So I want to (quickly) test a bunch of different descriptors and statistics to see what is working best for a given dataset, and wanted to leverage the oldschool fluid.processsegments and associated GUIs.
In looking at the patches, specifically -comparison, which @tremblap used in this week’s geekout, it struck me that this seems like a quite narrow/specific use case. Unless I’m missing something, there’s not a way to run a folder of individual (pre cut/sized) samples, without resegmenting them. Or rather, all of my files have a 20ms bit of padding at the start, so they can run through fluid.bufampslice~ to accurately recreate “realtime” onset detection on the same sounds. So in this case I can’t bypass the fluid.segmentcorpus abstraction entirely because the starts/ends of my files in the “big buffer” aren’t actually the start/ends of what I want to analyze.
Modifying the concatenation subpatch wouldn’t work here either (or without much grief) as it’s accum based and wants consecutive numbers rolling out.
So the first question is about that. Is there a reason why individual files are concatenated before analysis? If the files are already sliced/separated, it seems that it would be best to keep them that way, which also simplifies playback layer on with polybuffer~ etc…
This then also has knockon effects further down the abstraction chain as I can’t just generated my own dict with the start/end points I want because everything expects all the audio to come from a single giagantic buffer.
The next question is about this section here:
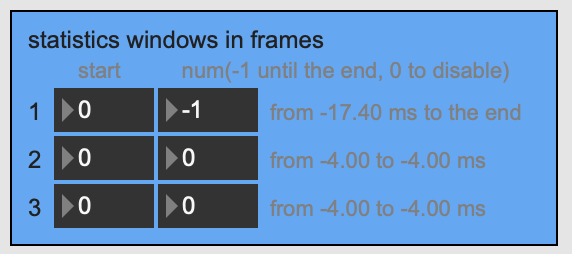
I remember having a…heated…discussion with @tremblap about this at the first or second plenary, but in revisiting this now, I actually have no idea what these numbers correspond to. I’m asked to set start and num windows in frames, but get feedback in ms, but those time frames also go negative (which isn’t “real” because there’s no negative time in any of the segments, or windowing that starts before the segment). I also have no idea what settings here correspond with settings that you can then use in any of the objects, or vice versa. In most of my analysis I’m using @fftsettings 256 64 256 so I end up with 7 frames of analysis, and for these purposes, I want all of them. I don’t know what I’m supposed to put in these boxes to get the same results.
So yeah, kind of a “bump” on these old patches and abstractions as they would come in handy right about now if I want to test a bunch of permutations of stuff, but the concatenation-based workflow here doesn’t work well for a bunch of individual files.


 I know because I tested the code above against the compiled version you have (I have 5 parallel versions on my mac for bespoke support between versions, I hope you appreciate the love and care )
I know because I tested the code above against the compiled version you have (I have 5 parallel versions on my mac for bespoke support between versions, I hope you appreciate the love and care )