make sure that it wasn’t some spike or other thing going on.
32k points:

At this point I was manually banging individual queries, since it was too slow to use a metro consistently.
Big jump up to 100k points:
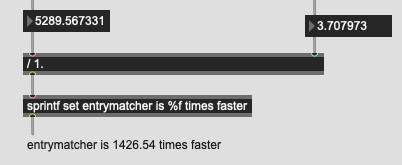
Over 5s, and at this point I start getting a pinwheel per query.
Finally up to 200k points:
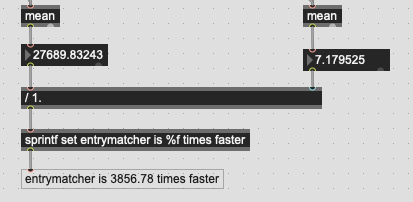
…a little bit slower.
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
So from my tests here, I can’t scale a fluid.dataset~ + fluid.kdtree~ big enough to mitigate the difference in raw matching speed with entrymatcher using the same data at each step of the way.
It also seems that fit-ing increases exponentially (?) the bigger the fluid.dataset~ gets, so where a fluid.kdtree~ might start getting faster, having to fit per-query bogs that down massively.
I was initially worried that the ‘copying’ step of fluid.datasetquery~ would be too slow for real-time use, I didn’t anticipate that even a pre-fit fluid.kdtree~ was still significantly slower (in an apples-to-apples comparison (while ignoring the variable queries possible with entrymatcher)).
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Here is my test code. For the sake of ease I have multiple versions of the files with the different numbers plugged in, so I’ll just post the 10k versions of both and you can just tweak the numbers as needed.
Here’s the patch for vanilla matching:
----------begin_max5_patcher----------
5045.3oc6cs0iiiic94t+UHXj4spc3cRkmxNYSlEHyr6fLSvffAAEjsYUslV
VxQRt5tmEa+aO7hjrjsjMkMkc0XbUncqRRTjmOdtwy4H5+9aeyrEYeRVLK3e
I3WCdya96u8MuwbJ8IdS0e+lYqi9zxjnBysMaY150xzxYOXuVo7SklyG8hLO
5YY842jKKT2VTYbV5iIwoxkYaSM2Ip5NR2tNNMQVZdrv5lEUt78woO+XtbYo
cXEFhlCdHfwU+WqefPxCATykPf4ff+2cO1rsk0OWP0YiWYFjYK9s2g.yzm6e
712p+3gKjrKiUTwyyNOZhJ3cnILA9P.ANdZBF5SZBOOHKOnXSz5fnfEaSW99
frmB9+1JyiU7JU2cuyom4r9SYokoQqkld+uHSdQVFuLZ1v3GMjOGQUnDQiUP
t4+HrSBY5N5onkx1cdaXjNq0MVD+6laTOU3QzEMOXYtLpTFjGktJacvlr3zx
.0wFH9yAeLt78Awkup.ZHfMGyZ8KWI8gPBOg6jq.tCav8nfUQkQExxfmhSRj
qrHd0rgh.VHyONatevVNsEOLhA7CVx7HTtXaYYV5XUtAgXrlVvDtgxH0eN.g
U+nrmp7yaj1myrEQJMqMMpM+BdGrlqf7RY9ixznEIlVdNT5SIYpA0nUiC.yw
s+gC0FpLJvEVhGMHYiFhrm8vQHcJ6njdybe95Hyfjc0.CFTLGCHhPl.CoPDg
BGvB2TAMzWqPSu7IWSnAy+phqgwXSnHDFN8fwPFgTmK+yq0vfLOHtHfMW.CT
9PJKBdJpPMR7B9wCMpffg7w6Jo.cNtRlJ+npwGPtEaxU917Tf1V69j927zDP
3T3bHHr9WH.y0LPgmfOZPKP8x+vB8HB8OG.m2KoiFKoCLTIFnl5QBBlQAPAB
DhNOJWIMq496g7IPOR9aBT8ypy1CCgxEJEESoDyuTs+TUqexWy1DPGW3TLpV
hrhJUJJhSjp09Vn7Du0S+Myh1ro0oeSqlngleKy7fDOzbp3T6ofMmJW9Rbc6
YMmMJWAGkJrXat0WyOwpceV+XxVIyS2FadR1SpljpFRloCsOpp01YcfzLqUe
41t8aze.LttwHVWSEszinlteNIa4GjqZoFQAoajowosWbRmKuR9Tz1jxGa6Z
JTuR3dtdsKt8dwF+r+S4wQIMDvy4wqxR0ChNyD5SW2cJlGpg1nsIFycjFsom
Fq3ATvx.WrPQjaKVDkqmnpLffpuXYVVR2K0ztD4SkUWdSbZ5dnXY1lguXd7y
u+HscQl5hqO1y1bkhG2lZu5iJdhxGKhdoKZWFkjTIy18w+onzXkVboV2scoE
MWzZD88EKyyRR5Pu1q7ROWYkhGeo7iwqJeuoiZyLnt83M0LQyZlkWE+rrnr6
4Jidtn6YJJ+rEzacpsKpjgerTtdShhJ5dCJoi3hxh2m8whparlQqM.rKdYsk
oaq.ry42SQnQAWi759J8.stPeJ9vg1XgYU0W+YCi7fJ6bXAVGrHq1CxZ+YZC
Wl6Ock7Ssz0TYWnRsyYBQcrUz0dg1ZgYTOD.BON.RAVEa.a3212RgWAP05Q7
HnnTZWrK9pcQEiJ8frTYP4GyBJeetTF7T117fmheQFTD+IkCXuHSCjZcGCBc
HmfNh0YJR3khcChaBlOwMa+dY7KHLztTMFfGJvgB.2QwOP+jXy5wNegqcFuz
gnZ.URFJRe89ApBEOxx54iJn+gftziRMbYbZis7ecGAnuQmlnF6nPuPdmFE0
C2IYT.u7AQ0Iqc.al1J6pGsdT7XTYYd7hsk14t1dTNJKeJ2vVDkrm4p9LL91
cCN+369ZYTpehXFpajPTNxqDrBO2E+aW5xCZSs8uBFL8bVASWEv6fgkIxn7w
tDNAg2AGHB5.QDBS85xYvLOt5seOI347rsaFM0KrVdw5HfS18KOTABvKInO8
RynyhlOufeGRXGxfSXJl4VIOQsr8IIt3dOr3Ctp8ka1pW.vw46GbkZtGiTHX
NLr0OXjRcwYKQLbPMf8l1jcqM8OTK9GYWgr.0NHhX9jr5e3bZHEJXMyv2iEv
8XA7GkXAbYqMAWU7ClPgZkYQzyY0HCtRekCTx7WhRBhSCVWnCZetbSVdobUf
BOj2x.ArH.5DtMrFhgBwBvnuia8P4fDn30HDfls2HcX0hWGTUYVeoVw9jBsU
gUlxtTrsq47gbF5UC39NkFMmB9xnA1JMADaRQPyoSItRdsgqSlp.h3poIf9G
KMApU+RuZJBX2Dr8xhyuUSYUAT4ho8ym0avPQpaUPgxAzh.aUtZpQQqG.JmA
p7MnWm.PuV.RqH7UAGEm.GiznVEPdTv65EsWGivIcBixJ2ww.ZBGCtFzakku
.3TEyaGGCSYDuINNFfS3X.Oh4hoZLfbMIH2z.+6VXTtcoG32xhSGafgwDp1w
.LEMG1JtvLho1tL905q.gK.uBBDNAXhwFFhmCE69EQHSRfv49rx01n7DPpbH
npj9JFajxqRBPuzND32rdvI9jviV9AKU2rviwl4CbXO0on.3WZl6QZtLXQPx
4NC2mzLDeJwYzQS+wfr3BOR0cJYUkKcahxiKxR00OB.DHFKdTocinqY.Np4W
BVywGdJwcxP3QRbgIcm5+Uer4+6sbFaJRdGsIIWuXuvFejplt8EWGsYSmbOc
dVWFJsq5pc4aBfyC9mflpdwdLpp5Wr+E1VEL1+fXqFF6ePMUEi8XVU0wX+Kt
sJYp9Kw4lZSNYNpsZMBWuPWjeykqXBTma34OSN69Uqg8JQG95U9VHL0rvMU9
VP9JS9tL64mSjiEpoLwbw9k.eUoRb14Uen5EgSuR4UW8nyyBPfwpzoWzfGNm
ztZR.rlPsg7XMGvwytskTT+uAQW4RJhI7YIE8gTYTtZAeAJ40RyqG7neEQ.g
GBJ8pdV8oee6X7samK7htAHkOGiZqUFYewwgp0MCvPlfH3TR3k4R5fRILx0q
Dj5m9g7ddAt8eIHw7ttxyCDXLROuMp.wgkSzT.BnuhKDq9eOd0ARe+RSbJJD
KF9dgXcuPrtWHV2KDq6Eh08Bw5dgXcuPrtWHV2KDq6Eh08Bw5dgXcuPrtWHV
2KDq6Eh08Bw5dgXMhfDtX6SOIy+xtjID7uVDsVYLYzI3z5WKEz8sYMzTwNmL
0RmN4JCuy9E5yrq7TbYPQ75MIRpde.c70nlh7C4TJjJHHBlqijtNxxsiOJBo
y7MyqYVg5yz8mq5SYPchlFc5k5K5589VNKnduJ1n9rXtdJYa7p4eXUYtT9kQ
mjg9xxVuo+2tCEeDX.epr+2HkzOl3yrv9twWWaLkPwA4bp2hfAEdtkw4P4dk
32LNFO9LN1O022ta.6rq5MSRfOhNRhWKFHo7Ce4DYeFOR7n+x.Dh7eNjH9rF
g196wABuTPFvP1bTXq7uCgMaEUmilgNIc9H0l.E328qRk4swukUpn8CqGg9J
8WxDjTQpO2xJq1mv0vfWPgd0RxO6srzA4BP9zGJy955XI+PxfEIH1uUFIg40
JibHZ8HlDPbt0W4d7K7jDaOaKuDh2c96rlCqnqd80ig8tudjareMvPfgmsOM
U92SFL5V6ISE81qoJFZp7cAC7tuK1E3cVduTOm2q+J.1Dr4Cgt09q.YFd4dK
RNxj6fBDd6cPAYScWuFimBWRDuN7Holr6asJ92GD90qHHqRAKch9FHAGdkpv
uySKNwnkBpqju8q4SxjoEGIt4aqhUy585gomeiB8oNq5Hz1xn0EFi1d8OCxg
SWLZgfI36MhnUqrnw2r5jVzOs7P+0+Nm62nz5Ya412EIv4IIz26.BDglZC59
O.sUegc8kSF39SyEz+qmE8h8x43AnEdy0MRUNx412OS9VUYmEiatitIO2BE6
mbvJ.4fjBF1NofCkTxVYJ+.L20NRTkl4i1SXezQ.GHoPezQNzO7t3aV9Jaw1
Cl7dFh5f2M8L7h5YtK7KlY.3EhtbgC7KBhGlG4NMQx8QOwcA87BMwbnmXBez
STWPOeHXyItzSdglvtfd9PqHG5hnrO5HW377P+vbRAAxG8jKhsXefcLW.OpO
XwYtHLw7gBBlKliY39sdAu7t9jvI3ZQjP1TXhl4hJDpOTgvPtvyf8fIYp3ZI
GPcw7EA5CZhdsLTRcgsm4CMilo.zolm7gVDpK7dTenCl5hgRR3T3yqScMZRz
hPAtnklOEZoMc8oXhHdQvvEhbhv2qj2WDWVLCE4qd5jxI9XwLDtqRjWbOwtV
SSNYzVLEbhN00DxTHoSbQ+FyKSjfq05ecwwOBySczozRh7gVRrSQpyGcjSgC
wK8jKZPv9vGYL6p0StXRg5CNOLx0n.dw8DzUuwu3dxEWA39piNICgW.OWlkX
dXkLHgqgl06FubpqoSgsKjKNVA8AqIxIUH9PSOzodxGRAPmb5vGQhABcQvNz
W8zorHi8BM4xBjNLZH1T1s2NojtO1aGTZucOoC24jFdWSZ+cLIyKrmc6hYuz
Dt60ae6p3rexrW+73OHS2ZyGZ8NRTWjXwyOEmjrLKI6fMNp5rWNyd0lMoo56
8WC.yQgDHTnfk4XHliXliTGn2TAg6difMsAV2HBkDBP5akvPbB0bj.goX8Qf
8ZFZWeAfg1d.DJ.D6QpSoKfi1MKJ84p81HdqMnmM4Y5WK75s7o43lW.wnskY
OmGsJt50gt6d14CULR4pqt+tzyr0J.MttMsY7ZlL99sKitzIflA2.yANhKcm
EDMXufCnBg8HAA2ayZlEXTUmnuWl9Gt8H6SZRlDpe8TkIJgCU65P5bDfYGMP
FGYYeD..jzYvnv3NsJDPf5x3SQugTB2PCBBJjaPCJqocs2zHTJA9aajoA+TT
ZQvOIWGuHKY0tr5GsboZf2oavHytln5.RMlokLzmq8fSQXq2uobgBZsyM.nP
XOR8TPntssSiHbJDatUTHVQYlinPEB0sQ5hkvzvGiS05sjMLR3PDjYaVsDJp
MGgWDH9gnxxiIPzd2T6WaYmo8KSrd6mvaCne7OU9noYfiMrLUVRK71TvXJdI
E+C0JOnDi338Y795R314l4Yo6CDPsDXeG0Fd2S9ztstbLQR2Td0cFHjpMxY0
LP3.ybgdp.6pXkgOo9i8G9s3nQdii9W94+iWklbbSi3M2te+LkPFlQLrLPNg
EFVcDH7n7j+kOuJO6YY5Oa.1ivZRAblgz.LJFZ6GHBhbvZAgAg.qWTgHFw.U
zPnRvsaaabFt6bo1yMioSU2QY14GsvuQ+eX+BEPs2dVykZIAysxq86aXVbg2
XwMkBX7xIv01c5PwgbqFPbXkF.8onX+vs1AOEMldO7nyhG+nrxtQY6yJ+cxT
4KQGkIlToWruiNMm3fJJOq93R0GG5ad0us0qqw.9Xbf6EhFtIP0QPeOr9yM6
EZuhFTeWTb5WbbToX2azAc3Q9enU7wXE26wFbGHY.qX018wjLlPupFT+mEIw
qp2+s6eL0+p5bUBeOsZCJW2qMSG6iqHd88xUGCq5iJXNnwD1Cv3ygsZ8b4we
ZYY9H0hLcCH86b1WNtmAiS8wkvG4SJ6ulsRVLVdjyfS2Y+QlZSl+0SqB4Dp.
75nY65EiWe1gFMmfg1OFur7zX0MmA9G0a79ku5713mVlsQNFMFmkL0tfcGh0
+LU7B+bzhwxD3p39siy4mUdyu3jNP2yRR.tZhbBsr+ys9l7x8IELmQ3PqwHB
FZVIIoSFRtgdA+eu9DIV5JBu+RzKxmxxW+E+5pIXN8VBzqhx+v6R0e8Y7Nyx
kmlH5AOA2l2izg2ilW2HcziF.WCfa+AkfznPj2jSjlriHLOlCC4fywS2KbJ+
V0dmJ.TsK93iGEZLIC4ng1ELxDhbrXx4V27UAm59IuXQhTYcylewuMK6CyNA
i4tbYbvAC6eN0arbwoeXbbH6BYLCnEAZeD7xYQZfE0DDPzXzGa5himUhoSy2
UII3mlhOH9utkludyf1o6rdCTwoa1Pb4Oz4ydiv6H5EmueuHl7A6Zx9Eco8b
qcVJQ6Jwocgd+Xi.BIUkRPXHVvqNhKbHuTrF6jzFcz0Ba9itVG8IVy2RbNPS
6Avs8xqG9cQ2EEwqj2OyDM3MBt023DNDVDBBSQgcMVp0.384gNaKGSlqphlj
2e3QGQqMWnqwrG58nqnW.Npq2SbUckNbaVr824atFzsV0zm2CAfc+u4aS1Jq
+dfy4U+ig7pj1uSYTn2UAUM.yy9X5nGgWGkj1Q3+1miF+.DfBo1ZJfywXjUZ
CAUty4+A32kKkmwHzfdMwTCxz923+A2OnzrkVFM5gmf.XLaz9X.0fy.krPXH
0+iw+K4pQO93Md8BaVTEnxhguGe+OxjjrONdHDQskDCWu0SZFfTEWI8T0SEM
D.DSAAf9Zj.Lou36xRNCVjl.mPUdBQsUmTaifdY.tYa9lD4nbNk.r90fn.Vn
gGFInLjvQOz3MkWHARUpML51zZO7pnYtboL9kim4t93YZVa1tAGnc0J5mAmc
IJZ1hQf7mjgn2kaQT5ACqrevqp6ZkPPnWsjTHSWU7ZyBxNP1+xd8Vzp.NDvs
4Zhv.gUk3NG5UdmxnMmpRtaEgquOpLK360qBcl25+hR4SaSRJOYBV1uXNETJ
zFLWFlisE8NSIccrDdoeWW3lak0rn.cDDZpyRuRTillPBtv5mAtgSFiBwgBO
rT8aHdz7svzqj2WfOpilymGetl.ZzxrpSbEHoDtqxMwQJ6x+bbd4mC92eN6T
ADFFFBrdWp3iIUoLmA.XX2B4cPqgNVc7cAVL67.V6qNmICdZhsXS0TnYi+7s
+i29+CLEF0mK
-----------end_max5_patcher-----------
And here’s the patch with fluid.datasetquery~ and re-fit-ing:
----------begin_max5_patcher----------
5109.3oc68r1iiajbed2eEDBweaVk9c2LeHHmyk3.b1WLhcfQfQv.JINyRuT
jJjTytqOb6u8zOnnHkZJ1TpozrvZFfYnHEYWU006p5l+s29lYKx+Tb4rf+of
eM3Mu4u8127F8oTm3M0e9MyVG8okoQk5u1rrsqWDWL6AykjeJIKMtReMX8I2
DUs78IYO+XQ7xJyylQ.yAODfYp+R0GiPyAA+u6eN4aq18fP0m0bppOuI17Tl
M6gfYKhxddVyMlrRCU4K9s2A4yZ.fhn0wUwEOFmEsHUe2.0k96u8sp+7fq3Z
7GkO3cO0p3OowlYo4QqzPwHIBPTngJDJzjAw.jAXejgdIAnY9CKqBVDrXrnH
k.mK.DQHSfgTHhPgRTjnm1wnycZ2PrO0Te34f3qiKKidN9HLuHtLt5gfmRRk
rPAff+4.4zl7GIpDsZUgDHhkmUXk1fN0zOWSAHXyDOH7bm+sSCDdbx+ozsIq
luJpJRRJ9RPYx5MowzxsKjebzr8XgFS4T3bHHb2uP.l+P.jMjx.7PbEOIkGq
TGXmrPt0xDPjPy+ynXMYfLYhAryAUWrspJOazHEDqwFLgqQGxt+5McYPruUm
KYTj.0XwzP.XNt8Obod.FGpPXAeRrjQYmD0qu1S4Eqiz.I6pQLXPwb7g52oJ
xPqevD3zQZnuVIMV4StljFL+qJtFFiMghPX3zSLVludcbV0QVIjmq3yqUjAo
6CIkRK8n4bbPUhzgifmhJqNC+msQA4gZkPvPCIDzKIDbL8Q3SWEK2TjjU8Tf
z4ffCQ9u4oI.ws4IAB4W+oXgdjB8OF.mOV+Esi5FuFw.4TORPvLJ.JjtRhNO
L236jMzm.8H5uIPEyzY6igfNGIwXJkn+khnRungdc1l.l0FPjLpFjrFKkpJR
RieItnLQ5qz9m9alEsYSqS+lV2hhz7a45Gj3glSkjYNEr4TEwujr69YMmMpP
RNpjzhsEZ.e1mXjY6eL4qhKx1lneRlSJmjpAI8zQlToW4lnklaVMqs6xshVS
yKAAZm2pCQmHZoGQNc+bZ9xODupkZDIIcSbVR1FUbRYUQU0vdykWE+Tz1zpG
eJOqpL420P.TE5ikq+TMDZ8hJbPC9+ohjnzFD34hjU4YJfnyLg5z6FNIyCUi
az1Hi9ajEswxMK4AjjkdtXoDI2VtHpPMQUaBAs6hU44ocuTy8kF+TU8k2jjk
c.UrJeS+WrH442eh6cQt7hqO0yVekxG2lYt5iRdhpGKidoK0tJJMsVls6i+S
QYIRs3wJc2ZzEzbQiYz2WtrHOMsC9ZtxKVtxJIO9x3Olrp585ApMyf7qmrYG
SzrlY4UIOGWV08bUQOW18LkUe1PzacpsKpkgerJVF2pDK59EjRGIkUkuO+ik
0ewcLZsI.6SKVaY51J.6b9CTDpUv0HudnROPqKXMhYsfIiaT0u6uMLx8pryg
PrNJLq1.4NOZZStze+rUwepktlZ6B0pcNSRTGaEmLCa8Z0n2zPALJ1.1yylW
IfxHR7HQoaNo5RUzpzCxyhCp9XdP06KhiCdJeaQvSIuDGTl7IoCXuDmEDqzc
zKoC4DoiXblhDdoztdoaBlOoalw8x3WPXnIXMFfGJvgB.2QwOfcTrIhryW3Z
uwqzjr9TIowH00sSnJk7HK2MeTS5eHnK9HUCWkj0XK+W2i.punSSTiEJTgx6
DTrCbmDn.d4.Q8I24.1LkU1UOZ7n3wnpphjEaqLycs8nbTV9jtgsHJ8.yU1L
L918.me7cecbTlexYFpatPjNxqpEx4F9eSZeSxrGACl5yhBrLMNpXrgvIH7N
zAhf1SNgvTuFNCl4wn298zfmKx2tYzXuvX4Uhan5P2z+xCkDA3kj1G6E+5Jl
96PB6XFbBSxLiYM+JCaeRxLN9JUmyMAK2rUE.vo466MRM2yRJDLGF15GLRUt
jyUhn+jZ.aRrt8XS+CUv+HSDxBT6jHh4SRz+v4zPJTvZlgumKf64B3OJ4B3x
hMAqMf.45TgZjYQzyIZjdizW5.UbwKQoAIYAqKUIsuHdSdQU7p.I8H9VlHfE
APmna8qgnuTr.z563FOTNp.JdMCAnYG.o8qV75PUkl0WpTrOoj15zJSYWJss
q479bF5UCw8cRMZNk7kQSXq0DPv0cSEcJoqjWaz0ISU.Qb0zDP+ikl.Yzuzq
lh.1Mg1dY442nortEpbwz94y50apHU2UPozAzRUg5k.XPT1pZO.jNCT6afUm
.PuVHjFQ3qBcTL.cLRQ0pIjmj3c8x1qiY3jNgYYk6HLflPXv0jdKs7E.mpbd
6HLLkY7l3HL.mPX.Oh4hoBFPtVDjaZh+cKMJ2txC7a4IYiMwvXBU4X.lhlCa
kWXFQ2aWZ+Z8UhvEfWAIBm.z4XCCwygh8+hHjIIQ3be14ZajdBDKcHntk9JG
alxqKBfUbGB7aUO39rW+2Ds7CFrtIviwV4Cbnk9TT.7KNy875aH8bmgsIMCw
CINO3pcvNV6yE6RmVVU5R2lnhjx7LU+i.5ac9.GT6FQ0y.bTyuDrhiObHwcR
ezizjRypb4g8Gq+u01YroM4czlT75EGj13Sz2zsu35nMa5T6oyy5RekcU0sK
eS.bdv+.T20KliQ0c+h4SXSWvX9.wzMLlOP0cEi4XVc2wX9D2zkL0eRbtk1j
SliZqVivUA5h7asbESf5bMO+YxYaWsF1qHc3qW4agY4rcSkuEjuxjuqxe94z
3QubRYhiWNo0sJwYWW895WDN8JUWc4itHO.RAiUqiUxAObNoc6j.XODvvdeo
Eywyts8Tj8EQzUtmhXBe1SQeHKNpPFwWfTfsZSdRV0nWiHfviIJV0OK+qeWd
L7a9ZM2lz.jxmiQsUKiTEOkLGJCbFfgLAQvojvoZE3Rtd8fjc7GJweVqe4jI
oGjXdWY44QDXLhkEjJPbb+DMEDAzWwchk8kxqJS5G1ahSQmXwv26Dq6ch08N
w5dmXcuSrt2IV26Dq6ch08Nw5dmXcuSrt2IV26Dq6ch08Nw5dmXcuSrt2IV2
6DqQjjvEae5o3huruXBA+KkQqkFSFcENM90RAcWNqg5V1o14gKo3J8u4940s
w0mRpbXiKEM7F2Y8dtUnvqEPg5yx5WHGy3fc0SZzUQxVRzstZlETu2sZTh22
2Z+vpph33uL5ZIXqXZVKy+f6gq3gpx+o2zZo9rXqua78uFiDZYab1VytfBO2
10ruRrR7agESFegEsi811ECXmc2soq06ITER7ZS+DG+guLPQlwijdXuc+fH+
WpHhO6Ens+dx324tsWo0P1bTXqxrCgMa4TWx1Y8t+2m7AE328kR..L9slRIt
ebaGXqEeISPsCo9bqorPFic9ZMYvKTAqZI4m8VSZubAHe5pjd+acrneHo2lA
D62Nfjv7ZGP1GtdBSBHN23Rb2xiiPtfrV19cIDu672YMGViWV80avlHa795Q
tw90.CAZdVaZp7umLXzs1SlZ70poJFZp7cAC7tuKl33NKuW1Mma0eE.aB1jg
P2Z+UfLMur0dgiL4Nn.g2dGTPlJzY0X7T3Rh30gGI6Paawp3eeP3WwW2H51g
pGuMlfN6CAtRc1WYbZPkbFuT8pH3bSPEyD1k.bouYYrSKvWu445JpSmn2oL3
vqzz54Ys17dxBpZLyCagWxjYsFIt4aSl0y5VijvyqPTnOQ1FA2c4YV8By5By
4LLTSLHg7471svLU2iIb+RM.S0qLr+uswEe9Ki+E9fA4oR+WXchyB6Rtktv2
TXLe52xthwzxw0KrbLViQCxgSW4XffI3cDSzpUFpw2rZPu5GVWo8k5B2uhIT
O6OuYcGBNOsj1VtWPDZpcpmL4ubAUe9L4BruTLoS8aVvatcSpLXN2dar4ayn
cRHm9azsOYLjhC6CfZBxQ0+Orc8+6q+CZ0TLGQyccfD0cTxIGIrOFHfCnTnO
FHGFGdW5adwJy5pAL4iLD0gd2LxvKZj4tvunmAfWH0kKbfeQP7v7H2oIRtOF
ItKTOufSLGFIlvGiD0EpmODr4DWFIufSXWnd9PqHG5hnrOFHWzJx7xH4BOtG
FGlSphP9XjbQAA1GzNlKDOpODlXtH1x7gpHlKF9YX61IgW9POH4DbsPRHaJb
Ff4hxJpOTVwPtvyf8fweshHz.iDxKxAtfRbOMPCwfP8gdQp3ZoCg5Bwi.8.+
.kdsbmg5hJClOrpnmBFhGm5CMvTWjao9v9E0E2YHgSQjINMznIQCr1BxPyjD
uvcBbwLiOBtkdk7Kk3RXdTjuFoA4M8gpdB2UofKdjXWqoIWbxf3CkUDWjiYd
g3AtVQi6hygDlmFnAcaxGJhvNk2PeLPNkbFuLRtH0h8gezX1UajbQMN0GbdX
jq4j7hGInqdcdwijKVa49ZfFjgvKDOWlkXdvicjv0DE6c2wbZnoSQ9FPt3LC
zGrlHmTg3CM8HmxEpOFHWDB39HYMNopxGzNX30BkfgNv4g7wzDTbsRjLj6Zk
EtTkUPmjl7gldnS9Q6ENBnKFuB80HMjWmXufStDm8wY1xTj7C1lBUiwAaOgG
r0Dd71RX+aIgGtcDpWM7l8hsCJL+98NlsqRx+I8Fo2i+Pb1VSGHra69qKkXw
yOkjltLOM+nckwc8KvLyUa1AD28c+0.vbTHABERxxbLDyQL8QxCTM1Fb+1sg
9df6tIBkDBPpuJgg3Dp9HABSwpi.Gban8iE.FZFAPn.PLGIOkpkoZeaQYOWu
wAxas62soHWsmqra+TbNtY08GssJ+4hnUI060Hc2QrenlQpPd0C2B7lsVRPS
1cOsY7ZlL99sKitzIfFfqm4.GoKcmEDMzdAGPEByQBB15s0LKvnxAQ8cYpe3
liLOoIYRX2d+PbpT3PdecPcNBvLPCjwQF1GA..Ic.FIMtycEBHPUyyKw2PJg
qwAAAEx0TCJq49ZuiLIUB7etINK3mhxJC9o30IKxSWsuOZhVtTB3cFFLRukD
KOfrilojLTmqMvIQr0GdqbgjzZla.Pgvbj7ofPcu2N2DgSgX8WEEhkXl9HJT
Rg5dSp1SReiOljozaE2vHgCQPl411IghZyQ3EAheHpp5TBDs2pR+0V1YZuSc
n1am7F.8i+opG02F3TfktWtZQu0snojWRx+PMxCRwHN9PFuutDtc917rz8QB
nFDz1QsIuGHeZ1yzNkHoaJu5NCDRUF4LZFHbfdtPMUfcUrRymr6OGB9s3nQd
ii9W94+8WklbbSi3M2tuclRHCyHZVFHmvBCqOBDdRdx+iOupH+43reVSXOAq
IEvYZTCvnXnYbfHHxAqEDFDBLdQEhXDMohFBkBtcu2Fmg6NWp7bSa5TNbTlY
9QI7q0+GZWn.p71yXtTIIn+p7c980OKtvar35luMY4D3Z6dcn3PtQCHNrVCf
5TTre3V6POEMldO9nyhG+jrxtgYGxJ+cwYwuDcRlXRsdQaGMLmXuJJOqw3R0
GG5ad0us0hmqGeLNx8BQC2Dn9HnuAq+byFM5qHf56hRx9hiPkjcuQGzwG4eP
q7iIRt2SAbGIY.qY01+mIAlPup.p+RYZxpcubKrCS1ipyUI7Czp0qbsUalNN
FWQ502Gu5TzJaXAyAMlPKDFeB1x34JR9zxphQpEY5.H0J.9Km1yfwo93R3i7
Il8WyWEWNVdjyfS2Y+QlZSl+0gUgLfJ.uBMaWuX75yN1n4D.Z+XxxpgoU2bF
3eT8Vso5Um2F+zx7MwiQiwYISsOY2gX0OSEuvOGsXrLAtJte63b9Yo27KFzA
ZKgj.b0D4DZY+ma8dxz8IELmQ3PiwHBFpijjzoBI2Puf+uWOPgkthj2eI5kX
0F1vW7qqlf4zaIgdUTwGdWl5cS06zgKOMYzCN.2l2yzg2ylW2LcXQCfqIv0d
RIHMJD4M0Doo5HB8i43TN3b9z8BmxuUuwjC.06cd93QgFSwPNYpcAirfHmJm
btMLeUvodXwKVjFKstYpu32lm+gYCvXtuVFGcP+9mS8FKWR1GFGGx9TFy.JQ
f1GAubVjFxhbBBHZL5i0CwoqJwzo46pTD7gw3ix+qak4yZEzFdvrlnhgus93
xenyeslg2QLJN+88hXxGLwj8KpV64V6rTpxUhgcg9vbi.BI0sRPXHVvqOhKb
ntTrF6jzFcz6D17GdsN5SrlWAqNfSGPfa6kmE9cQ2fh30x6mYgF7FB2504jC
oEgfvTTXWikJM.dednyFgyj4ppno38GezIzZyEpdL6AqGcE8BvQc8dhqpqzg
ayhsegp5ZR2Z0SedOE.lcbpuMca7tWxpNG8OFxqKZ+dkQgdWETM.Vj+wrQCg
WGkjFH7e8yQiG.AnPpomB3bLFYj1PPo6b9G.+th33y.B0TulbpAYJ+a7Ov8C
RMaYUQiF7DD.iYx1GCHANMojEBCo9GF+uhWMZ3i230KrInJPsECeCe+Owoo4
eb7jPD0zRLb0F9rF.oRtR5P8SEMD.DSABf9ZDAzku36xSOCVjlDmPkdBQMcm
TaifdA.2rsXSZ7nbNk.L90fn.VnlGFInLjvQOz3MsWHARkpMz51TZO7pnYQ7
x3jWNck6rwyzDa1dfCztaE8CvYBQQwVLBJ+fLDVC2hH0CFVa+fW220RgfPuZ
IoLNaU4qMKH6Ix9W1yZSqB3P.2TqIBCDV2h6bnW4cph1LTmb2JCWeeTUdv2q
hBcl2F+xp3m1llVMXAVNrYNETJzjLWFliMM8NSJccpBdoVqKb8Wk0DTfJCBM
8YoWQpQiSHAWX7y.2vIiQg3PgGBU+FROZd2G9JY8B7QU1b973q0DPQszQchq
IRRg65ZSbh1t7OmTT84f+smyGJgvvvPfw6RIeLotj4L..C61Hu8ZMzwtiuKg
EyNOBqYoyoqfmBYK2TOEp2pce6e+s++PokcYY
-----------end_max5_patcher-----------

 The reasons it currently huffs a bit at scale are partly to do with implementation rather than the algorithm itself. Because there’s a lot of recursion, small inefficiencies can pile up quite quickly. The happy news is, of course, that it’s easy to tame those. However, I think the first priority has been on making expressive code that works.
The reasons it currently huffs a bit at scale are partly to do with implementation rather than the algorithm itself. Because there’s a lot of recursion, small inefficiencies can pile up quite quickly. The happy news is, of course, that it’s easy to tame those. However, I think the first priority has been on making expressive code that works.