Apologies for the clickbait-y title of the post I’m going to link but I found it really useful in learning more about how to curate your dimension reduction parameters and algorithm selection. I particularly found it useful as I was interrogating what I thought were a same number of components to reduce to.
@spluta and @rodrigo.constanzo , you seem to be heavily in this space right now with PCA big data sets to search through so perhaps you will find it especially useful!
I naively take 10% of my points as my lower limit and work upwards if its garbage. Today I’ve had great success going from 273 values to 1 though. The one dimension that all the samples sits on is muddy, but 0.1 versus 0.9 are two distinct points which is quite interesting.
Yes please I remember hearing about some rules of thumbs for DR that are dependent on how many vectors you have and how many samples per vector you’ve got too.
But by this, do you mean “listening” or whatever? Like a subjective measure of effectiveness, or is it getting x amount of clusters, or something numerical/“concrete” like that.
I’ve been wondering about this too, to see if/how DR stuff works on time series of events (based on all the recent AudioGuide discussions). Like, if instead of putting a statistical summary into a fluid.dataset~ and then reducing that down to x amount of dimension, putting every frame of the analysis into a fluid.dataset~, and seeing if it can/does somehow summarize change-over-time-ness, as a way of getting better morphological matches (in a kdtree context).
I audition the queries in Max using a dict object to load my outputs. I generally loop the samples and just iterate over the clusters to see homogenous they are.
Have people compared using PCA, LDA and ICA ? In my data world experience they do provide different results which is expected since they’re maximizing different things.
I’d be curious to see how this translates to audio but not sure if anything else is implemented in flucoma or max besides pca.
Going to start my experiments with this stuff soon, as I’m going to do some MFCC testing, and the dimensions required balloon up really fast.
I’ll read through the paper, and do some playing, but I’m curious/wondering how to retain a perceptually meaningful set of dimensions at the end? Like, loudness (and its related statistics) are probably more significant than a single MFCC band, but if I understand things correctly, they would both have the same amount of “weight” in any dimensionality reduction context.
what I plan to do when I have time to actually use the tools is to take the APT patch and to make a 1D redux of MFCC1-13 (12 to 1) and scale that into the same range (0-110) than my tolerance in dB and midifloats… but feel free to go there and share. I just noticed that this is in the wrong part of the forum so sorry @bafonso there are tools still not public… in early 2021, and if you want maybe a bit earlier when we get to beta of what is currently alpha…
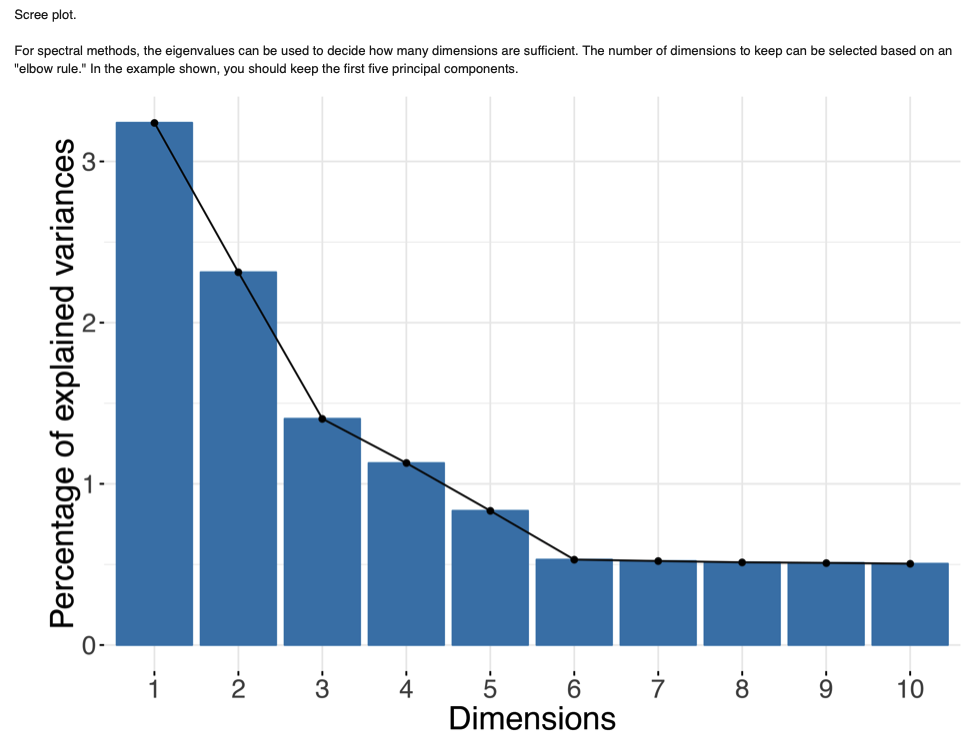

 I remember hearing about some rules of thumbs for DR that are dependent on how many vectors you have and how many samples per vector you’ve got too.
I remember hearing about some rules of thumbs for DR that are dependent on how many vectors you have and how many samples per vector you’ve got too.